









目录
一、K-最近邻(K-Nearest Neighbors, KNN)算法详解
二、OpenCV 中的 cv2.ml.KNearest_create() 函数
1. train(samples, layout, responses)
引入
cv2.ml.KNearest_create() 是 OpenCV 中机器学习模块(cv2.ml)提供的一个用于创建 K-最近邻(K-Nearest Neighbors, KNN)分类器 实例的方法。该方法返回的是一个 cv2.ml_KNearest 类的对象,用户可以通过该对象进行模型的训练、预测等操作。下面将从基本概念、函数用途、使用方法、参数、返回值、相关方法等方面进行详细介绍,风格类似教科书内容。
一、K-最近邻(K-Nearest Neighbors, KNN)算法详解
一、📌 什么是 KNN?
K-最近邻(K-Nearest Neighbors, KNN) 是一种基本的、监督式分类和回归算法。
它的核心思想是:
“看你周围最相似的 K 个邻居属于什么类别,你也就属于那个类别。”
特点:
-
懒惰学习(Lazy Learning):没有训练过程,只是存储训练数据。
-
非参数模型(Non-parametric):不做任何关于数据分布的假设。
二、🧠 工作原理(分类任务)
KNN 的分类流程如下:
-
准备训练数据集(每个样本有特征和标签)。
-
给定一个待分类的测试样本。
-
计算该样本与所有训练样本之间的距离。
-
选出距离最近的 K 个训练样本。
-
统计 K 个邻居所属的类别。
-
投票决定测试样本的类别。
三、📏 距离度量方式
KNN 的核心是计算“相似度”,通常使用距离度量:
✅ 欧几里得距离(最常用):
对于两个向量 和
✅ 曼哈顿距离(绝对距离):
✅ 闵可夫斯基距离(欧氏和曼哈顿的推广):
常用 (曼哈顿),
(欧氏)。
四、🔢 参数 K 的选择
-
K 值太小:容易受噪声干扰,模型复杂,过拟合。
-
K 值太大:会包含太多不相关的样本,导致欠拟合。
通常选法:
-
使用交叉验证选择最优 K 值。
-
常见取值:3、5、7,依赖实际数据。
五、⚙️ 算法实现步骤(伪代码)
Input: 训练集 D,测试样本 x,参数 K
Output: x 的预测类别
1. 对于训练集中的每个样本 xi:
计算 d(x, xi) ← 测试样本与 xi 的距离
2. 将训练样本按照 d 值升序排列
3. 取前 K 个样本作为邻居
4. 统计这 K 个邻居中每个类别出现的频率
5. 返回出现频率最高的类别作为预测结果
六、🎯 应用场景
-
图像识别(手写数字识别)
-
文本分类
-
医学诊断(如肿瘤良恶性判断)
-
推荐系统(用户相似度)
七、🏋️♂️ 优点 vs 缺点
| 优点 | 缺点 |
|---|---|
| 实现简单、直观 | 存储和计算代价高(需要保存全部训练数据) |
| 适用于多分类问题 | 对不均衡数据敏感 |
| 无需模型训练,灵活 | 维数灾难:维度越高效果越差 |
八、🔬 数学本质(从模式识别角度)
KNN 是一个基于局部邻域一致性假设的算法。即:
“如果一个样本在特征空间中的 K 个最近邻大多数属于某一类别,那么该样本也属于这个类别。”
这其实是一种 基于投票的密度估计法,也可看作是非参数化的核方法的一种简化形式。
九、🧮 扩展:KNN 回归
KNN 也可用于回归问题:
-
不再是“投票决定类别”,而是“取 K 个邻居的平均值”。
公式如下:
其中 是 K 个最近邻的实际值。
✅ 总结一句话:
KNN 是一种没有模型的“以邻为师”的方法,它简单有效,适合小规模数据,但在大数据和高维度上会面临性能瓶颈。
二、OpenCV 中的 cv2.ml.KNearest_create() 函数
1. 函数原型
cv2.ml.KNearest_create() -> retval
2. 功能说明
该函数用于创建一个 K-最近邻分类器(KNearest)对象的实例,返回一个可供后续调用的 cv2.ml_KNearest 类对象。通过该对象,可以执行如下操作:
-
train():训练模型。 -
findNearest():进行最近邻查询与预测。 -
load()/save():模型的加载与保存。
3. 返回值
返回一个 cv2.ml_KNearest 类型的对象实例。例如:
knn = cv2.ml.KNearest_create()
三、cv2.ml_KNearest 对象的常用方法
以下是通过 cv2.ml.KNearest_create() 创建的对象所支持的常用方法:
1. train(samples, layout, responses)
训练模型。
-
samples:训练样本数据,类型为np.float32的二维矩阵,每一行表示一个样本。 -
layout:数据布局类型,常为cv2.ml.ROW_SAMPLE。 -
responses:每个样本的标签,类型为np.float32的列向量或一维数组。
例:
knn.train(train_data, cv2.ml.ROW_SAMPLE, train_labels)
2. findNearest(samples, k)
使用 KNN 方法对新数据进行预测。
-
samples:待分类数据,类型为np.float32的二维矩阵。 -
k:使用的最近邻个数。 -
返回:预测标签、最近邻的响应值、距离等。
例:
ret, result, neighbours, dist = knn.findNearest(test_data, k=3)
返回内容解释:
-
ret:主要预测结果(通常等于result[0])。 -
result:预测结果数组。 -
neighbours:K 个最近邻的标签。 -
dist:K 个最近邻的距离。
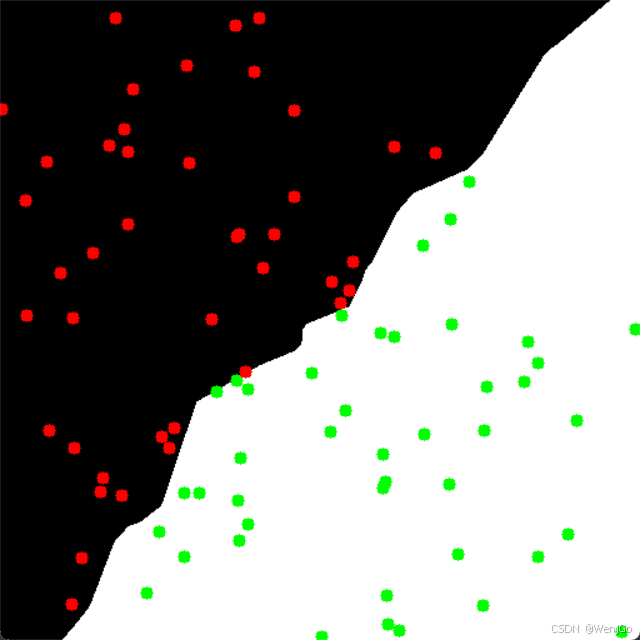
四、示例代码
-
整个图像背景会被染成两类颜色,显示出模型的“决策边界”。
-
点密集分布在边界两侧,表示训练数据的聚类效果。
-
点击图像时,分类器将会返回点击位置所属的类别,并标记颜色。
import numpy as np
import cv2
# 设置随机种子
np.random.seed(42)
# 创建两类训练数据
class0 = np.random.randint(0, 256, (25, 2)).astype(np.float32)
class1 = np.random.randint(256, 512, (25, 2)).astype(np.float32)
train_data = np.vstack((class0, class1))
labels = np.vstack((np.zeros((25, 1), dtype=np.float32), np.ones((25, 1), dtype=np.float32)))
# 创建 KNN 模型并训练
knn = cv2.ml.KNearest_create()
knn.train(train_data, cv2.ml.ROW_SAMPLE, labels)
# 创建画布并绘制分类边界
canvas = np.zeros((512, 512, 3), dtype=np.uint8)
# 分类边界可视化
for y in range(0, 512):
for x in range(0, 512):
sample = np.array([[x, y]], dtype=np.float32)
ret, result, neighbours, dist = knn.findNearest(sample, k=3)
if result[0][0] == 0:
canvas[y, x] = (0, 0, 0) # 红色区域
else:
canvas[y, x] = (255, 255, 255) # 绿色区域
# 绘制原始样本点
for pt in class0:
cv2.circle(canvas, (int(pt[0]), int(pt[1])), 5, (0, 0, 255), -1)
for pt in class1:
cv2.circle(canvas, (int(pt[0]), int(pt[1])), 5, (0, 255, 0), -1)
# 鼠标点击预测函数
def on_mouse(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
sample = np.array([[x, y]], dtype=np.float32)
ret, result, neighbours, dist = knn.findNearest(sample, k=3)
print(f"点击 ({x}, {y}) → 预测类别: {int(result[0][0])}")
color = (0, 0, 255) if result[0][0] == 0 else (0, 255, 0)
cv2.circle(canvas, (x, y), 5, color, -1)
# 展示窗口
cv2.namedWindow("KNN 分类边界")
cv2.setMouseCallback("KNN 分类边界", on_mouse)
while True:
cv2.imshow("KNN 分类边界", canvas)
if cv2.waitKey(1) & 0xFF == 27: # 按 ESC 退出
break
cv2.destroyAllWindows()
五、注意事项
-
输入数据必须为
np.float32类型,否则训练或预测时将报错。 -
K值应根据实际应用场景进行调整,过大或过小都会影响预测准确性。 -
由于 KNN 是惰性学习算法,训练过程简单但预测开销大,不适合大规模数据实时处理。
-
所有输入数据(包括标签)应进行预处理(如归一化)以提升性能。
六、相关API
| 函数 | 说明 |
|---|---|
cv2.ml.TrainData_create() | 构建训练数据的辅助工具 |
cv2.ml.KNearest_load(filename) | 从文件加载已有的 KNN 模型 |
model.save(filename) | 保存模型到文件 |
model.clear() | 清除模型内容 |
七、总结
cv2.ml.KNearest_create() 是 OpenCV 提供的用于机器学习中 K-最近邻分类任务的创建函数。通过该函数,用户可以灵活构建 KNN 分类器,执行训练、预测等操作。其实现基于 OpenCV 的机器学习模块,封装良好、使用方便,适合中小型分类问题的入门学习和应用开发。


















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











