






目录标题
PolarDB for PostgreSQL 核心技术详解
基于官方文档和开源代码的技术实现分析
一、架构概览
1.1 共享存储架构(Shared-Storage)
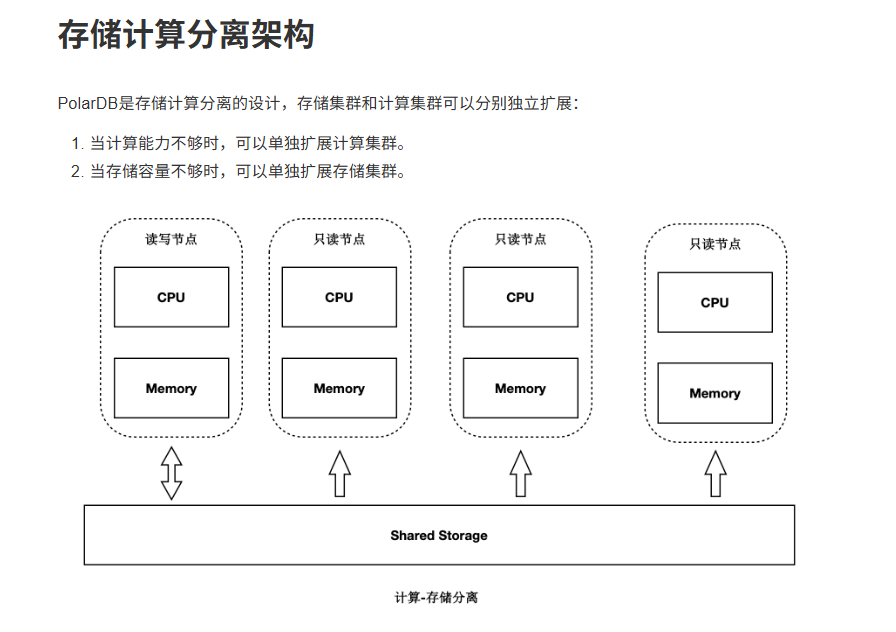
PolarDB for PostgreSQL 采用计算存储分离的架构设计:
传统架构: N份计算 + N份存储
PolarDB: N份计算 + 1份存储(共享)
核心优势:
- 一份数据,多个计算节点共享访问
- 显著降低存储成本(从 N 份到 1 份)
- RW 节点和 RO 节点访问同一份存储数据
- 实现 RPO=0 的数据一致性保证
存算分离
1.2 节点角色
┌─────────────┐
│ RW 节点 │ (读写节点,Primary)
│ (Leader) │
└──────┬──────┘
│
│ WAL Meta (仅元数据)
↓
┌──────────────────────────────────┐
│ 共享存储层 (Shared Storage) │
│ ┌──────────┬────────┬──────┐ │
│ │ 数据文件 │ WAL 日志 │索引 │ │
│ └──────────┴────────┴──────┘ │
└──────────────────────────────────┘
↑ ↑ ↑
│ │ │
┌───┴──┐ ┌──┴───┐ ┌──┴───┐
│ RO 1 │ │ RO 2 │ │ RO N │
└──────┘ └──────┘ └──────┘
(只读节点,Standby/Follower)
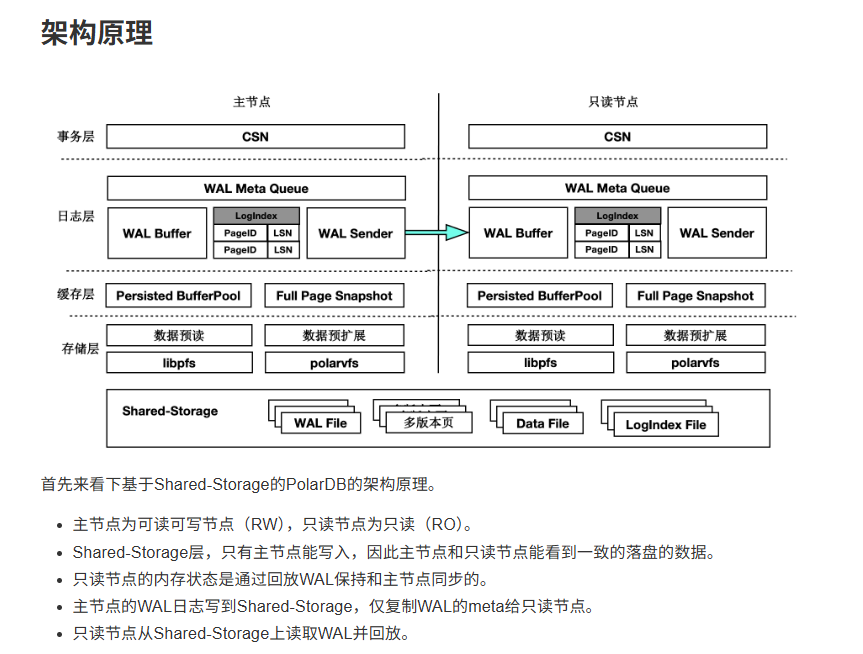
二、LogIndex 技术详解
2.1 问题背景
传统 PostgreSQL 主从复制存在的问题:
- 完整 WAL 传输:主节点需要将完整的 WAL 日志传输给所有从节点
- 顺序回放瓶颈:从节点必须按顺序回放 WAL,无法并行
- 网络带宽消耗:大量 WAL 日志传输占用网络资源
- 复制延迟:回放速度慢导致主从延迟增大
2.2 LogIndex 核心原理
2.2.1 数据结构
LogIndex 本质是一个可持久化的 Hash 表:
// 伪代码表示
struct LogIndex {
Key: PageID // 数据页标识符
Value: List<LSN> // 修改该页的所有 LSN 列表
}
// 示例
LogIndex[PageID_1001] = [LSN_100, LSN_235, LSN_567, LSN_890]
LogIndex[PageID_2048] = [LSN_120, LSN_340]
关键字段:
- PageID: 数据页的唯一标识(通常是 RelFileNode + BlockNumber)
- LSN (Log Sequence Number): WAL 日志的序列号
- LSN 列表: 按时间顺序记录所有修改该页面的 WAL 记录位置
2.2.2 工作流程
在 RW 节点:
1. 生成 WAL 记录 → 写入共享存储
2. 提取 WAL Meta (元数据):
- LSN
- PageID
- 操作类型
3. 将 WAL Meta 发送给所有 RO 节点
在 RO 节点:
1. 接收 WAL Meta
2. 构建 LogIndex:
LogIndex[PageID].append(LSN)
3. 推进回放位点(不立即回放)
4. 等待查询请求触发实际回放
2.3 关键技术优势
优势 1: 网络传输量大幅减少
传统方式:
WAL 记录大小: 平均 100-500 字节
传输内容: 完整的 WAL 数据
LogIndex 方式:
WAL Meta 大小: 约 20-30 字节
传输内容: 仅 LSN + PageID + 操作类型
减少比例: 98% 的网络流量减少
实测数据(来自官方文档):
- 网络传输量减少 98%
- RO 节点延迟降低到 毫秒级
优势 2: 按需回放(Lazy Replay)
传统方式的问题:
主节点写入 10000 个页面
从节点必须回放 10000 个页面的 WAL
即使从节点只需要查询其中 10 个页面
LogIndex 的 Lazy Replay:
主节点写入 10000 个页面
从节点只构建 LogIndex(轻量级)
查询请求访问 Page_100 时:
1. 从共享存储读取旧版本 Page_100
2. 查询 LogIndex[Page_100] = [LSN_1, LSN_5, LSN_9]
3. 仅回放这 3 条 WAL 记录
4. 返回最新版本的 Page_100
三、Lazy Replay(延迟回放)详解
3.1 实现原理
┌─────────────────────────────────────────────────┐
│ RO 节点回放流程 │
└─────────────────────────────────────────────────┘
阶段 1: 接收 WAL Meta
RW ──[WAL Meta]──> RO
│
↓
构建 LogIndex
(不回放数据)
阶段 2: 查询触发回放
查询: SELECT * FROM table WHERE id = 100;
│
↓
需要读取 Page_500
│
↓
检查 Buffer Pool ──[Miss]──> 触发回放
│
↓
从共享存储读取 Page_500 (旧版本)
│
↓
查询 LogIndex[Page_500] → [LSN_10, LSN_25, LSN_40]
│
↓
从共享存储读取这 3 条 WAL 记录
│
↓
依次回放到 Page_500
│
↓
得到最新版本的 Page_500
│
↓
返回查询结果
3.2 核心代码逻辑(伪代码)
// RO 节点处理查询请求
Page* read_page_on_ro_node(PageID page_id, LSN target_lsn) {
