






 本文介绍了随机森林算法,作为集成学习的一种,随机森林通过构建多个决策树并结合其结果来提高预测准确性。文章详细讲解了随机森林的定义、特点、生成步骤及优缺点,并通过sklearn库展示了随机森林在垃圾邮件分类中的应用。随机森林的主要优点包括并行性和高准确率。关键参数如`n_estimators`、`max_depth`、`max_features`等对模型性能有显著影响。
本文介绍了随机森林算法,作为集成学习的一种,随机森林通过构建多个决策树并结合其结果来提高预测准确性。文章详细讲解了随机森林的定义、特点、生成步骤及优缺点,并通过sklearn库展示了随机森林在垃圾邮件分类中的应用。随机森林的主要优点包括并行性和高准确率。关键参数如`n_estimators`、`max_depth`、`max_features`等对模型性能有显著影响。
集成学习
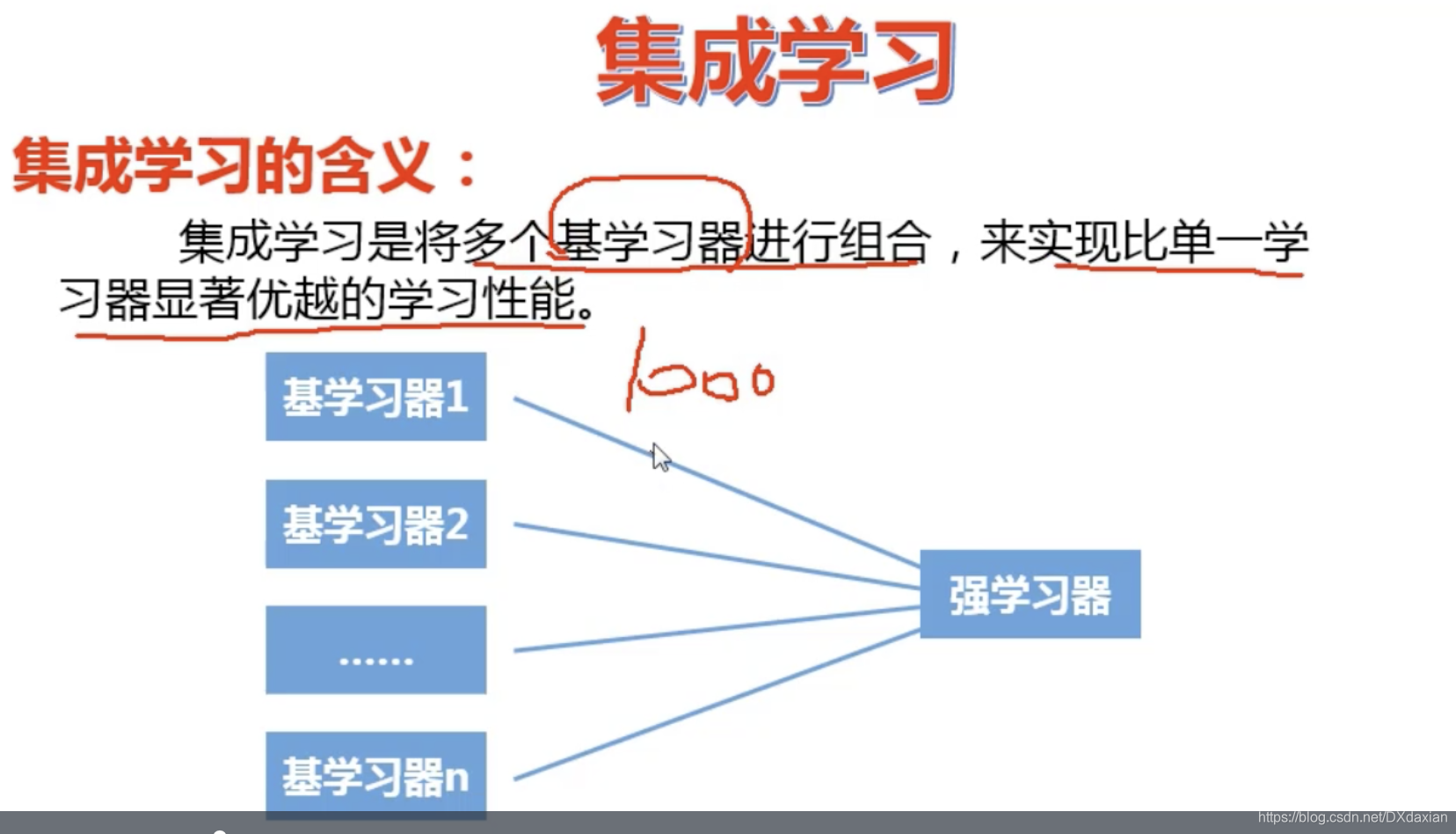
例子:单独使用一个基学习器,会因为有数据错误而做出错误判断。集成学习就是,对一个事情做出判断,基学习器1使用LR,2使用KNN,3使用SVM,4使用DT,最后共同判断,如果90%判断事情应该是a,10%认为是b,那么就判断事情符合a。实质:三个臭皮匠,顶个诸葛亮。

