




数据库并发依靠闩锁(Latch、Spinlock、Rwlock、LWLock等最终的机制原理都十分相近,我们就取Oracle的Latch来做此类锁的统称)和队列锁机制来实现必要的串行化。串行化是为了一致性访问某个资源所必须承受的并发环境下的代价。队列锁最为典型的就是行锁表锁等应用级的锁,不在我们今天讨论的范围内,今天我们重点讨论的是闩锁。闩锁的目的是为了一致性访问数据库内存中的共享内存结构,避免内存结构因为不一致的读写而导致混乱。不管是核心态的数据还是用户态的共享内存,都需要通过串行化控制来保证其一致性的读写。为了确保这种一致性,这些串行化的控制都需要至少一次全局串行化来达到最终的目的。这个全局串行化,一般来说就是使用的是和CPU直接相关的原子操作,自旋锁SPINLOCK。
前阵子我发过一个关于闩锁与SPINLOCK的帖子,其中简单的提到了CPU的PAUSE指令对SPINLOCK的影响。当自旋锁无法获得SPINLOCK的时候,已经占用了CPU的线程没必要放弃CPU进入休眠,等待再次尝试获得SPINLOCK,因此会在该CPU上自旋。不过对于争用比较严重的系统,自旋多次后,有可能仍然无法获得SPINLOCK。因为自旋时该线程需要持有CPU的串行锁,因此,对于具有多个线程(比如至强芯片是双线程的)的CPU来说,这种长时间自旋而无法获得SPINLOCK的情况会导致另外一个CPU线程也被锁死,无法执行。为了解决这个问题,LINUX针对SPINLOCK的算法做了一些优化。
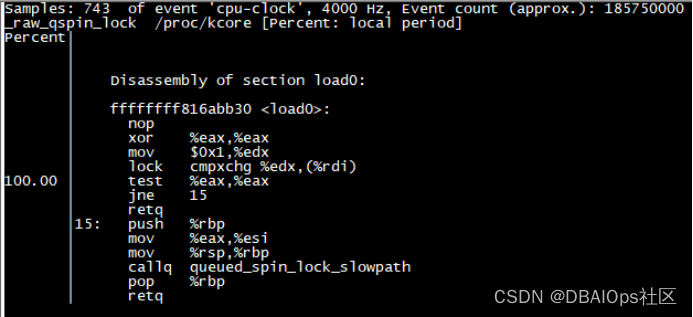
上面是通过perf工具跟踪的结果,我们可以看到_raw_qspin_lock首先通过lock cmpxchg来获得spinlock,如果当前SPINLOCK无人持有,则直接获得SPINLOCK并返回,否则就调用queued_spin_lock_slowpath来继续自旋。今天篇幅有限,我们不讨论详细的细节。直接看queued_spin_lock_slowpath的汇编代码。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2002
2002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









