



当你的系统突然弹出一个弹窗显示这个,你会以为是系统乱码了吗?
 当然不是,他可是大名鼎鼎的“贝斯家族”中的base64编码,解码后,其实是:
当然不是,他可是大名鼎鼎的“贝斯家族”中的base64编码,解码后,其实是:

什么是base64?接下来就带你了解
Base64是一种将二进制数据转换为可打印ASCII字符的编码方式,其核心目的是在文本协议中安全传输或存储二进制数据。
为什么需要 Base64?
Base64 的作用就是充当一个“翻译官”:
输入: 任意的二进制数据流(字节序列)。
输出: 一个仅由特定 64 个(或 65/66 个)可打印 ASCII 字符组成的字符串。
核心价值: 确保编码后的字符串在任何只支持文本的环境(如邮件系统、文本编辑器、文本协议)中都能被安全地传输、存储和显示,而不会丢失信息或引起问题。
想象一下这些场景:
1. 电子邮件(早期): 原始的电子邮件协议(如 SMTP)设计时只支持 7 位的 ASCII 字符(共 128 个)。它们无法直接处理包含非 ASCII 字符(如中文)或二进制数据(如图片、可执行文件)的邮件正文或附件。
2. HTML/CSS/JavaScript: 网页中有时需要直接嵌入小图片或其他二进制资源(如 Data URLs),但 HTML/CSS/JS 文件本质上是文本文件。
3. XML/JSON: 这些基于文本的数据格式有时需要携带二进制数据。
4. 基本认证: HTTP 基本认证在发送用户名和密码时,会将其拼接后用 Base64 编码放入 `Authorization` 头。
5. 在文本协议中传输二进制: 任何设计用于传输文本的协议(如某些 API、日志系统),如果需要偶尔传输二进制数据,Base64 是一种常用解决方案。
一、基本定义
1. 编码目标
Base64通过将二进制数据映射为64个可打印字符(A-Z、a-z、0-9、+、/),解决非文本协议(如早期邮件、HTTP)无法直接处理二进制数据的问题。
Base64字符表
|
索引 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
字符 |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
|
索引 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
|
字符 |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