// 1. 尝试从 Buffer Pool 获取
Page* page = get_from_buffer_pool(page_id);
if (page != NULL && page->lsn >= target_lsn) {
// 页面已经是最新版本
return page;
}
// 2. 从共享存储读取基础页面
page = read_from_shared_storage(page_id);
LSN current_lsn = page->lsn;
// 3. 查询 LogIndex 获取需要回放的 WAL
List<LSN> wal_list = logindex_get(page_id, current_lsn, target_lsn);
// 4. 按顺序回放 WAL
foreach (LSN wal_lsn in wal_list) {
WALRecord* wal = read_wal_from_shared_storage(wal_lsn);
apply_wal_to_page(page, wal);
}
// 5. 更新页面 LSN
page->lsn = target_lsn;
// 6. 放入 Buffer Pool
add_to_buffer_pool(page_id, page);
return page;
}
3.3 优化效果
场景分析:
数据库: 1TB 数据,包含 1 亿个数据页
RW 节点: 1 小时内修改了 100 万个页面
RO 节点查询: 只访问其中 1000 个热点页面
传统回放:
- 必须回放 100 万个页面的 WAL
- 耗时: 数分钟到数十分钟
- 延迟: 高
Lazy Replay:
- 只回放 1000 个页面的 WAL
- 耗时: 毫秒级
- 延迟: 极低
四、Parallel Replay(并行回放)详解
4.1 并行回放框架
PolarDB 引入了并行任务执行框架来实现 WAL 的并行回放:
┌───────────────────────────────────────────────────────┐
│ Parallel Replay 架构 │
└───────────────────────────────────────────────────────┘
┌──────────────────┐
│ Startup Process │
│ (WAL 解析) │
└────────┬─────────┘
│
│ 解析 WAL
↓
┌──────────────────┐
│ LogIndex Builder │
│ (构建 LogIndex) │
└────────┬─────────┘
│
│ 生成 LogIndex
↓
┌─────────────────────────────────────┐
│ LogIndex BG Writer (调度器) │
│ - 分析依赖关系 │
│ - 生成回放子任务 │
│ - 分发任务到 Worker Pool │
└─────┬──────────┬──────────┬─────────┘
│ │ │
┌──────────┘ │ └──────────┐
↓ ↓ ↓
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Worker 1│ │ Worker 2│ │ Worker N│
│(并行回放) │ │(并行回放) │ │(并行回放) │
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
└────────────────────┴────────────────────┘
│
↓
┌─────────────────┐
│ Shared Memory │
│ (环形队列) │
│ - 任务状态管理 │
│ - 依赖关系跟踪 │
└─────────────────┘
4.2 核心组件
4.2.1 Startup Process(启动进程)
职责:
- 解析 WAL 日志流
- 构建 LogIndex 数据结构
- 不实际回放 WAL(这是关键)
代码逻辑(伪代码):
void startup_process() {
while (has_more_wal()) {
WALRecord* wal = read_next_wal();
// 解析 WAL 获取元数据
PageID page_id = extract_page_id(wal);
LSN lsn = wal->lsn;
// 插入 LogIndex
logindex_insert(page_id, lsn);
// 推进回放位点(但不回放)
advance_replay_position(lsn);
}
}
4.2.2 LogIndex BG Writer(后台调度器)
职责:
- 作为并行回放框架的调度器
- 分析 WAL 记录之间的依赖关系
- 生成可并行执行的回放子任务
- 分发任务到 Worker Pool
依赖分析示例:
WAL 记录序列:
WAL_1: 修改 Page_100
WAL_2: 修改 Page_200
WAL_3: 修改 Page_100
WAL_4: 修改 Page_300
依赖关系分析:
- WAL_1 和 WAL_2 无依赖 → 可并行
- WAL_1 和 WAL_3 有依赖 (同一页面) → 必须顺序
- WAL_2 和 WAL_4 无依赖 → 可并行
生成任务组:
TaskGroup_1: [WAL_1, WAL_2, WAL_4] # 可并行执行
TaskGroup_2: [WAL_3] # 依赖 WAL_1 完成后执行
代码逻辑(伪代码):
void logindex_bg_writer() {
while (true) {
// 1. 从 LogIndex 获取待回放的页面
List<PageID> pages = get_dirty_pages_from_logindex();
