




 本文探讨了MCS自旋锁在多CPU场景中的问题,介绍了队列自旋锁如何通过缩减空间、优化等待队列和避免缓存一致性开销来提升性能。重点讲解了自旋锁的工作原理、结构优化及加解锁流程的细节。
本文探讨了MCS自旋锁在多CPU场景中的问题,介绍了队列自旋锁如何通过缩减空间、优化等待队列和避免缓存一致性开销来提升性能。重点讲解了自旋锁的工作原理、结构优化及加解锁流程的细节。
一、要点总结
1、要点一:
1)MCS lock可以解决在锁的争用比较激烈的场景下,cache line无谓刷新的问题。
2)MCS lock内含一个指针,所以更消耗存储空间,但这个指针又是不可或缺的,因为正是依靠这个指针,持有spinlock的CPU才能找到等待队列中的下一个节点,将spinlock传递给它。
3)在64位系统上光这个MCS lock指针就要占用8个字节,再加上locked占用4个字节,count也要占用4个字节,一共有可能要占用16个字节。
4)使用qspinlock,其首要目标就是把原生的MCS lock结构体进行改进,缩减到4字节的空间里。
2、要点二:
队列自旋锁结构是一个联合体,一共占用32位,4个字节;
1)前8位是locked域,表示自旋锁是否已经被某个CPU所持有了,只有0-1两个值变化;
2)接着8位是pending域,这个是对MCS自旋锁的一个优化,只有0-1两个值变化;
3)最后的16位是tail域,通过这个域可以找到自旋锁队列的最后一个节点。
4)tail域又被拆分成了两个部分:
第一部分有2个比特,表示在某个CPU上节点的序号,所以一个CPU上最多有4个节点;
第二部分有14个比特,表示是哪个CPU(CPU对应的编号加1)在等待这个自旋锁,所以一共能表示16384个CPU。一般系统中的CPU的个数是不会太多的,使用CPU号加上节点编号来唯一定位一个mcs_spinlock结构,使用16位就够了。

3、要点三:
1)自旋锁要保证能正常工作,在一个CPU上最多只能同时持有4个,因此,每个CPU上最多只需要4个MCS结构体;
2)自旋锁是不可重入的,一个自旋锁只能被同一个CPU获得一次,否则会造成死锁;
3)第1个等待自旋锁的CPU直接在锁自身上面自旋等待,后面队列里的CPU在自己的mcs_spinlock结构体本地变量上自旋等待。
4)持有锁者占用locked域1,第一继承人占用pending域1自旋,队列的头节点自旋等待锁的locked域和pending域都变成0,队列中后面的节点自旋等待本节点内的locked域变成1。
5)最多只会有一个CPU监测到这种pending位从0到1的跳变,只能有一个CPU能“抢”到pending位,持有pending位的CPU,是自旋等待锁的locked域变成0,不需要任何CPU节点。当锁的持有者释放锁的时候,迅速设置锁的locked域,并清空pending位为0,从而变成该锁的持有者。
6)如果前一个节点“抢”到了自旋锁后,在撤销之前,会将后一个节点的locked域变为1。
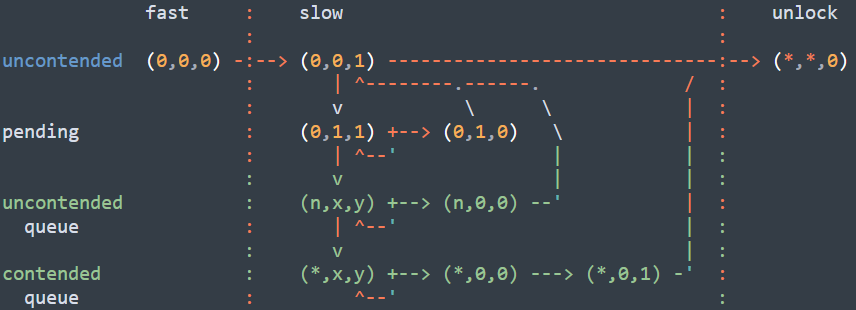
所以,总结一下,队列自旋锁的加锁步骤如下:
1)如果qspinlock整体val为0,说明锁空闲,则当前CPU设置qspinlock的locked位为1后直接持锁;
2)第1个等锁的CPU设置pending位后,自旋等待locked位变成0;
3)第2个等锁的CPU将tail设置为指向本CPU变量的mcs_spinlock节点,然后自旋等待locked域和pending位都变成0;
4)第N个等锁的CPU也将tail设置为指向本CPU变量的mcs_spinlock节点,并将之前队尾节点的next指向自己,然后自旋转等待本CPU变量的mcs_spinlock节点中的locked域变成1。
二、源码解析
以下内容转发自:Linux内核同步原语之自旋锁(Spin Lock)
自旋锁(Spinlock)是一种在 Linux 内核中广泛运用的底层同步机制。
自旋锁是用来在多CPU环境中工作的一种特殊的锁,也就是说只有真正有两个或以上执行序列同时执行时此锁才起作用。如果内核控制路径发现自旋锁空闲,就获取该自旋锁并继续执行程序;相反,如果内核控制路径发现锁已经由运行在另一个CPU上的内核控制路径持有了,就自己自旋等待,反复执行一条紧凑的循环指令,直到锁被释放为止。自旋锁的循环等待是所谓的“忙”等,即使等待的内核控制路径无事可做,它也在CPU上一直保持运行,并不会让当前的内核控制路径主动交出CPU的控制权。
由自旋锁保护的每个临界区都是禁止内核抢占的。在单处理器系统上,这种锁本身并不起锁的作用,仅仅退化成禁止内核抢占。
MCS自旋锁
传统自旋锁有一个很大的性能问题,所有等待同一个自旋锁的CPU在同一个变量上自旋等待,获得或者释放锁的时候会对这个变量进行修改。对于单CPU的系统,这个不是问题,但是对于SMP多CPU系统来说,由于缓存一致性的问题,一个CPU写入了一个变量后,必须要让所有其它处理器上对应该变量的缓存行失效,还需要使用内存屏障,在拥有几百甚至几千个处理器的大型系统中,将导致系统性能大幅下降。
