 OmniNWM:自动驾驶世界模型新标杆
OmniNWM:自动驾驶世界模型新标杆





上海交通大学等机构联合提出全能驾驶导航世界模型,在生成质量与控制精度上全面超越现有SOTA!
目录
自动驾驶技术的发展正面临着一个关键瓶颈:如何在虚拟环境中进行高效、安全的训练与测试?传统的仿真平台虽然能够提供基本的测试场景,但在真实性、复杂性和交互性方面仍存在明显不足。近日,上海交通大学、东方理工大学、PhiGent Robotics、新加坡国立大学和清华大学的联合团队提出了OmniNWM(Omniscient Driving Navigation World Models),为这一挑战提供了全新的解决方案。

论文链接:
https://arxiv.org/pdf/2510.18313
项目主页:
https://arlo0o.github.io/OmniNWM/
代码链接:
https://github.com/Ma-Zhuang/OmniNWM
三大核心挑战:现有世界模型的局限性
当前自动驾驶世界模型虽然在视频生成方面取得了进展,但在构建鲁棒且通用的闭环仿真系统时,仍面临三大核心挑战:
-
状态(State)的局限性:现有模型大多依赖单一模态的RGB视频,且生成长度有限,无法捕捉真实驾驶场景的完整几何与语义复杂性。
-
动作(Action)的模糊性:现有方法采用稀疏的动作编码(如轨迹路点),难以实现对全景视频的精确、多视角一致操控,面对分布外轨迹时泛化能力不足。
-
奖励(Reward)的缺失:大多数世界模型缺乏集成、统一的奖励机制,难以在复杂驾驶环境中提供精确评估。
OmniNWM的核心创新:三位一体的统一架构
OmniNWM的创新之处在于将状态生成、动作控制、奖励评估三者无缝集成在一个统一框架中:
-
全景多模态生成:四模态联合输出
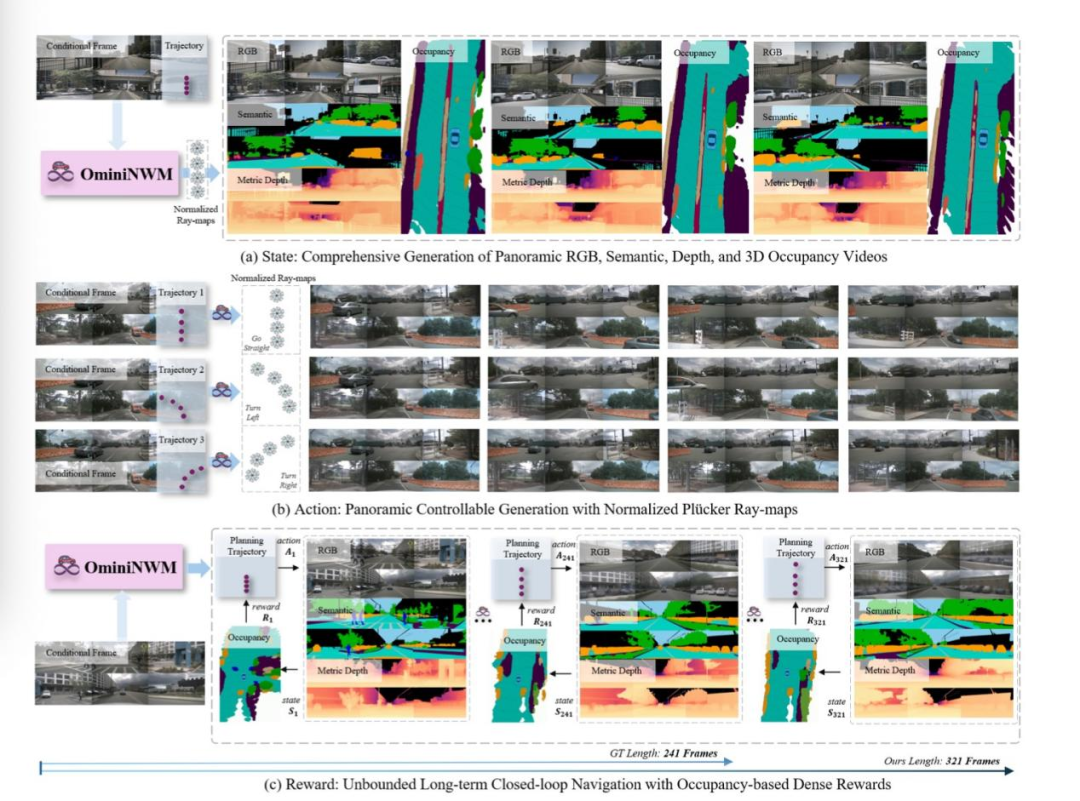
OmniNWM首次实现了RGB、语义图、度量深度图、3D语义Occupancy的像素级对齐联合生成:
使用Panoramic Diffusion Transformer (PDiT)作为主干网络
共享解码器确保跨模态一致性
通过SE3D Block + Outer Product技术从2D信息生成3D Occupancy
这种方法不仅提供了丰富的环境感知信息,更为后续的奖励计算奠定了基础。
-
归一化Plücker Ray-map:精准控制新范式
传统方法依赖稀疏轨迹点控制生成,难以实现精准操控。OmniNWM创新性地提出了归一化全景Plücker Ray-map:
将输入轨迹编码为稠密的射线场,提供像素级引导信号
通过尺度归一化和位姿归一化构建统一的Plücker空间
支持零样本迁移至不同数据集和相机配置
实验显示,该方法控制精度极高(RotErr仅1.42×10⁻²,接近GT水平),且能生成各种OOD(分布外)轨迹,如急转弯、倒车等复杂驾驶行为。