// 2. 分析依赖关系,生成任务
List<ReplayTask> tasks;
foreach (PageID page_id in pages) {
LSN min_lsn = get_last_replay_lsn(page_id);
LSN max_lsn = get_current_wal_lsn();
ReplayTask task = {
.page_id = page_id,
.lsn_range = [min_lsn, max_lsn],
.dependencies = calculate_dependencies(page_id)
};
tasks.add(task);
}
// 3. 分发任务到 Worker Pool
foreach (ReplayTask task in tasks) {
if (task.dependencies_satisfied()) {
assign_to_worker(task);
} else {
enqueue_pending_task(task);
}
}
sleep(REPLAY_INTERVAL);
}
}
4.2.3 Parallel Worker(并行工作进程)
职责:
- 执行回放子任务
- 回放单个数据页的 WAL 记录
- 更新任务状态
代码逻辑(伪代码):
void parallel_worker() {
while (true) {
// 1. 从队列获取任务
ReplayTask task = dequeue_task();
if (task == NULL) {
sleep(WORKER_SLEEP_INTERVAL);
continue;
}
// 2. 标记任务为运行中
mark_task_running(task);
// 3. 执行回放
Page* page = read_page_from_shared_storage(task.page_id);
List<LSN> wal_list = logindex_get(task.page_id, task.lsn_range);
foreach (LSN lsn in wal_list) {
WALRecord* wal = read_wal_from_shared_storage(lsn);
apply_wal_to_page(page, wal);
}
// 4. 写回页面(如果需要)
write_page_to_buffer(task.page_id, page);
// 5. 标记任务完成
mark_task_finished(task);
// 6. 触发依赖任务
trigger_dependent_tasks(task);
}
}
4.2.4 Backend Process(前端进程)
职责:
- 处理用户查询请求
- 访问数据页时触发 Lazy Replay
- 与 Worker 协同回放
代码逻辑(伪代码):
void backend_process_query(Query* query) {
// 解析查询需要的页面
List<PageID> required_pages = parse_query(query);
foreach (PageID page_id in required_pages) {
Page* page = get_page_for_query(page_id);
// ... 执行查询逻辑
}
}
Page* get_page_for_query(PageID page_id) {
// 1. 检查 Buffer Pool
Page* page = buffer_pool_lookup(page_id);
if (page != NULL && page->lsn >= current_replay_lsn) {
return page;
}
// 2. 触发 Lazy Replay
page = read_page_from_shared_storage(page_id);
// 3. 查询 LogIndex,回放所需的 WAL
List<LSN> wal_list = logindex_get(page_id);
foreach (LSN lsn in wal_list) {
WALRecord* wal = read_wal_from_shared_storage(lsn);
apply_wal_to_page(page, wal);
}
// 4. 放入 Buffer Pool
buffer_pool_insert(page_id, page);
return page;
}
4.3 共享内存与任务队列
环形队列设计:
// 共享内存结构
struct SharedMemory {
int num_workers; // Worker 进程数量
CircularQueue* queues; // 每个 Worker 一个队列
};
struct CircularQueue {
int depth; // 队列深度(可配置)
TaskNode* nodes; // 任务节点数组
};
// 任务节点状态
enum TaskState {
IDLE, // 空闲
RUNNING, // 运行中
HOLD, // 等待依赖
FINISHED, // 已完成
REMOVED // 已移除
};
struct TaskNode {
TaskState state;
PageID page_id;
LSN min_lsn;
LSN max_lsn;
List<TaskNode*> dependencies; // 依赖的其他任务
};
任务状态转换:
IDLE → RUNNING → FINISHED → REMOVED
↓
HOLD (等待依赖) → RUNNING
4.4 并行回放性能优化
优化 1: 依赖分析优化
// 快速判断两个 WAL 是否可以并行
bool can_parallel(WALRecord* wal1, WALRecord* wal2) {
