




目录
前言
推进深度学习向前发展的三驾马车分别为:1. 数据集;2. 计算机的算力;3. 深度学习算法。然而,随着人工智能和深度学习算法在各个领域的应用取得显著的成效,对优质的数据集的要求越来越高,但现在主流的数据集仍然是关于纯计算机领域的应用,所以,选择好的数据集进行跨领域的迁移学习尝试也是计算机视觉(CV)领域常用的可行性方法。由于工程领域没有大范围公开的可用数据集,无法进行大面积的自主应用。
一、各类数据集简介
数据集种类来源(Openmmlab开源算法库):https://github.com/open-mmlab/mmsegmentation
1. Cityscapes数据集
Cityscapes即城市景观数据集,是现在语义分割领域常用的大规模数据集,其中包含一组不同的立体视频序列,记录在50个不同城市的街道场景。
城市景观数据集中针对城市街道场景的语义理解,该大型数据集包含来自50个不同城市的街道场景,还包含不同季节,背景以及同一天不同时间段的街景样式,除了20000个弱注释帧以外,还包含5000帧高质量像素级注释。因此,数据集的数量级要比以前的数据集大的多。Cityscapes数据集共有fine和coarse两套评测标准,前者提供5000张精细标注的图像,后者提供5000张精细标注外加20000张粗糙标注的图像。 Cityspaces官方网站:https://www.cityscapes-dataset.com/
Cityspaces官方网站:https://www.cityscapes-dataset.com/
2. PASCAL VOC数据集
PASCAL VOC(全称:The Pattern Analysis, Statical Modeling and Computational Learning Visual Object Classes)是一项由欧盟资助的世界级别计算机视觉挑战赛事,开始于2005年,现在已经停止举办,但是研究人员仍然可以在其服务器上提交预测结果来评估自己的模型性能。PASCAL VOC从举办开始,每年的内容都有所不同,从最开始的分类,到后面逐渐增加检测,图像分割,人体布局,动作识别(Object Classification 、Object Detection、Object Segmentation、Human Layout、Action Classification) 等内容,数据集的容量以及种类也在不断增加和改善。该项挑战赛催生出一大批优秀的计算机视觉模型(尤其是以深度学习技术为主的)。所以,对于该数据集的图片类型就比较多样化可能包含日常用品物体,猫狗动物以及风景照片等等。

PASCAL VOC数据集的可下载镜像网站:https://pjreddie.com/projects/pascal-voc-dataset-mirror/
3. ADE20K数据集
ADE20K数据集(全称:ADE20K Scene Parsing Challenge)是一个用于场景解析并覆盖了从室内到室外、自然到城市等各种不同的场景的大规模数据集,它包含了超过20,000个标注图像,用于图像语义分割任务。每个图像都经过了详细的标注,将图像中的每个像素进行了语义分类,共包含了150个不同的语义类别,如人、车辆、植物、建筑物等。该数据集旨在推动计算机视觉领域的研究和发展,特别是在场景理解和图像分割方面。可为各种应用提供支持,例如智能驾驶,图像编辑,数据增强等方面。

ADE20K官网:https://groups.csail.mit.edu/vision/datasets/ADE20K/
4. Pascal Context数据集
Pascal Context数据集是一个基于Pascal VOC 2010 检测任务挑战的进一步扩展,该数据集包含了10103幅图片组成的训练集(每幅图片都打有像素级的标签),它总共包含了540种分类(其中包括了Pascal VOC 2010数据集中包含的20种分类加上背景类)。这540种分类又被划分为三种类别(Objects, stuff, hybrids)。尽管这个数据集含有大量的类别,但也仅有59种是被研究者们用得最多的。

Pascal Context官网:https://paperswithcode.com/dataset/pascal-context
5. COCO数据集
COCO数据集(全称是Microsoft Common Objects in Context),起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
COCO数据集是一个大型的、丰富的针对物体检测,分割和字幕的数据集。这个数据集以场景理解(scene understanding)为目标,其主要从复杂的日常场景中截取。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33万张图片,其中20万张有标注,整个数据集中个体的数目超过150 万个。

