



首先下载压缩包,解压将.py文件和.csv文件放在已建好的shp要素文件(可存在多个)同一目录下

打开.csv文件对应修改为自己需要的格式,具体如下:
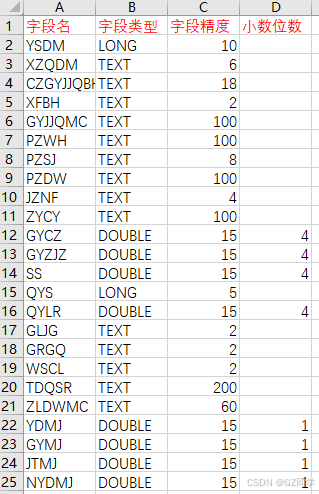


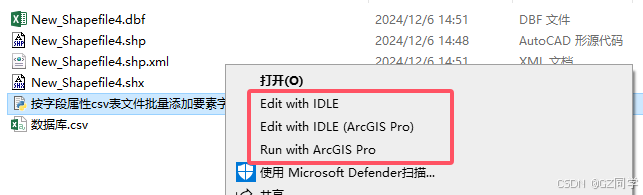
修改好数据库.csv文件后,.py文件右键打开菜单,红框均可运行(Edit打开后按F5运行),运行一段时间后文件夹内所有.shp均添加需要的字段
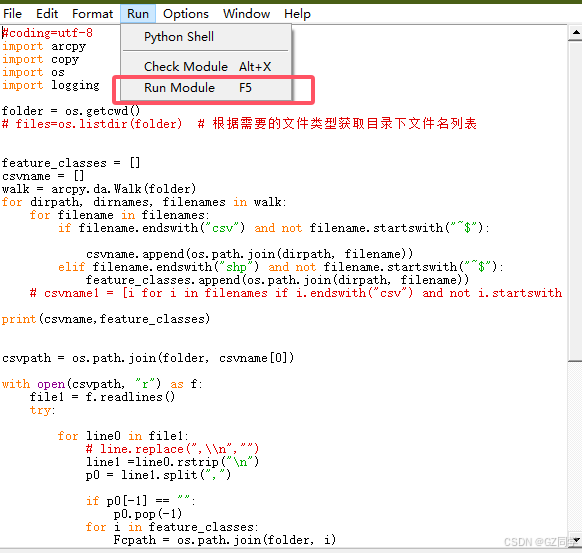
窗口运行等待2分钟后可以看到shp文件已有新建字段

源代码:(arcgis10.x或arcgisPro版arcpy均可使用),如有交流想法或指正请联系q775915005
#coding=utf-8
import arcpy
import copy
import os
import logging
folder = os.getcwd()
# files=os.listdir(folder) # 根据需要的文件类型获取目录下文件名列表
feature_classes = []
csvname = []
walk = arcpy.da.Walk(folder)
for dirpath, dirnames, filenames in walk:
for filename in filenames:
if filename.endswith("csv") and not filename.startswith("~$"):
csvname.append(os.path.join(dirpath, filename))
elif filename.endswith("shp") and not filename.startswith("~$"):
feature_classes.append(os.path.join(dirpath, filename))
# csvname1 = [i for i in filenames if i.endswith("csv") and not i.startswith("~$")]
print(csvname,feature_classes)
csvpath = os.path.join(folder, csvname[0])
with open(csvpath, "r") as f:
file1 = f.readlines()
try:
for line0 in file1:
# line.replace(",\\n","")
line1 =line0.rstrip("\n")
p0 = line1.split(",")
if p0[-1] == "":
p0.pop(-1)
for i in feature_classes:
Fcpath = os.path.join(folder, i)
if p0[1] == "TEXT":
arcpy.AddField_management(Fcpath, field_name=p0[0], field_type=p0[1], field_length=p0[2])
else:
if len(p0) == 2:
arcpy.AddField_management(Fcpath, field_name=p0[0], field_type=p0[1])
elif len(p0) == 3:
arcpy.AddField_management(Fcpath, field_name=p0[0], field_type=p0[1], field_precision=p0[2])
elif len(p0) == 4:
arcpy.AddField_management(Fcpath, field_name=p0[0], field_type=p0[1], field_precision=p0[2], field_scale=p0[3])
except arcpy.ExecuteError:
print(arcpy.GetMessages())
except Exception as ex:
print(ex.args[0])






















 到【灌水乐园】发言
到【灌水乐园】发言