// 不同页面 → 可并行
if (wal1->page_id != wal2->page_id) {
return true;
}
// 相同页面 → 不可并行(必须顺序回放)
return false;
}
优化 2: 批量任务调度
// 批量分发任务,减少锁竞争
void batch_assign_tasks(List<ReplayTask> tasks) {
// 按 Worker 分组
Map<WorkerID, List<ReplayTask>> grouped_tasks;
foreach (ReplayTask task in tasks) {
WorkerID worker = select_worker(task);
grouped_tasks[worker].add(task);
}
// 批量提交到各个 Worker
foreach (WorkerID worker, List<ReplayTask> worker_tasks in grouped_tasks) {
worker_queue_batch_push(worker, worker_tasks);
}
}
优化 3: 自适应并发度
// 根据系统负载调整 Worker 数量
void adjust_worker_count() {
int current_workers = get_active_worker_count();
int pending_tasks = get_pending_task_count();
int cpu_usage = get_cpu_usage();
if (pending_tasks > THRESHOLD_HIGH && cpu_usage < 80) {
// 任务多且 CPU 空闲 → 增加 Worker
spawn_new_worker();
} else if (pending_tasks < THRESHOLD_LOW && current_workers > MIN_WORKERS) {
// 任务少 → 减少 Worker
terminate_idle_worker();
}
}
4.5 并行回放效果
性能对比:
场景: 回放 1GB 的 WAL 日志
顺序回放:
- 耗时: 60 秒
- 吞吐: ~17 MB/s
并行回放 (4 Workers):
- 耗时: 20 秒
- 吞吐: ~51 MB/s
- 加速比: 3x
并行回放 (8 Workers):
- 耗时: 12 秒
- 吞吐: ~85 MB/s
- 加速比: 5x
五、高可用切换详解
5.1 三节点高可用架构
PolarDB for PostgreSQL 支持三节点高可用模式,基于 X-Paxos 协议实现:
┌──────────────────────────────────────────────────┐
│ 三节点高可用架构 │
└──────────────────────────────────────────────────┘
数据中心 A 数据中心 B 数据中心 C
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ RW (Leader)│ │ RO (Follower)│ │ RO (Follower)│
│ 节点 1 │ │ 节点 2 │ │ 节点 3 │
└──────┬──────┘ └──────┬───────┘ └──────┬──────┘
│ │ │
│ │ │
│ X-Paxos Consensus Protocol │
│ │ │
└──────────────────┴──────────────────┘
│
↓
┌──────────────────────────┐
│ 共享存储 (PolarFS) │
│ - WAL 日志 │
│ - 数据文件 │
└──────────────────────────┘
5.2 X-Paxos 核心原理
5.2.1 双日志机制
PolarDB 实现了创新的双日志机制:
日志 1: WAL 日志(数据库日志)
- 记录数据库的修改操作
- 存储在共享存储上
- 用于数据恢复和回放
日志 2: Consensus 日志(一致性日志)
- 记录 WAL 的同步状态
- 基于 X-Paxos 协议复制
- 用于确定多数派确认点
关键创新:
传统 Paxos: 对数据本身达成共识(慢)
X-Paxos: 对 WAL 元数据达成共识(快)
具体实现:
1. RW 节点生成 WAL → 写入共享存储
2. 生成 Consensus Log Entry:
{
"wal_segment": "000000010000000000000001",
"end_lsn": "0/1A2B3C4D",
"term": 5
}
3. Consensus Log 通过 X-Paxos 复制到多数节点
4. 确认多数节点持久化后,提交事务
5.2.2 日志关联机制
关键技术点:
1. 日志对应关系
每个 WAL Segment 对应一个 Consensus Log Entry
WAL Segment: pg_wal/000000010000000000000001
└→ 记录了 LSN 0/0 到 0/1000000 的数据修改
Consensus Log Entry:
{
"wal_file": "000000010000000000000001",
"start_lsn": "0/0",
"end_lsn": "0/1000000",
"term": 3,
"timestamp": 1234567890
}
2. 持久化依赖
Consensus Log 持久化前提:
对应的 WAL Log 必须已经持久化
代码逻辑(伪代码):
bool can_persist_consensus_log(ConsensusLogEntry* entry) {
// 检查对应的 WAL Segment 是否已刷盘