a |
b |
c |
d |
e |
f |
|
索引 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
|
字符 |
g |
h |
i |
j |
k |
l |
m |
n |
o |
p |
q |
r |
s |
t |
u |
v |
|
索引 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
|
字符 |
w |
x |
y |
z |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
+ |
/ |
ASCII编码表:
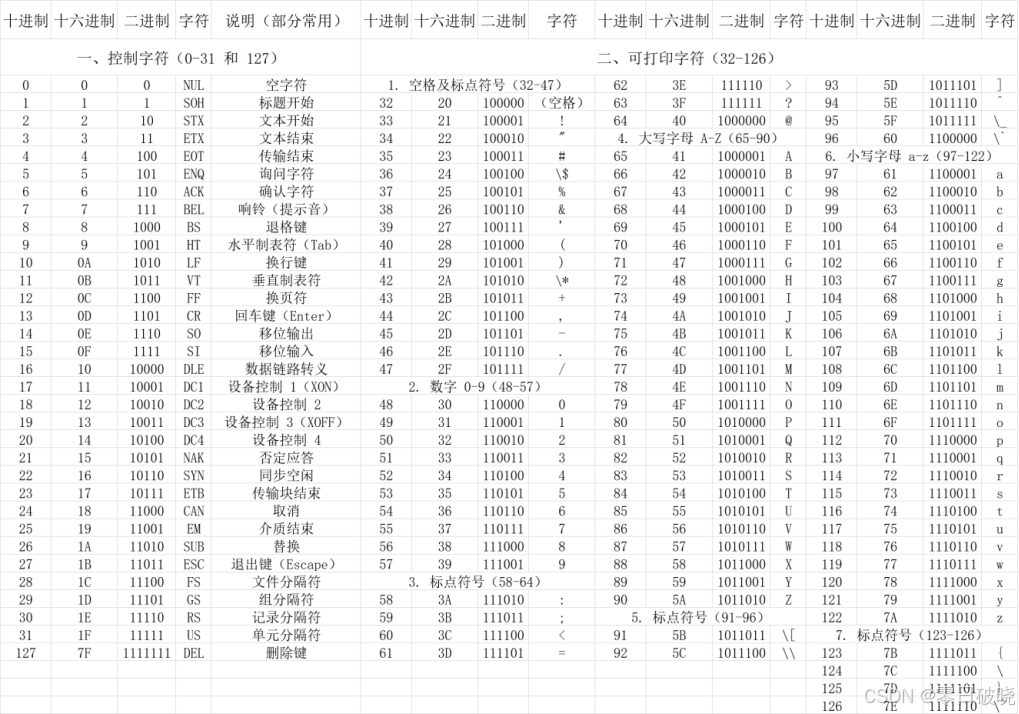
2. 字符集与填充
• 标准字符集包含64个字符,不足时用=填充以保证编码后长度为4的倍数。
• 变体如URL安全的Base64会替换+和/为-和_,并可能省略填充符。
3. 编码与解码
Base64的编码与解码有着双向可逆性
编码:将二进制数据按6位分组映射为Base64字符表中的字符。
解码:将Base64字符查表还原为6位二进制,再合并为原始8位字节。
数学表达:
解码(编码(原始数据))=原始数据(忽略填充符)
二、编码原理
编码流程图:
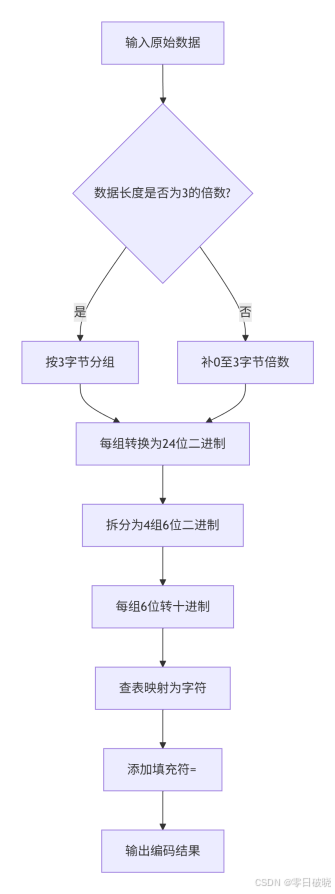
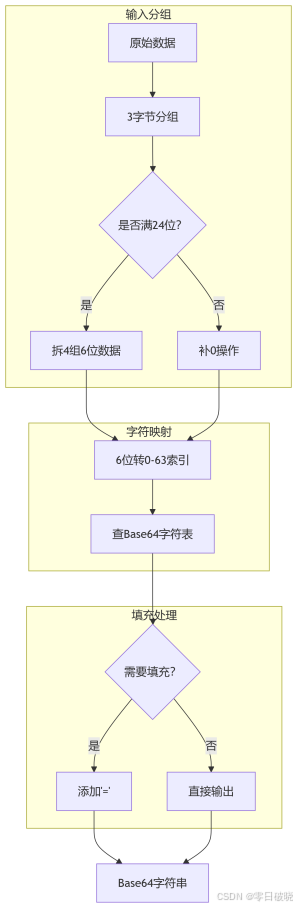
分组与转换
• 输入分组:将二进制数据按每3字节(24位)分组,拆分为4组6位二进制数(每组范围0-63)。
• 字符映射:每组6位数值对应Base64字符表中的字符(如010011对应字符T)。
• 填充处理:若原始数据长度非3的倍数,末尾补0并添加=字符(补1个0加1个=,补2个0加2个=)。
一、Base64分组与转换全流程
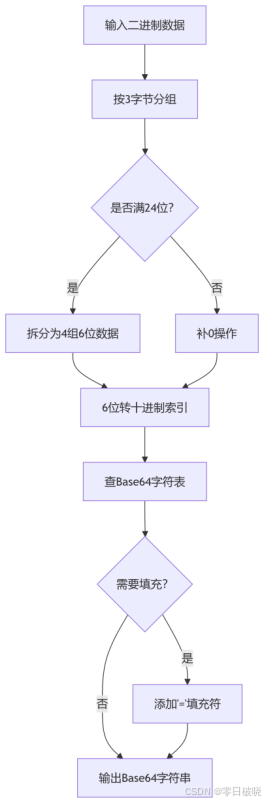
二、步骤解析
1. 输入分组:3字节分组(24位)
过程:
将二进制数据按每3字节(24位)分组
每组拆分为4个6位二进制数
每个6位数的范围:000000~111111(0~63)
示例:编码 "Man"
ASCII值:M=77, a=97, n=110
|
步骤 |
原始字节 |
二进制表示 |
分组结果 |
|
1 |
M (77) |
01001101 |
