 PolarDB的共享存储读写分离技术:优势与挑战
PolarDB的共享存储读写分离技术:优势与挑战





 本文探讨了阿里巴巴的PolarDB数据库如何利用共享存储实现读写分离,与传统数据库复制技术不同,它通过WAL重演机制保证一致性。然而,该方法存在数据同步问题和对RDBMS改造的要求,影响了性能和某些特定场景的适用性。
本文探讨了阿里巴巴的PolarDB数据库如何利用共享存储实现读写分离,与传统数据库复制技术不同,它通过WAL重演机制保证一致性。然而,该方法存在数据同步问题和对RDBMS改造的要求,影响了性能和某些特定场景的适用性。
Polardb是阿里这两年宣传的比较多的数据库产品。在阿里云上有RDS FOR POLARDB的产品,分为-X、-O和-PG三个引擎。虽然阿里没有怎么宣传这三种引擎的来源,不过根据其使用特性来看,-X是基于Mysql引擎的,-O、-PG是PostgreSQL引擎的。-O主打与Oracle语法的兼容性,-PG基本上和社区版PostgreSQL的语法完全兼容。目前PolarDB也提供线下的版本,可以脱离阿里云独立部署。部署架构如下:
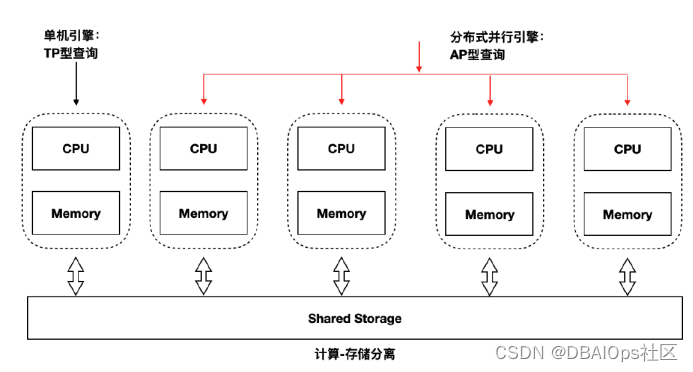
PolarDB是采用计算存储分离的模式,有点类似与Oracle的ASM,不过PolarDB的底层存储是自己的分布式文件系统PolarFS,计算节点与PolarFS分布式存储之间通过RDMA高速互联。今天我们关注的重点不是PolarDB的基础架构与基本原理,而是重点讨论一个PolarDB的比较有趣的功能,基于共享存储的读写分离技术。
现在很多开源与国产的数据库产品支持读写分离,不过这些数据库一般都是采用数据库复制技术来实现的,而PolarDB采用了一条特殊的技术路线,使用共享存储的读写分离技术,这个路线和十年前Sybase的共享存储集群技术类似。读写实例与只读实例共享同一套数据库文件,整个集群中只有一个读写实例,其他都是只读实例。如上图,左侧是一个独立的可读写的实例,右侧的几个只读实例组成一个共享存储的并行数据库集群。一个大型查询可以分布在多个实力上并行执行,从而满足一些HTAP类的应用需求。具体这个并行只读引擎的效果如何,没有测试过,并不清楚,从阿里自己宣传的资料来看效果还是不错的。
采用这种共享存储模式的读写分离数据库方案,我们常见的通过数据同步/准同步复制实现的读写分离还是有一定的优势的,那就是数据不需要复制,因此一切与数据复制相关的读写分离方案的缺陷都可以避免。不过这种方式也存在一定的问题,那就是必须对RDBMS的核心进行一定的改造,并且读写实例与只读实例之间仍然存在一定的串行化同步的问题,或多或少主实例还是会受到一些只读实例的影
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