LSN wal_flush_lsn = get_wal_flush_lsn();
if (wal_flush_lsn >= entry->end_lsn) {
return true; // WAL 已持久化,可以写 Consensus Log
}
return false; // WAL 未持久化,必须等待
}
3. Commit Point 推进
Leader 节点计算 Commit Point:
1. 收集所有节点的 Consensus Log 持久化位点:
- Node1: Entry_100 (LSN 0/A000000)
- Node2: Entry_98 (LSN 0/9800000)
- Node3: Entry_99 (LSN 0/9900000)
2. 计算多数派位点 (Quorum = 2):
排序: [Entry_100, Entry_99, Entry_98]
多数派: Entry_99 (第 2 个)
3. 推进 Commit Point:
Commit LSN = Entry_99.end_lsn = 0/9900000
4. 通知应用层可以提交事务
5.2.3 Term 机制
Term(任期)的作用:
- 每次 Leader 切换,Term 递增
- 防止脑裂和旧 Leader 干扰
- 保证 WAL 日志的一致性
Term 状态管理:
struct TermState {
int64 current_term; // 当前 Term
LSN term_start_lsn; // 该 Term 开始的 LSN
LSN term_wal_aligned_lsn; // 该 Term WAL 对齐点
bool is_leader; // 是否为 Leader
};
// Leader 切换时的 WAL 对齐
void handle_leader_change(int64 new_term) {
if (new_term > current_term) {
// 1. 更新 Term
current_term = new_term;
// 2. 等待 WAL 对齐
// 新 Leader 必须截断上一任期的未提交 WAL
LSN last_commit_lsn = get_last_commit_lsn_from_consensus();
truncate_wal_after(last_commit_lsn);
// 3. 标记 Term 对齐完成
term_wal_aligned_lsn = last_commit_lsn;
// 4. 开始接受新的写入
if (is_new_leader) {
start_accepting_writes();
}
}
}
Term 与 Consensus Log 的关系:
只有当 WAL Log 的 Term 推进到最新时,
对应 Term 的 Consensus Log 才能持久化
示例:
- 当前 Term = 5
- 上一任期 (Term 4) 的 WAL 可能未完全对齐
- 必须等待 WAL Term 推进到 5
- 之后才能持久化 Term 5 的 Consensus Log
代码逻辑:
bool can_persist_consensus_log_with_term(ConsensusLogEntry* entry) {
if (entry->term < current_term) {
// 旧 Term 的日志,检查是否在截断点之前
return entry->end_lsn <= term_wal_aligned_lsn;
} else if (entry->term == current_term) {
// 当前 Term,检查 WAL 是否已持久化
return get_wal_flush_lsn() >= entry->end_lsn;
} else {
// 未来的 Term,不应该出现
return false;
}
}
5.3 Consensus 服务进程
进程架构:
┌────────────────────────────────────────────────┐
│ Consensus Service Process │
├────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌──────────────┐ │
│ │ I/O Threads │ │Worker Threads│ │
│ │ (网络通信) │ │ (协议处理) │ │
│ └──────┬──────┘ └──────┬───────┘ │
│ │ │ │
│ │ ↓ │
│ │ ┌──────────────────┐ │
│ │ │ 选举 (Election) │ │
│ │ └──────────────────┘ │
│ │ │
│ ↓ ↓ │
│ ┌─────────────┐ ┌──────────────┐ │
│ │Append Thread│ │Advance Thread│ │
│ │(日志生成) │ │(位点推进) │ │
│ └─────────────┘ └──────────────┘ │
└────────────────────────────────────────────────┘
各线程职责:
1. I/O Threads(I/O 线程)
void io_thread() {
while (true) {
// 监听网络事件
Event event = epoll_wait(epoll_fd);
if (event.type == APPEND_REQUEST) {
// 收到 Follower 的 Append 请求
handle_append_request(event);
} else if (event.type == VOTE_REQUEST) {
// 收到投票请求
handle_vote_request(event);