COCO数据集下载:https://cocodataset.org/#download
6. CHASE_DB1数据集
Chasedb1是一个轻量的用于视网膜血管分割的图像数据集。其用于识别和自动分类关键的视网膜特征,分析视网膜血管形态与视网膜及全身性疾病的关系,以便在疾病处于早期阶段时得到及时检测和治疗。
Chasedb1数据集官网:https://blogs.kingston.ac.uk/retinal/chasedb1/
7. DRIVE数据集
DRIVE (全称:Digital Retinal Images for Vessel Extraction) 是一个常用的眼底图像数据集,用于研究视网膜血管分割算法。该数据集包含了40个具有挑战性的视网膜图像,其中20个用于训练,另外20个用于测试。每张图像的大小为565×584像素,并且包含手动标注的视网膜血管。这些标注提供了血管的位置和形状信息,可以用于训练和评估血管分割算法。DRIVE数据集在医学图像处理领域被广泛使用,是许多血管分割算法的基准数据集之一。
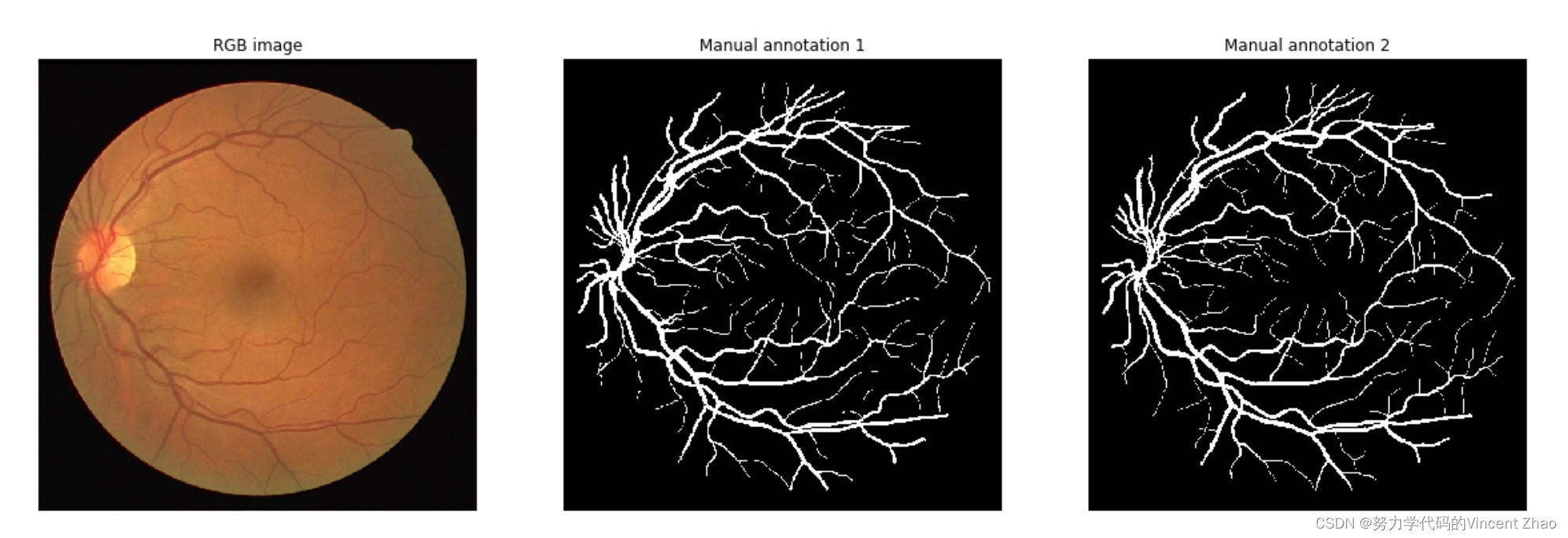
DRIVE数据集数据集官网:https://drive.grand-challenge.org/
8. HRF数据集
HRF(全称:High-Resolution Funds)数据集包含15例健康患者的图像,15例糖尿病性视网膜病变患者的图像和15例青光眼患者的图像。每个图像都有二进制标准血管分割标签图像。此外,该数据集还提供了FOV。标准血管分割标签数据是由视网膜图像分析领域的专家小组以及合作的眼科诊所的临床医生产生的。该数据集的图像尺寸为3504 × 2336。该数据集已经提供了images和annotations两个目录结构,相应的图片和标注也已经放在里面,可以直接进行训练了。
HRF数据集官网:https://www5.cs.fau.de/research/data/fundus-images/
9. STARE数据集
STARE(视网膜结构分析)项目是由加州大学圣地亚哥分校的医学博士迈克尔·戈德鲍姆于1975年构想并发起的。它在2000年由Hoover等首次在论文中引用并公开,是用来进行视网膜血管分割的彩色眼底图数据库, 包括20幅眼底图像, 其中10幅有病变,10幅没有病变, 图像分辨率为605×700,每幅图像对应 2 个专家手动分割的结果, 是最常用的眼底图标准库之一。但是其自身的数据库中没有掩膜,需要自己手动设置掩膜。目前它已扩展到40幅血管分割手工标注结果和80幅视神经检测手工标注结果。
STARE数据集下载:https://paperswithcode.com/dataset/stare
10. Dark Zurich数据集
Dark Zurich是一个图像数据集,包含在夜间、黄昏、白天拍摄的共计 8,779 张图像,以及每张图像对应的相机GPS坐标。这些GPS标注可用于构建具有时间跨度的对应,如将夜晚或黄昏时拍摄的图像,与白天对应的图像进行匹配。