bagging:n个决策树在一起判断
boosting:
staking:n种学习器一起判断
bagging和boosting用的比较多

1、分类问题:典型的DT(决策树)
2、回归问题:n个学习器得到的结果求均值
3、特征选取集成:有n个特征,但特征并不是越多越好,需要选取比较重要的特征(a.根据业务常识判断,b.根据random forest随机森林选取)
随机森林算法原理
随机森林定义、特点、优点
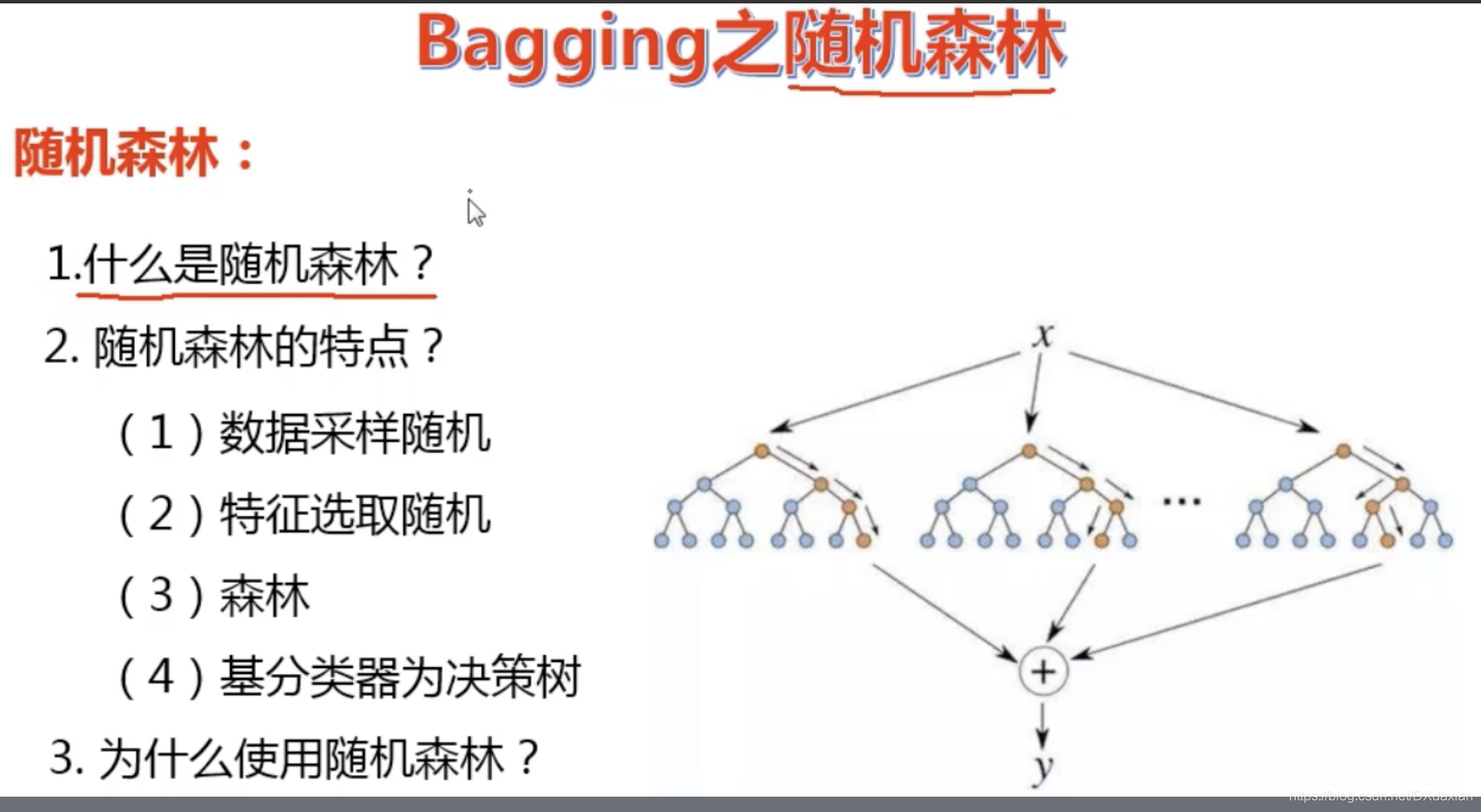
1、多个决策树放在一起就是随机森林:
a)分类问题:事件x,经过n个分类决策树(DT)判断,90%的结果认为x是0,10%认为是1,那么就认为这是1.
b)回归问题:事件x,经过n个回归决策树计算,得到n个函数,均值是结果
3、优点:并行、准确率高
随机森林生成步骤
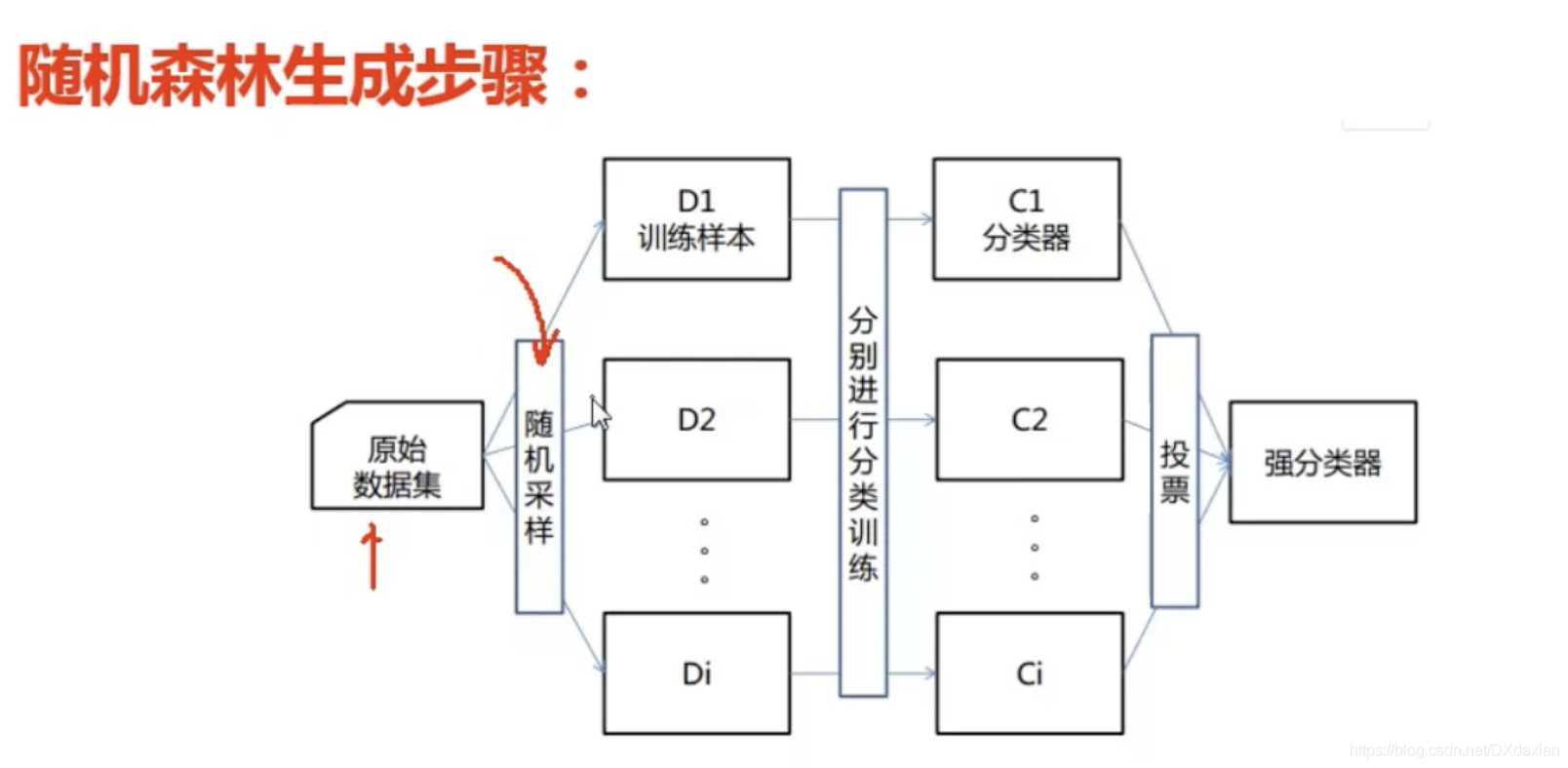
每次从原始数据集中随机选取n%的训练数据,在训练时再随机选取m%的特征。
随机森林优缺点介绍
优点

缺点

代码实战
随机森林算法API文档解释