} else if (event.type == HEARTBEAT) {
// 收到心跳
handle_heartbeat(event);
}
}
}
2. Worker Threads(工作线程)
void worker_thread() {
while (true) {
Task task = dequeue_task();
switch (task.type) {
case ELECTION_TASK:
// 处理选举任务
start_leader_election();
break;
case APPEND_LOG_TASK:
// 处理日志追加任务
process_append_log(task);
break;
case COMMIT_TASK:
// 处理提交任务
commit_consensus_log(task);
break;
}
}
}
3. Append Thread(日志生成线程)
void append_thread() {
while (true) {
// 1. 获取当前 WAL 刷盘位置
LSN current_wal_flush_lsn = get_wal_flush_lsn();
// 2. 获取上次生成 Consensus Log 的位置
LSN last_consensus_lsn = get_last_consensus_lsn();
// 3. 如果有新的 WAL 段,生成 Consensus Log
if (current_wal_flush_lsn > last_consensus_lsn + WAL_SEGMENT_SIZE) {
ConsensusLogEntry entry = {
.term = current_term,
.start_lsn = last_consensus_lsn,
.end_lsn = last_consensus_lsn + WAL_SEGMENT_SIZE,
.timestamp = get_current_timestamp()
};
// 4. 提交到 X-Paxos 协议层
xpaxos_propose(entry);
}
sleep(APPEND_INTERVAL);
}
}
4. Advance Thread(位点推进线程)
void advance_thread() {
while (true) {
// 1. 收集所有节点的 Consensus Log 持久化位点
List<LSN> node_lsns;
foreach (Node node in cluster_nodes) {
LSN node_lsn = get_node_consensus_lsn(node);
node_lsns.add(node_lsn);
}
// 2. 计算多数派位点
sort(node_lsns);
LSN quorum_lsn = node_lsns[quorum_index]; // quorum_index = (N+1)/2
// 3. 推进 WAL Commit 位点
if (quorum_lsn > current_commit_lsn) {
advance_wal_commit_lsn(quorum_lsn);
// 4. 通知数据库层可以提交事务
notify_database_commit(quorum_lsn);
}
sleep(ADVANCE_INTERVAL);
}
}
5.4 故障切换流程
5.4.1 自动故障切换(Automatic Failover)
触发条件:
- RW 节点心跳超时
- RW 节点进程崩溃
- RW 节点所在主机宕机
切换流程:
┌────────────────────────────────────────────────────┐
│ 自动故障切换流程 │
└────────────────────────────────────────────────────┘
阶段 1: 故障检测 (1-3 秒)
┌──────────────────────────────────┐
│ Consensus Service 检测到: │
│ - RW 节点心跳超时 (3 次) │
│ - 超时阈值: 3 秒 │
└──────────────┬───────────────────┘
│
↓
阶段 2: 发起选举 (3-5 秒)
┌──────────────────────────────────┐
│ 1. Term 递增: Term 5 → Term 6 │
│ 2. 候选节点发起投票请求 │
│ 3. 收集投票结果 │
│ 4. 获得多数派支持 → 成为新 Leader│
└──────────────┬───────────────────┘
│
↓
阶段 3: WAL 对齐 (5-10 秒)
┌──────────────────────────────────┐
│ 1. 新 Leader 获取 Commit LSN │
│ Commit LSN = 0/5000000 │
│ 2. 截断未提交的 WAL │
│ 当前 WAL LSN = 0/5100000 │
│ 截断: 0/5100000 → 0/5000000 │
│ 3. 标记 Term 对齐完成 │
└──────────────┬───────────────────┘
│
↓
阶段 4: 提升为 RW (10-15 秒)
┌──────────────────────────────────┐
│ 1. RO → RW 角色转换 │
│ 2. 启动 WAL Writer 进程 │
│ 3. 开始接受写入请求 │
│ 4. 更新 VIP/DNS 指向新 Leader │
└──────────────┬───────────────────┘
│
↓
阶段 5: 服务恢复 (15-30 秒)
┌──────────────────────────────────┐
│ 1. 应用重新连接到新 Leader │