合并24位: 01001101 01100001 01101110 |
|
2 |
a (97) |
01100001 |
拆分为4组6位 010011 010110 000101 101110 |
|
3 |
n (110) |
01101110 |
每组范围:0-63 |
2. 字符映射:6位 → Base64字符
映射规则:
十进制索引 → 对应字符
0-25 → A-Z
26-51 → a-z
52-61 → 0-9
62 → +
63 → /
示例映射过程:
|
6位二进制 |
十进制值 |
Base64字符 |
计算逻辑 |
|
010011 |
19 |
T |
0=A,1=B...19=T |
|
010110 |
22 |
W |
22-0=W (A=0,B=1,...,W=22) |
|
000101 |
5 |
F |
A(0),B(1),C(2),D(3),E(4),F(5) |
|
101110 |
46 |
u |
26=a,27=b...46=u (46-26=20 → u是第20个小写字母) |
结果:"Man" → "TWFu"
3. 填充处理:非3字节倍数的情况
规则表:
|
原始字节数 |
补位操作 |
填充符 |
示例 |
|
3的倍数 |
无补位 |
无 |
"ABC" → "QUJD" |
|
余1字节 |
补4个0 |
== |
"A" → "QQ==" |
|
余2字节 |
补2个0 |
= |
"AB" → "QUI=" |
填充过程详解:
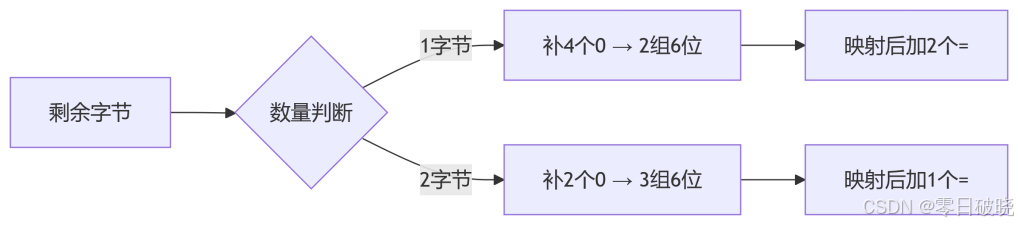
示例1:编码 "A"(1字节)
原始:01000001(8位)
补4个0:01000001 0000 → 12位
分组:
010000 → 16 → Q
010000 → 16 → Q
添加填充:QQ + == → "QQ=="
示例2:编码 "AB"(2字节)
原始:01000001 01000010(16位)
补2个0:01000001 01000010 00 → 18位
分组:
010000 → 16 → Q
010100 → 20 → U
001000 → 8 → I
添加填充:QUI + = → "QUI="
三、完整转换流程图
四、操作可视化
1. 3字节分组示意图
原始数据: [Byte1] [Byte2] [Byte3]
8位 8位 8位
↓ ↓ ↓
分组后: [6位][2位] + [4位][4位] + [2位][6位] → 错误!