Dark Zurich数据集:https://paperswithcode.com/dataset/dark-zurich
11. Nighttime Driving数据集
Nighttime Driving 数据集由夜间和黄昏时的真实驾驶场景图像组成,包括 35,000 张未标注图像和 50 张密集标注的图像。该数据集有助于学习和评价夜间驾驶场景的语义分割方法。

Nighttime Driving数据集:https://paperswithcode.com/dataset/nighttime-driving
12. LoveDA数据集
LoveDA数据集是武汉大学测绘遥感信息工程国家重点实验室RSIDEA团队在地表覆盖分类方面的工作,已被NeurIPS 2021 Datasets and Benchmarks Track接收。在大规模高分地表覆盖制图任务中,城市和农村发展不同与地理环境差异限制深度网络的泛化性。LoveDA数据集包含来自三个不同城市的5987张0.3m高分辨率影像和166,768个标注语义对象。LoveDA数据集包含两个领域(城市和农村),这带来了相当大的挑战:1)多尺度对象;2)复杂的背景样本;3)不一致的样本分布。LoveDA 数据集适用于土地覆盖语义分割和无监督域适应(UDA)任务。因此,我们在11种语义分割方法和8种域自适应方法上对 LoveDA 数据集进行了基准测试。

LoveDA数据集:https://paperswithcode.com/dataset/loveda
13. Potsdam数据集
Potsdam包含28幅相同size的图像,顶层影像和DSM的空间分辨率为5 cm。与Vaihingen区域类似,该数据集也是由3个波段的遥感TIFF文件和单波段的DSM组成。其每幅遥感图像区域覆盖大小是相同的。这样,遥感图像和DSM是在同一个参考系统上定义的(UTM WGS84)。每幅图像都有一个仿射变换文件,以便在需要时将图像重新分解为更小的图片。


Potsdam数据集:https://www.isprs.org/default.aspx
14. Vaihingen数据集
Vaihingen数据集包含33幅不同大小的遥感图像,每幅图像都是从一个更大的顶层正射影像图片提取的,图像选择的过程避免了出现没有数据的情况。顶层影像和DSM的空间分辨率为9 cm。遥感图像格式为8位TIFF文件,由近红外、红色和绿色3个波段组成。DSM是单波段的TIFF文件,灰度等级(对应于DSM高度)为32位浮点值编码。