-
内生稠密奖励:基于Occupancy的合规性评估
OmniNWM无需外部模型,直接利用生成的3D Occupancy定义稠密奖励函数:
碰撞惩罚:检测与障碍物的碰撞,高速碰撞惩罚更重
越界惩罚:检测车辆是否驶出可行驶区域
速度奖励:鼓励符合交通规则的行驶速度
这种基于规则的奖励机制为自动驾驶策略的评估和优化提供了可解释、可微分的评估标准。
-
长时序生成:Flexible Forcing策略
为突破现有模型生成长度的限制,OmniNWM引入了Flexible Forcing策略:
在训练时对每帧、每视角的潜在表示施加独立噪声
支持帧级和片段级两种自回归推理模式
能够生成远超训练数据长度的稳定视频序列(从241帧扩展到321帧)
OmniNWM-VLA:语义-几何联合推理的规划智能体
为实现真正的闭环仿真,团队还开发了专用的Vision-Language-Action(VLA)规划器——OmniNWM-VLA:
基于Qwen-2.5-VL构建,针对自动驾驶场景进行增强
核心是Tri-Modal Mamba-based Interpreter(Tri-MIDI)融合模块
能够理解多模态环境、推理驾驶意图,并输出高精度轨迹
实验验证:全面超越现有SOTA
在多项实验中,OmniNWM展现出卓越性能:
-
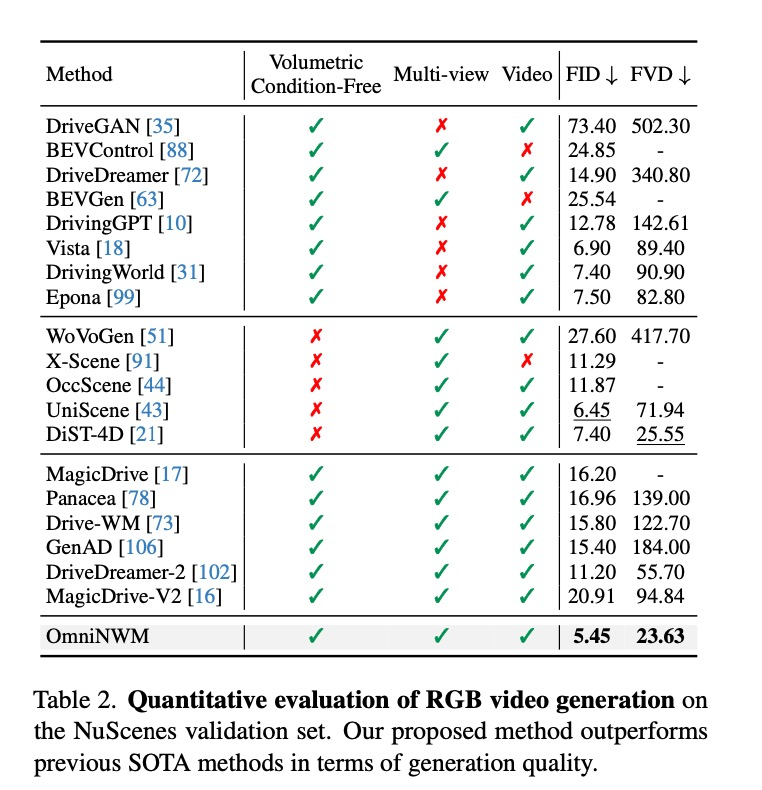
视频生成质量:在FVD、LPIPS等指标上全面领先,无需Occupancy或点云条件仍超越所有SOTA。
-
深度图生成:以生成的方式,超越所有SOTA的预测类Occupancy模型。
-
3D Occupancy预测:仅用RGB输入,超越部分LiDAR方法。
-
相机控制精度:归一化全景Plücker Ray-map全方位提升控制精度。
-
闭环规划评估:Scenario Pass Rate (SPR)显著提升,奖励分布更集中于高分区域。
-
零样本泛化:可无缝迁移到nuPlan与内部数据集,支持不同相机数量配置。
实际应用场景
OmniNWM具有广泛的应用前景:
-
长时间导航:能够生成超过GT长度的连续驾驶场景,支持长期行为规划。
-
轨迹控制:精准控制车辆执行直行、转弯等动作,甚至处理OOD轨迹。
-
多场景生成:基于3D语义占用生成多样性的场景视频,包括RGB、语义和深度信息。
-
跨平台适配:支持不同数据集和相机配置的零样本生成,提高模型适用性。
总结
OmniNWM首次在状态、动作、奖励三大维度实现统一,为构建高保真、可交互、可评估的自动驾驶世界模型树立了新标杆。
其核心贡献包括:
-
四模态联合生成:RGB/语义/深度/Occupancy的像素对齐输出
-
归一化Plücker Ray-map:实现像素级精准、零样本泛化的相机控制
-
Occupancy内生稠密奖励:支持可解释、可微的闭环评估
-
Flexible Forcing策略:突破数据集长度限制的长时序生成
这项工作不仅推动了自动驾驶仿真技术的前沿,也为未来自动驾驶系统的训练、测试和验证提供了强大工具。随着虚拟世界仿真能力的不断提升,自动驾驶的终极答案或许真的会来自这些高度逼真的虚拟环境。



















&spm=1001.2101.3001.5002&articleId=153958571&d=1&t=3&u=6527ec87dfeb4a10a70a8a2d335d95be)
 1773
1773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