│ 2. 其他 RO 节点开始从新 Leader │
│ 同步 WAL Meta │
│ 3. 集群恢复正常服务 │
└──────────────────────────────────┘
总耗时: 15-30 秒 (典型: ~30 秒)
RPO: 0 (无数据丢失)
RTO: 15-30 秒
详细代码逻辑(伪代码):
// 1. 故障检测
void detect_leader_failure() {
if (time_since_last_heartbeat() > HEARTBEAT_TIMEOUT) {
log("Leader heartbeat timeout detected");
trigger_failover();
}
}
// 2. 选举流程
void start_leader_election() {
// 递增 Term
current_term++;
// 投票给自己
voted_for = self_node_id;
votes_received = 1;
// 向其他节点发送投票请求
foreach (Node node in cluster_nodes) {
if (node != self) {
send_vote_request(node, current_term);
}
}
// 等待投票结果
wait_for_votes();
if (votes_received >= quorum) {
log("Elected as new Leader in Term %d", current_term);
become_leader();
}
}
// 3. 成为新 Leader
void become_leader() {
// 1. 获取最新的 Commit LSN
LSN commit_lsn = get_latest_commit_lsn_from_consensus();
// 2. 截断未提交的 WAL
LSN current_wal_lsn = get_wal_lsn();
if (current_wal_lsn > commit_lsn) {
log("Truncating WAL from %X/%X to %X/%X",
LSN_FORMAT_ARGS(current_wal_lsn),
LSN_FORMAT_ARGS(commit_lsn));
truncate_wal(commit_lsn);
}
// 3. 标记 Term 对齐完成
term_wal_aligned_lsn = commit_lsn;
// 4. 从 RO 提升为 RW
promote_to_readwrite();
// 5. 启动 WAL Writer
start_wal_writer();
// 6. 开始接受写入
is_leader = true;
accept_writes = true;
// 7. 发送心跳到所有节点
send_heartbeat_to_all_nodes();
}
// 4. 提升为读写节点
void promote_to_readwrite() {
// 1. 结束 WAL Receiver(从节点复制进程)
shutdown_wal_receiver();
// 2. 结束 Startup Process(回放进程)
shutdown_startup_process();
// 3. 启动 WAL Writer
start_wal_writer();
// 4. 启动 Checkpointer
start_checkpointer();
// 5. 标记为 RW 模式
ControlFile->state = DB_IN_PRODUCTION;
UpdateControlFile();
// 6. 开始接受连接
start_accepting_connections();
}
5.4.2 手动故障切换(Manual Failover)
使用场景:
- 计划内维护
- 主动切换到更优节点
- 测试故障切换流程
操作命令(阿里云控制台):
# 通过 API 或控制台指定新的主节点
aliyun polardb FailoverDBCluster \
--DBClusterId pc-xxxxx \
--TargetDBNodeId pi-xxxxx
切换流程:
1. 用户发起切换请求
↓
2. 停止 RW 节点接受新连接
↓
3. 等待所有事务完成
↓
4. 确保 WAL 刷盘
↓
5. 更新 Consensus 状态
↓
6. 选举指定的 RO 节点为新 Leader
↓
7. 新 Leader 提升为 RW
↓
8. 旧 RW 降级为 RO
↓
9. 更新连接信息(VIP/DNS)
↓
10. 完成切换
切换时间: 约 30 秒
数据丢失: 0 (RPO=0)
5.5 故障切换优先级
节点优先级配置:
-- 设置节点故障切换优先级
ALTER SYSTEM SET failover_priority = 1; -- 高优先级
ALTER SYSTEM SET failover_priority = 2; -- 中优先级
ALTER SYSTEM SET failover_priority = 3; -- 低优先级
选举优先级因素:
选举得分 = 基础分 + 优先级分 + 健康分
1. 基础分:
- 最新的 Consensus Log 位点: +100
- WAL 对齐状态: +50
2. 优先级分:
- failover_priority = 1: +30
- failover_priority = 2: +20
- failover_priority = 3: +10
3. 健康分:
- CPU 使用率 < 50%: +10
- 内存使用率 < 70%: +10
- 磁盘 I/O 正常: +10
最终得分最高的节点被选为新 Leader
5.6 数据一致性保证
RPO = 0 的实现原理:
┌────────────────────────────────────────────────────┐