Vaihingen数据集:https://www.isprs.org/default.aspx
15. iSAlD数据集
iSAlD数据集该数据集与著名的遥感旋转框目标检测数据集同由武汉大学夏桂松团队维护。iSAID包含15类,共655,451个目标实例,图像数量达到2,806张,单张图像中实例数量最高可达8,000个,平均为239个,是遥感领域第一个大型实例分割数据集。iSAID使用DOTA数据集中的图片进行像素级标注,改正了DOTA数据集中存在标注错误,相比于DOTA中188,282个目标实例,iSAID所提供的样本量和标注精细程度大大增加,基本涵盖了城市遥感解译的关键目标。所标注图片的1/2被作为训练集,1/6用于验证集,1/3用于测试集,其中训练和验证集同时放出图片和GT标注,测试集只有图片可以下载。官方已设置测评服务器,可用于在线评测算法在测试集上的性能。
 iSAlD数据集:https://paperswithcode.com/dataset/isaid
iSAlD数据集:https://paperswithcode.com/dataset/isaid
16. MapillaryVistas数据集
MapillaryVistas数据集是世界上新建立最大、最多样化的像素精确,和特定实例标注的街道级图像公开数据集。其包括25000张高分辨率的彩色图像,分成66个类,其中有37个类别是特定的附加于实例的标签。对物体的标签注释可以使用多边形进行稠密,精细描绘。相对于Cityscapes的精细注释总量本MapillaryVistas数据集大5倍,并包含来自世界各地在各种条件下捕获的图像,包括不同天气,季节和时间的图像。