class sklearn.ensemble.RandomForestClassifier(n_estimators=’warn’, criterion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)
随机森林重要的一些参数:
1.n_estimators :(随机森林独有)
随机森林中决策树的个数。
在0.20版本中默认是10个决策树;
在0.22版本中默认是100个决策树;
一般给100-500个
2. criterion :(同决策树)
节点分割依据,默认为基尼系数。
可选【entropy:信息增益】
3.max_depth:(同决策树)【重要】
default=(None)设置决策树的最大深度,默认为None。
【(1)数据少或者特征少的时候,可以不用管这个参数,按照默认的不限制生长即可
(2)如果数据比较多特征也比较多的情况下,可以限制这个参数,范围在10~100之间比较好】m
4.min_samples_split : (同决策树)【重要】
这个值限制了子树继续划分的条件,如果某节点的样本数少于设定值,则不会再继续分裂。默认是2.如果样吗本量不大,不需要管这个值。如果样本量数量级非常大,则建议增大这个值。
5.min_samples_leaf :(同决策树)【重要】
这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
【叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。】
【比如,设定为50,此时,上一个节点(100个样本)进行分裂,分裂为两个节点,其中一个节点的样本数小于50个,那么这两个节点都会被剪枝】
6.min_weight_fraction_leaf : (同决策树)
这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。【一般不需要注意】
7.max_features : (随机森林独有)【重要】
随机森林允许单个决策树使用特征的最大数量。选择最适属性时划分的特征不能超过此值。
当为整数时,即最大特征数;当为小数时,训练集特征数*小数;
if “auto”, then max_features=sqrt(n_features).
If “sqrt”, thenmax_features=sqrt(n_features).
If “log2”, thenmax_features=log2(n_features).
If None, then max_features=n_features.