│ RPO = 0 实现机制 │
└────────────────────────────────────────────────────┘
客户端事务提交流程:
1. 客户端: COMMIT;
↓
2. RW 节点: 生成 WAL Record
↓
3. 写入共享存储 (同步写入)
WAL LSN = 0/1234567
↓
4. 生成 Consensus Log Entry
{
"lsn": "0/1234567",
"term": 5
}
↓
5. X-Paxos 协议复制到多数节点
Node1: ✓ 已持久化
Node2: ✓ 已持久化
Node3: ✗ 网络延迟
↓
6. 多数派确认 (2/3)
↓
7. 返回客户端: COMMIT Success
关键点:
- 事务提交前,WAL 必须在多数节点确认持久化
- 共享存储保证数据不丢失
- X-Paxos 保证多数派一致性
- 因此 RPO = 0,无数据丢失
故障恢复后的数据一致性:
场景: 旧 Leader 宕机,新 Leader 选出
旧 Leader 状态:
- 已提交 LSN: 0/5000000
- 未提交 LSN: 0/5000000 ~ 0/5100000 (100 条 WAL)
新 Leader 选出后:
1. 查询 Consensus Log 的 Commit Point
Commit LSN = 0/5000000
2. 截断未提交的 WAL
truncate_wal(0/5000000)
删除: 0/5000000 ~ 0/5100000
3. 从 0/5000000 开始接受新的写入
旧 Leader 恢复后:
1. 检测到 Term 变更
2. 截断本地 WAL 到 Commit Point
truncate_wal(0/5000000)
3. 作为 Follower 从新 Leader 同步
结果: 所有节点 WAL 对齐,数据一致
六、技术优势总结
6.1 性能优势
| 指标 | 传统架构 | PolarDB (LogIndex) | 提升倍数 |
|---|---|---|---|
| RO 延迟 | 秒级 | 毫秒级 | 100x-1000x |
| 网络传输 | 100% WAL | 2% WAL Meta | 50x |
| 回放效率 | 顺序回放 | 并行 + Lazy | 5x-10x |
| 存储成本 | N 份 | 1 份 | N倍节省 |
6.2 可用性优势
| 特性 | 传统主从 | PolarDB 三节点 HA |
|---|---|---|
| RPO | 秒级-分钟级 | 0 (无数据丢失) |
| RTO | 分钟级 | 30 秒内 |
| 自动切换 | 依赖外部工具 | 内置 X-Paxos |
| 脑裂保护 | 需要 Fencing | Term 机制自动保护 |
6.3 扩展性优势
读扩展:
- 传统: 受限于主节点复制能力
- PolarDB: 最多 15 个 RO 节点,延迟毫秒级
写扩展:
- 传统: 单点写入
- PolarDB: 单点写入(未来可能支持分布式写入)
存储扩展:
- 传统: 需要为每个节点扩容
- PolarDB: 共享存储,扩容一次即可
七、参考资料
官方文档
- PolarDB for PostgreSQL 官方文档: https://apsaradb.github.io/PolarDB-for-PostgreSQL/
- LogIndex 技术文档: https://docs.polardbpg.com/theory/logindex.html
- WAL 并行回放文档: https://www.alibabacloud.com/help/en/polardb/polardb-for-postgresql/wal-log-parallel-replay
- 三节点高可用文档: https://docs.polardbpg.com/PolarDB-for-PostgreSQL/HA-with-Three-Nodes.html
开源代码
- GitHub 仓库: https://github.com/ApsaraDB/PolarDB-for-PostgreSQL
- 架构文档: https://github.com/ApsaraDB/PolarDB-for-PostgreSQL/blob/main/doc/PolarDB-EN/Architecture.md
- Buffer Management: https://github.com/ApsaraDB/PolarDB-for-PostgreSQL/blob/main/doc/PolarDB-EN/Buffer_Management.md
技术博客
- 阿里云云栖社区: https://www.cnblogs.com/yunqishequ/p/16039026.html
- PolarDB 架构解读: https://zhuanlan.zhihu.com/p/564103433
八、总结
PolarDB for PostgreSQL 通过以下核心技术创新,实现了高性能、高可用的云原生数据库:
- 共享存储架构: 计算存储分离,降低成本,提升灵活性
- LogIndex 技术: 仅传输 WAL Meta,网络流量减少 98%
- Lazy Replay: 按需回放,避免不必要的 WAL 回放
- Parallel Replay: 多进程并行回放,提升回放效率 5-10 倍
- X-Paxos 高可用: 金融级 RPO=0,RTO < 30秒
- 双日志机制: WAL Log + Consensus Log,兼顾性能和一致性
这些技术的结合,使得 PolarDB for PostgreSQL 在云原生场景下,相比传统 PostgreSQL 具有显著的优势。

















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