MapillaryVistas数据集:https://paperswithcode.com/dataset/mapillary-vistas-dataset
17. LEVIR-CD数据集
LEVIR-CD数据集是一个新的大型遥感建筑变化检测数据集。引入的数据集将成为评估变化检测(CD)算法的新基准,尤其是那些基于深度学习的算法。LEVIR-CD由637个非常高分辨率(VHR,0.5米/像素)的谷歌地球(GE)图像补丁对组成,大小为1024×1024像素。这些时间跨度为5-14年的双时态图像具有显著的土地利用变化,尤其是建筑业的增长。LEVIR-CD涵盖各种类型的建筑,如别墅住宅、高层公寓、小车库和大型仓库。在这里,我们关注与建筑相关的变化,包括建筑的增长(土壤/草地/硬化地面或在建建筑到新的建筑区域的变化)和建筑的衰落。
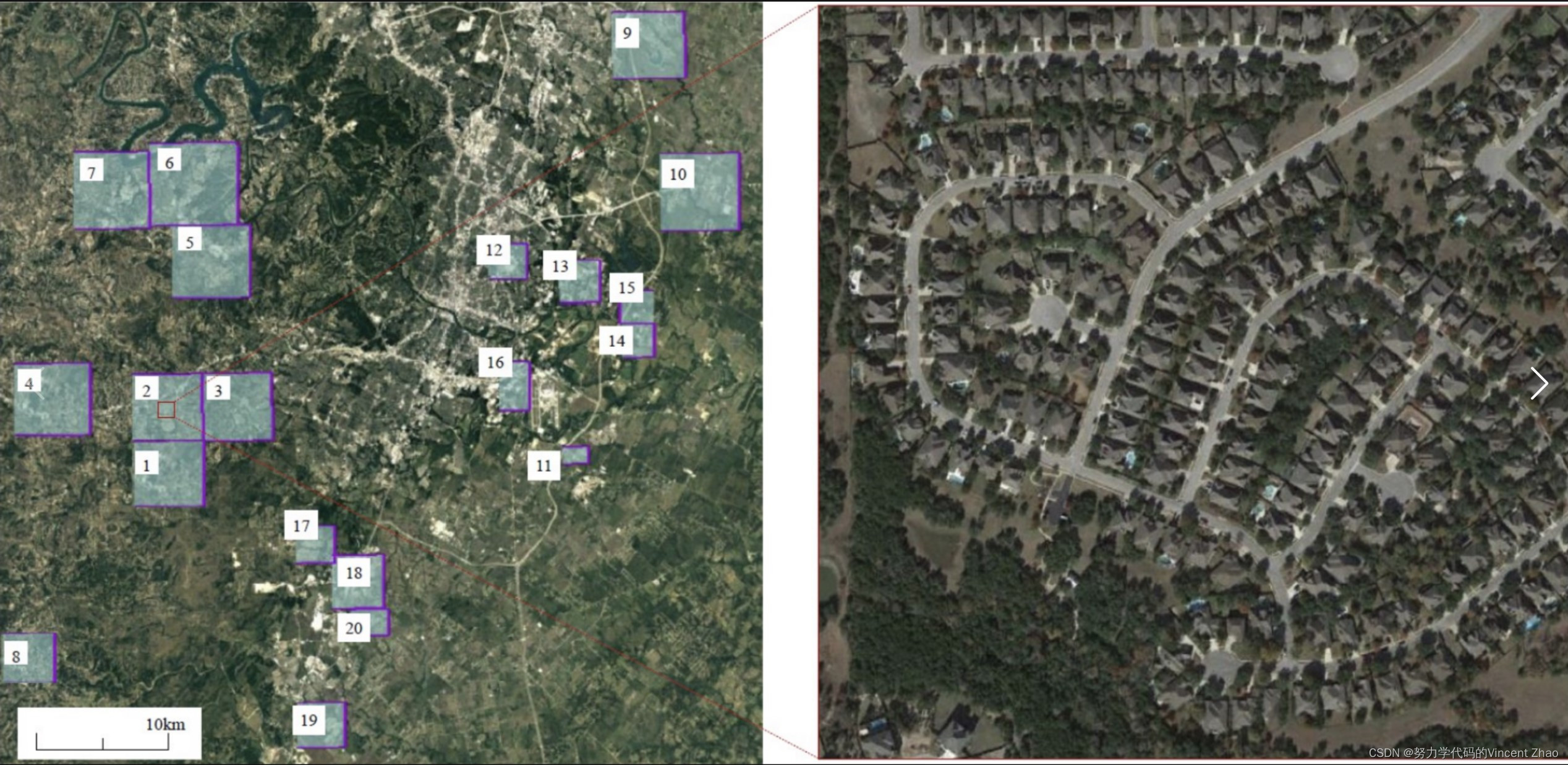
LEVIR-CD数据集:https://chenhao.in/LEVIR/
18. BDD100K数据集
BDD100K 数据集由加州大学伯克利分校于2018年发布发布,该数据集为迄今规模最大、最多样的自动驾驶数据集之一。其包含的 10 万个高清视频序列,时长超过 1100 小时。其中,每个视频大约 40 秒长、720p、30 fps,还附有手机记录的 GPS/IMU 信息和时间戳,以显示大概的驾驶轨迹。

BDD100K 数据集:https://doc.bdd100k.com/download.html
19. NYU2数据集
NYU2数据集有含有1449张RGBD图像,这些图像中包含464个不同的室内场景。图像是由微软Kinect的RGB和Depth相机拍摄的视频序列.同时,这些图像数据中的每个对象都被标注过。

NYU2数据集:https://paperswithcode.com/dataset/dark-zurich
总结
本文一共总结了图像语义分割的主要应用领域:室内外场景、汽车驾驶、医学图像以及遥感图像领域。而对于平面几何特点比较明显的数据集大致为ADE20K、Potsdam以及Vaihingen数据集,因为在建筑的遥感图像中的简单的几何形状比较突出也适用于本研究的开展。


















 1416
1416



 到【灌水乐园】发言
到【灌水乐园】发言