正确分组:
[6位] [6位] [6位] [6位]
↓ ↓ ↓ ↓
24位连续数据拆分为4个6位段
2. 填充处理对比表
|
情况 |
输入 |
二进制 |
补位后 |
分组 |
映射 |
结果 |
|
完整组 |
"Man" |
24位 |
无补位 |
4组 |
TWFu |
TWFu |
|
2字节 |
"AB" |
16位 |
+2个0 |
010000→Q 010100→U 001000→I |
QUI |
QUI= |
|
1字节 |
"A" |
8位 |
+4个0 |
010000→Q 010000→Q |
|
QQ== |
三、解码原理
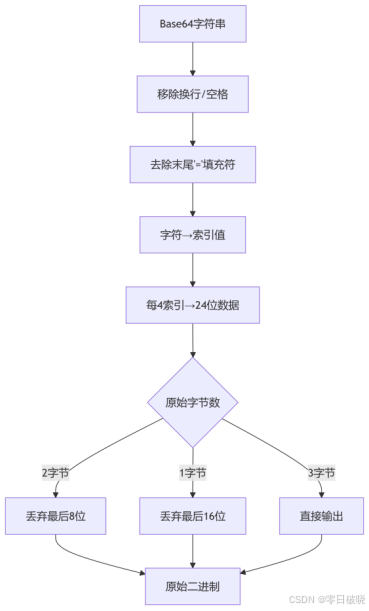
一、Base64 解码是编码的逆过程,将Base64字符串还原为原始二进制数据。
核心步骤如下:
1. 字符反查索引:将每个Base64字符转换回对应的6位索引值(0-63)
2. 位重组:将索引值按顺序连接成二进制串
3. 8位分组:每8位一组重组为字节
4. 填充处理:根据末尾'='数量丢弃补位的0
二、解码流程
1. 预处理阶段
移除无效字符:删除换行符、空格等非Base64字符
处理填充符:
0个`=` → 原始3字节
1个`=` → 原始2字节(需丢弃最后8位)
2个`=` → 原始1字节(需丢弃最后16位)
2. 字符到索引转换
Base64字符对照表:
|
字符 |
索引 |
二进制 |
字符 |
索引 |
二进制 |
|
A |
0 |
`000000` |
a |
26 |
`011010` |
|
B |
1 |
`000001` |
b |
27 |
`011011` |
|
... |
... |
... |
... |
... |
... |
|
Z |
25 |
`011001` |
0 |
52 |
`110100` |
|
+ |
62 |
`111110` |
63 |
/ |
`111111` |
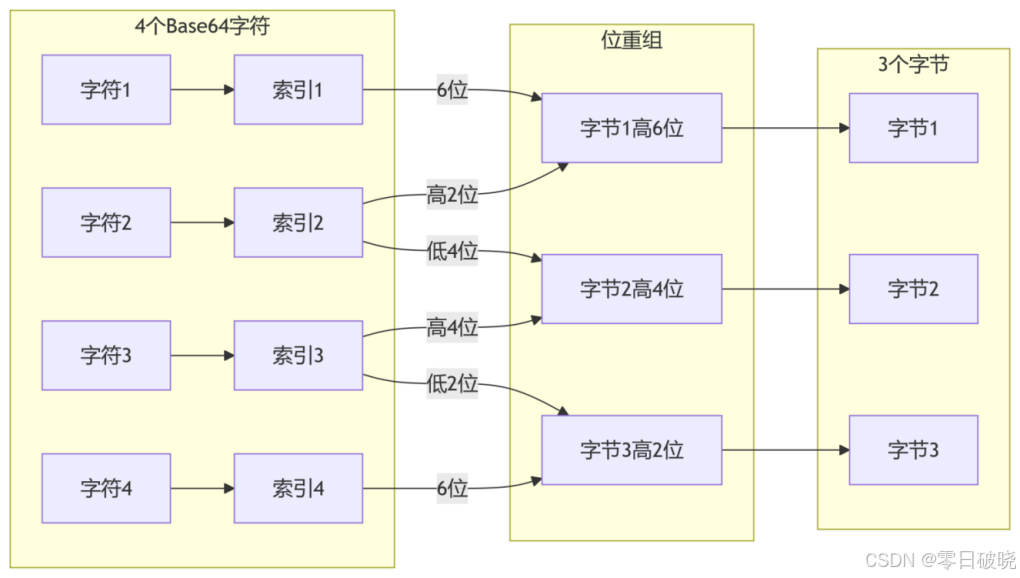
3. 位重组过程(核心)
重组规则:
[索引1][索引2][索引3][索引4] →
[索引1高6位 + 索引2高2位] → 字节1
[索引2低4位 + 索引3高4位] → 字节2
[索引3低2位 + 索引4高6位] → 字节3
4. 填充处理详解
情况1:无填充(完整3字节)
示例:解码 "TWFu" → "Man"
索引: T(19)→010011, W(22)→010110, F(5)→000101, u(46)→101110
重组:
字节1:010011 + 01 (W的前2位) → 01001101 → 77 (M)
字节2:0110 (W的后4位) + 0001 (F的前4位) → 01100001 → 97 (a)
字节3:01 (F的后2位) + 101110 → 01101110 → 110 (n)
情况2:1个填充符(原始2字节)
示例:解码 "QUI=" → "AB"
1. 移除'==' → 处理"QQ"
2. 索引:Q(16)→010000, Q(16)→010000
3. 重组:
字节1:010000 + 01 (第二个Q前2位) → 01000001 → 65 (A)
后续数据:00 (第二个Q后4位) + ???? → 无效数据(需丢弃)
4. 因有2个'=',丢弃最后16位(2字节)
情况3:2个填充符(原始1字节)
示例:解码 "QQ==" → "A"
1. 移除'==' → 处理"QQ"
2. 索引:Q(16)→010000, Q(16)→010000
3. 重组:
字节1:010000 + 01 (第二个Q前2位) → 01000001 → 65 (A)
后续数据:00 (第二个Q后4位) + ???? → 无效数据(需丢弃)
4. 因有2个'=',丢弃最后16位(2字节)
三、解码过程完整示例
示例:解码 "U2FsdGVkX1+" (字符串"SaltX_")
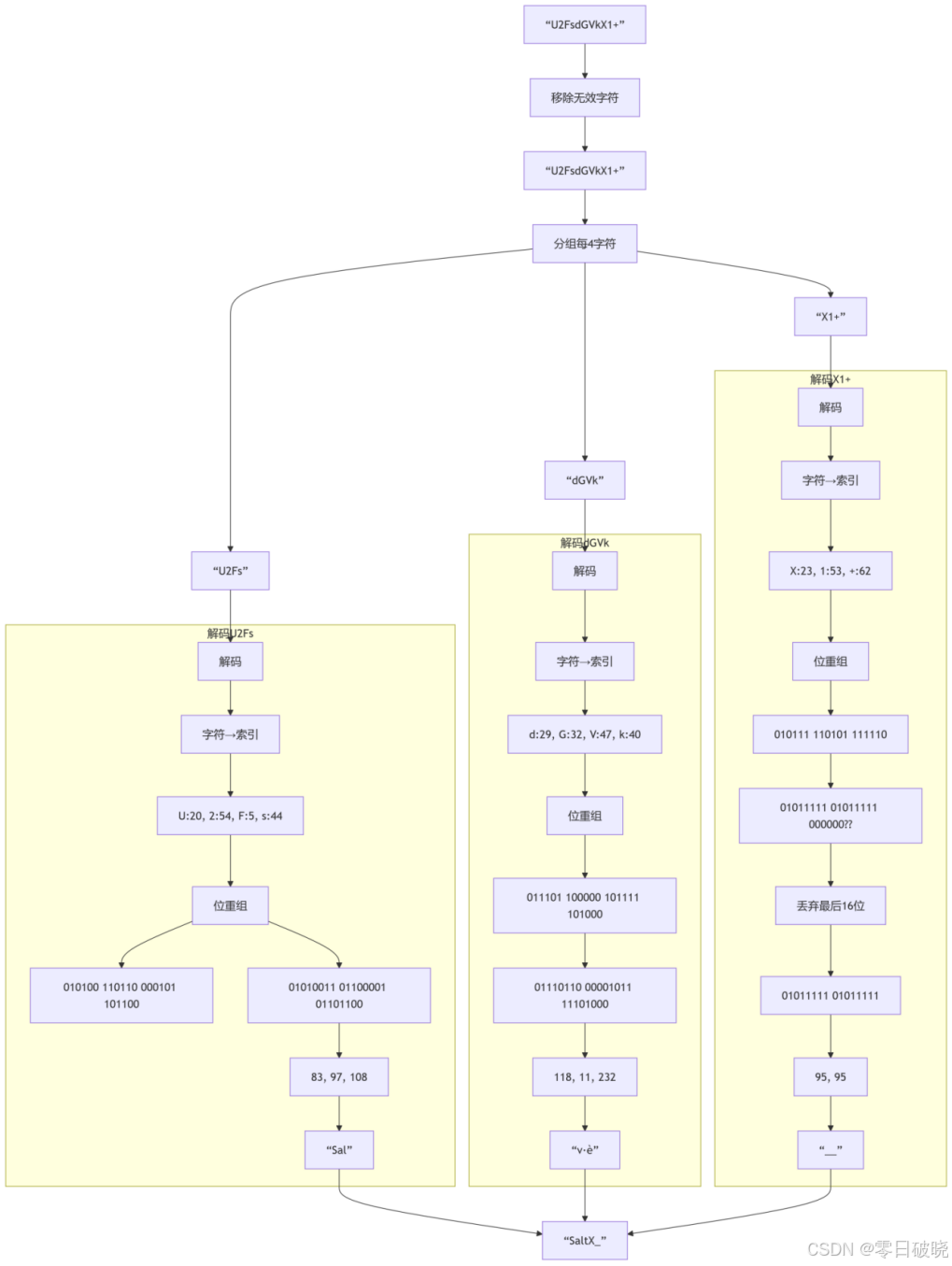
处理说明:
1. "X1+" 有3字符(不足4),实际是"X1+="省略了填充符
2. 解码时按2个'='处理(原始1字节),但这里得到2有效字节
3. 最终输出:S(83) + a(97) + l(108) + t(116) + X(88) + _(95)
四、应用场景详解
1. 数据传输
|
场景 |
技术原理 |
典型案例 |
|
电子邮件附件 |
遵循MIME标准: 将二进制文件(如图片、压缩包)编码为ASCII文本 通过SMTP协议传输纯文本邮件 |
`Content-Type:image/jpeg; base64` `Content-Transfer-Encoding: base64` |
|
HTTP表单文件上传 |
浏览器将文件二进制流编码为Base64字符串 通过JSON或`multipart/form-data`传输 |
{"file": "iVBORw0KGgoAAAANSUhEUgAA..." } |
|
跨平台二进制传输 |
避免二进制数据破坏文本结构(如JSON/XML中的控制字符) |
