




 本文介绍了DQN算法及其存在的经验浪费和相关更新问题,提出了经验回放作为解决方案,通过存储和随机抽样transition来打破序列相关性。进一步探讨了改进的经验回放——优先级重放,利用TD误差进行非均匀抽样,并通过学习率变换平衡训练。这种方法提高了样本效率,尤其适用于深度强化学习中的高效训练。
本文介绍了DQN算法及其存在的经验浪费和相关更新问题,提出了经验回放作为解决方案,通过存储和随机抽样transition来打破序列相关性。进一步探讨了改进的经验回放——优先级重放,利用TD误差进行非均匀抽样,并通过学习率变换平衡训练。这种方法提高了样本效率,尤其适用于深度强化学习中的高效训练。
强化学习—— 经验回放(Experience Replay)
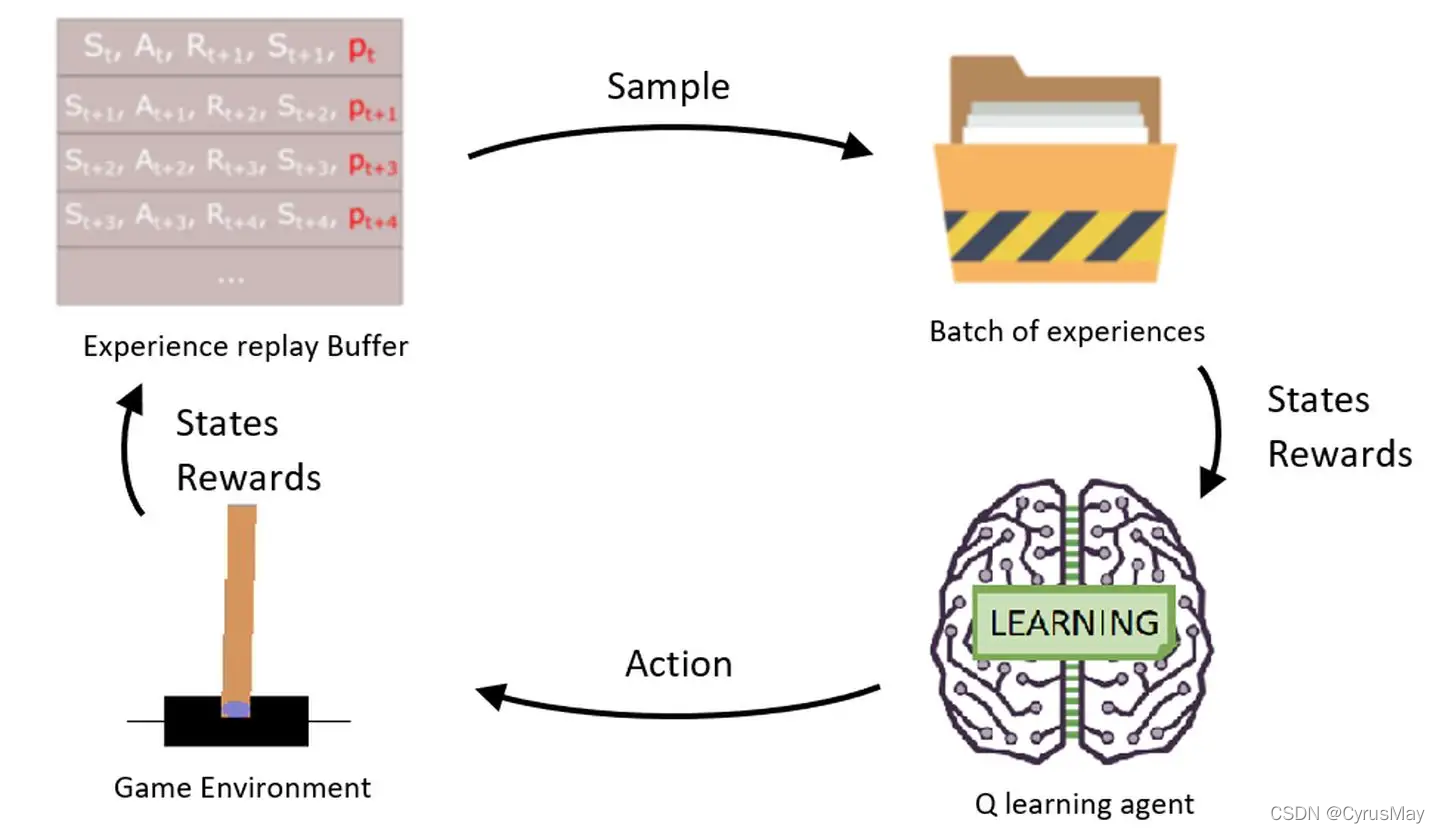
1、DQN的缺点
1.1 DQN
- 近似最优动作价值函数: Q ( s , a ; W ) ∼ Q ⋆ ( s , a ) Q(s,a;W)\sim Q^\star (s,a) Q(s,a;W)∼Q⋆(s,a)
- TD error: δ t = q t − y t \delta_t=q_t-y_t δt=qt−yt
- TD Learning: L ( W ) = 1 T ∑ t = 1 T δ t 2 2 L(W)=\frac{1}{T}\sum_{t=1}^{T} \frac{\delta_t^2}{2} L(W)=T1t=1∑T2δt2
1.2 DQN的不足
1.2.1 经验浪费
- 一个 transition为: ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)
- 经验(所有的transition)为: { ( s 1 , a 1 , r 1 , s 2 , ) , . . . ( s t , a t , r t , s t + 1 ) , . . . , s T , a T , r T , s T + 1 } \{(s1,a1,r1,s2,),...(s_t,a_t,r_t,s_{t+1}),...,s_T,a_T,r_T,s_{T+1}\} { (s1,a1,r1,s2,),...(st,at,rt,st+1),...,s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5579
5579




 到【灌水乐园】发言
到【灌水乐园】发言