【增加max_features一般能提高模型的性能,因为在每个节点上,我们有更多的选择可以考虑。 然而,这未必完全是对的,因为它降低了单个树的多样性,而这正是随机森林独特的优点。 但是,可以肯定,你通过增加max_features会降低算法的速度。 因此,你需要适当的平衡和选择最佳max_features。】
8.max_leaf_nodes:(同决策树)
通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
【比如,一颗决策树,如果不加限制的话,可以分裂100个叶子节点,如果设置此参数等于50,那么最多可以分裂50个叶子节点】
9.min_impurity_split:(同决策树)
这个值限制了决策树的增长,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。一般不推荐改动默认值1e-7。
10.bootstrap=True(随机森林独有)
是否有放回的采样,按默认,有放回采样
- n_jobs=1:
并行job个数。这个在ensemble算法中非常重要,尤其是bagging(而非boosting,因为boosting的每次迭代之间有影响,所以很难进行并行化),因为可以并行从而提高性能。1=不并行;
n:n个并行;
-1:CPU有多少core,就启动多少job。
垃圾邮件分类
"""
随机森林
此数据库包含有关4597条电子邮件的信息.任务是确定给定的电子邮件是否是垃圾
邮件(类别1),取决于其内容。
大多数属性表明某个特定的单词或字符是否经常出现在电子邮件中。
以下是属性的定义:
-48个连续的实属性,类型为word_freq_“word”=与“word”匹配的电子邮件中单词的百分比。
在这种情况下,“Word”是由非字母数字字符或字符串结尾的任何字母数字字符组成的字符串。
-6个连续的实属性char_freq_“char”=与“char”匹配的电子邮件中字符的百分比。
-1连续实属性类型:Capital_Run_Length_Average=不间断大写字母序列的平均长度。
-1连续整数属性,类型为Capital_Run_Length=最长不间断大写字母序列的长度。
-1连续整数属性,类型为Capital_Run_Length_Total=电子邮件中大写字母的总数。
"""
import pandas as pd
#可视化混淆矩阵
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
'''
数据读取和划分
'''
df = pd.read_csv(r'/Users/dx/Desktop/Python数据分析与机器学习/10.集成学习之随机森林/随机森林课程资料/spambase.csv')
from sklearn.model_selection import train_test_split
x = df.iloc[:,:-1]
y = df.iloc[:,-1]
x_train, x_test, y_train, y_test = \
train_test_split(x, y, test_size = 0.2,random_state = 100 )
'''
实例化模型
n_estimators:决策树的个数
max_features:特征的个数
此处可以根据需要设置每棵决策树的深度以及最小叶子节点的样本数等
'''
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators = 100,
max_features = 0.8,
random_state = 0
)
rf.fit(x_train, y_train)
#预测训练集结果
train_predicted = rf.predict(x_train)
#绘制混淆矩阵
from sklearn import metrics
print(metrics.classification_report(y_train, train_predicted))
cm_plot(y_train, train_predicted).show()
#recall = 1
#测试集预测
test_predicted = rf.predict(x_test)
print(metrics.classification_report(y_test, test_predicted))
cm_plot(y_test, test_predicted).show()#如果有多个图不使用show()会让多个图绘制在一起
# recall= 0.92 结果还可以,略微过拟合
'''
绘制中文重要程度排名
'''
import matplotlib.pyplot as plt
from pylab import mpl
importance = rf.feature_importances_
im = pd.DataFrame(importance)
clos = df.columns.values.tolist()#把列标签转化为列表值
clos = clos[0:-1]#去掉最后一个labels
im['clos'] = clos #把clos加到im中作为一列
#按值大小排序,并取前15行(前15行的值比较大,特征重要性比较大)
im = im.sort_values(by = [0], ascending = False)[:12]
#设置中文字体
mpl.rcParams['font.sans-serif'] = ['SimHei']
#解决保存图像是负号'-'显示为方块的问题
mpl.rcParams['axes.unicode_minus'] = False
index = range(len(im))
plt.yticks(index, im.clos)
plt.barh(index, im[0])

















 610
610



 到【灌水乐园】发言
到【灌水乐园】发言