小程序/API传输图片: `{"avatar": "aGVsbG8gd29ybGQ="}` |
2. 数据存储
|
场景 |
技术原理 |
优缺点对比 |
|
数据库存储文件 |
将二进制文件转为文本存入`TEXT`字段 (避免BLOB字段的兼容性问题) |
✅ 优点:跨数据库兼容 ❌ 缺点:体积膨胀33%,查询效率低 |
|
前端Data URL |
内嵌资源减少HTTP请求: `<img src="data:image/png;base64,iVBOR...">` |
✅ 优点:提升小资源加载速度 ❌ 缺点:HTML体积增大,无法缓存 |
3. 协议兼容性

核心价值:解决传统文本协议(如邮件、Telnet)的8位字节流支持缺陷,确保二进制数据在7位ASCII系统中无损传输。
五、优缺点深度分析
优点
|
特性 |
技术原理 |
实践价值 |
|
兼容性 |
仅使用64个ASCII字符(A-Z,a-z,0-9,+,/)和`=` |
可在任何支持文本的系统(如COBOL主机)中处理数据 |
|
简单性 |
算法仅需查表与位运算: `编码:3字节→4字符` `解码:4字符→3字节` |
各语言均有内置库(Python `base64`/JS `atob,btoa`) |
缺点
|
缺陷 |
技术原理 |
解决方案 |
|
数据膨胀33% |
数学本质:每3字节→4字符 `膨胀率 = (4-3)/3 ≈ 33.33%` |
• Gzip压缩后再编码 • 大文件改用CDN分发 |
|
非加密性 |
编码可逆且无密钥机制: `base64("secret") = "c2VjcmV0"` → 轻松解码 |
• 敏感数据先加密再编码(如AES+Base64) • 使用JWT等签名机制 |
|
解码开销 |
每字节需6次位运算+查表 |
大数据流使用SIMD指令优化(如x86 `SSE`) |
六、典型问题与解决方案
1. Base64数据膨胀的数学证明
原始数据 = 3N 字节
编码后 = 4N 字符(每字符1字节)
膨胀率 = (4N - 3N) / 3N = 1/3 ≈ 33.33%
案例:
1MB文件 → Base64后 ≈ 1.33MB
传输100张图片:原始30MB → 编码后40MB → 网络流量增加10MB
2. 安全风险案例:前端“伪加密”
// 错误做法:用Base64“加密”密码
const password = btoa("myPassword123"); // "bXlQYXNzd29yZDEyMw=="
// 攻击者直接解码:
atob("bXlQYXNzd29yZDEyMw==") // 还原为明文密码!