为了解决上面的问题,聪明的内核设计者们想出了MCS(MCS是“Mellor-Crummey”和“Scott”这两个发明人的名字的首字母缩写)自旋锁,它有两个优点:
保证自旋锁申请者以先进先出的顺序获取锁(FIFO)。
只在本地可访问的标志变量上自旋。
MCS自旋锁的主要策略是为每个处理器创建一个变量副本,每个处理器在申请自旋锁的时候在自己的本地变量上自旋等待,避免缓存同步的开销。其自旋锁结构体的定义如下(代码位于kernel/locking/mcs_spinlock.h中):
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked;
int count;
};
MCS自旋锁采用链表结构将全体锁申请者的信息串成一个单向链表。每个锁申请者必须提前分配一个本地的mcs_spinlock结构体,其中至少包括 2 个域:本地自旋变量locked和指向下一个申请者mcs_spinlock结构体的指针变量next。locked初始值为0,申请者自旋等待locked值从0变成1。而MCS自旋锁变量就是一个永远指向最后一个申请者的mcs_spinlock结构体的指针。
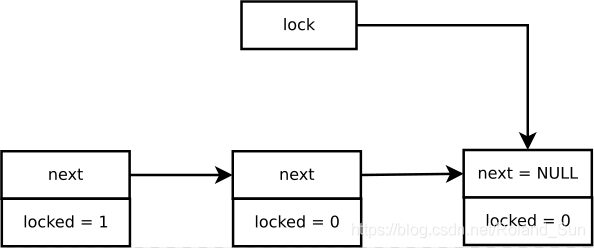
当前一个持有自旋锁的CPU释放该自旋锁的时候,会将下一个节点的locked域变成1,从而让对应的CPU跳出自旋等待。
但是,MCS自旋锁也有一个致命的弱点,就是这个锁的结构体占用空间太大了。锁里面有一个指针变量next,如果在64位系统上光这个指针就要占用8个字节,再加上locked占用4个字节,count也要占用4个字节,一共有可能要占用16个字节。由于自旋锁经常会嵌入在另一个结构体里面,用来保护该结构体,而且这个受保护的结构体可能在内核中使用频繁,对大小十分敏感,因此MCS自旋锁并不能完全取代普通的自旋锁实现。
队列自旋锁
为了解决MCS自旋锁自身的问题,又引入了所谓的队列自旋锁(Queued Spin Lock)。我们先来看看队列自旋锁的结构定义:
typedef struct qspinlock {
union {
atomic_t val;
#ifdef __LITTLE_ENDIAN
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
#else
struct {
u16 tail;
u16 locked_pending;
};
struct {
u8 reserved[2];
u8 pending;
u8 locked;
};
#endif
};
} arch_spinlock_t;
可以看到,这个自旋锁结构是一个联合体,一共占用32位,4个字节。而且,按照大端字节序和小端字节序刚好布局是反的。拿小端字节序来说,首先它是一个32位的原子结构val,同时它又能被拆分成三个部分:
1、前8位是locked域,表示自旋锁是否已经被某个CPU所持有了;
2、接着8位是pending域,这个是对MCS自旋锁的一个优化,后面会解释;
3、最后的16位是tail域,通过这个域可以找到自旋锁队列的最后一个节点。
按照各个域的作用,定义了如下一些宏:
#define _Q_SET_MASK(type) (((1U << _Q_ ## type ## _BITS) - 1)\
<< _Q_ ## type ## _OFFSET)
#define _Q_LOCKED_OFFSET 0
#define _Q_LOCKED_BITS 8
#define _Q_LOCKED_MASK _Q_SET_MASK(LOCKED)
#define _Q_PENDING_OFFSET (_Q_LOCKED_OFFSET + _Q_LOCKED_BITS) //8
#if CONFIG_NR_CPUS < (1U << 14)
#define _Q_PENDING_BITS 8
#else
#define _Q_PENDING_BITS 1
#endif
#define _Q_PENDING_MASK _Q_SET_MASK(PENDING)
#define _Q_TAIL_IDX_OFFSET (_Q_PENDING_OFFSET + _Q_PENDING_BITS) //16
#define _Q_TAIL_IDX_BITS 2
#define _Q_TAIL_IDX_MASK  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 168
168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