解决方案:
// 正确流程:加密+编码
import { encryptAES } from 'crypto-lib';
const encrypted = encryptAES("myPassword123", key);
const safeToTransmit = btoa(encrypted); // 先加密再编码
3. 性能优化方案对比
|
方法 |
适用场景 |
提升效果 |
|
流式处理 |
大文件编解码 |
内存占用降90%+ |
|
SIMD指令并行 |
高性能服务器 |
吞吐量提升8倍(AVX512) |
|
WebAssembly |
浏览器环境 |
比JS快3-5倍 |
七、总结:技术选型建议
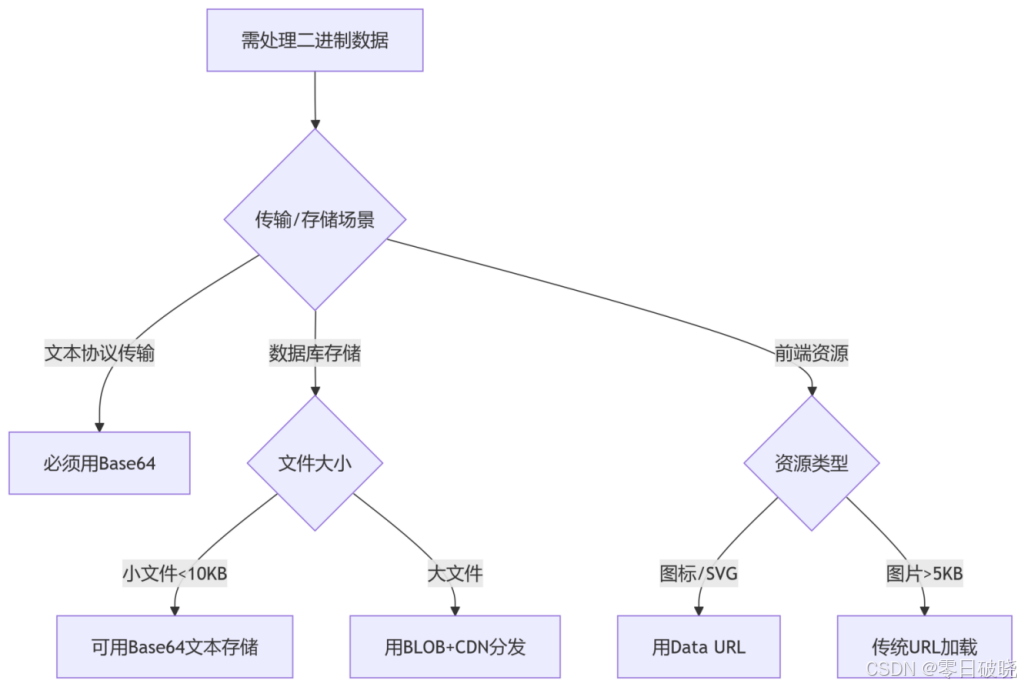
黄金准则:
1. 仅在协议强制要求文本时使用Base64(如邮件附件)
2. 前端资源内嵌控制在2KB以内(否则抵消HTTP优化收益)
3. 敏感数据必须加密,Base64不是安全方案!
版权声明与原创承诺
本文所有文字、实验方法及技术分析均为 本人原创作品,受《中华人民共和国著作权法》保护。未经本人书面授权,禁止任何形式的转载、摘编或商业化使用。
道德与法律约束
文中涉及的网络安全技术研究均遵循 合法合规原则:
1️⃣ 所有渗透测试仅针对 本地授权靶机环境
2️⃣ 技术演示均在 获得书面授权的模拟平台 完成
3️⃣ 坚决抵制任何未授权渗透行为
技术资料获取
如需完整实验代码、工具配置详解及靶机搭建指南:
👉 请关注微信公众号 「零日破晓」
后台回复关键词 【博客资源】 获取独家技术文档包
法律追责提示
对于任何:
✖️ 盗用文章内容
✖️ 未授权转载
✖️ 恶意篡改原创声明
本人保留法律追究权利。

















 5644
5644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









