




无需精确标注,照样能get细致入微的深度图
你是否曾经想过,如果AI能像人类一样,仅通过观看视频就理解场景的远近关系,那该有多酷?
最近,一项名为 Jasmine 的研究给出了令人惊喜的答案——它首次将大名鼎鼎的Stable Diffusion(稳定扩散)模型成功引入自监督单目深度估计领域,不仅训练时不依赖昂贵的深度标注数据,还在多个权威数据集上实现了最先进的性能表现,甚至在零样本泛化能力上超越了以往所有模型!
背景:当自监督遇见扩散模型
单目深度估计,顾名思义,就是让机器从单张图片中推测出每个像素点的距离远近。传统方法要么依赖激光雷达等传感器获取精确的深度标签(成本高昂),要么采用自监督方式,利用视频序列中相邻帧之间的几何约束进行学习。
自监督方法虽然数据好找,但也存在天生短板:遮挡、无纹理区域、光照变化等问题容易导致预测结果模糊、失真,严重影响细节还原。
另一方面,Stable Diffusion等扩散模型凭借强大的视觉先验知识,在图像生成任务中表现出色。最近一些研究尝试将其用于深度估计,但无一例外都需要高精度的深度标签进行监督训练——这显然违背了我们“低成本学习”的初衷。
那么问题来了:有没有办法让SD模型在不接触精确深度标签的情况下,依然保持其强大的细节感知与泛化能力?
Jasmine的回答是:有,而且我们做到了!

Jasmine的“独门秘籍”
-
混合批次图像重建(MIR):左右手互博术
自监督学习中,由于遮挡等问题,模型容易接收到带有噪声和伪影的监督信号,这些“脏数据”会污染SD模型原本清晰的视觉先验。
Jasmine提出了一个巧妙的解决方案:让SD模型在学习深度估计的同时,也学习重建图像本身。具体来说,模型在每个训练批次中交替处理两类图像:真实的驾驶场景(如KITTI)与高质量合成图像(如Hypersim),并利用光度重构损失来约束重建效果。
这样一来,合成图像帮助模型“记住”SD原本清晰的先验知识,真实图像则保证几何结构的一致性。两者交替训练,既保护了SD的先验,又提升了深度估计的鲁棒性。
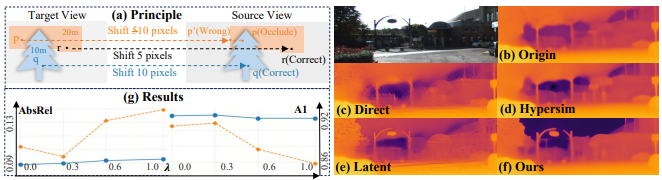
-
尺度-平移门控循环单元(SSG):分布对齐的翻译官
SD模型预测的深度是尺度-平移不变的,而自监督框架理论上只能学习尺度不变的深度。这两者之间存在天然的分布差异。
Jasmine设计了一个基于GRU的尺度-平移变换模块(SSG),通过迭代优化逐步将SD输出的深度分布对齐到自监督所需的分布上。更重要的是,SSG中的重置门机制还能过滤掉来自自监督信号的噪声梯度,保护SD输出的细节不被破坏。
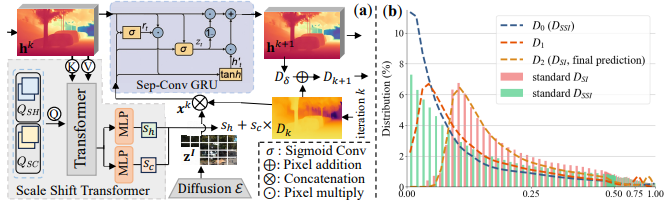
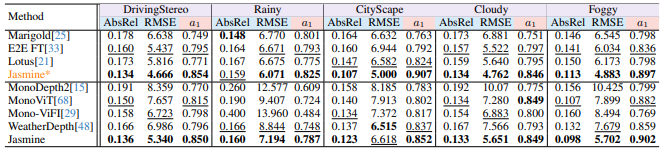
实验结果:不只是SOTA,更是细节控
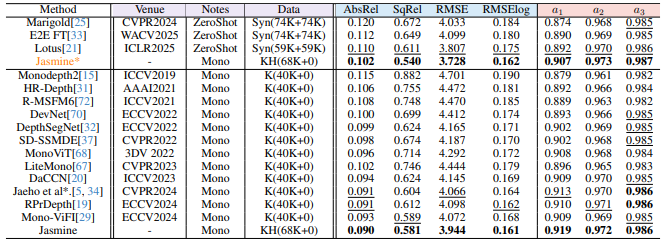
Jasmine在KITTI数据集上取得了所有自监督方法中的最佳性能,尤其在衡量整体准确率的a1指标上提升显著。更令人印象深刻的是其零样本泛化能力:
-
在CityScapes、DrivingStereo等多个外部数据集上,Jasmine均表现优异;
-
即使在雨天等非训练天气条件下,模型也能准确识别水面反射,并给出精细的深度估计;
-
对行人轮廓、树枝细节、自行车与骑手边界等复杂结构的还原度远超以往方法。
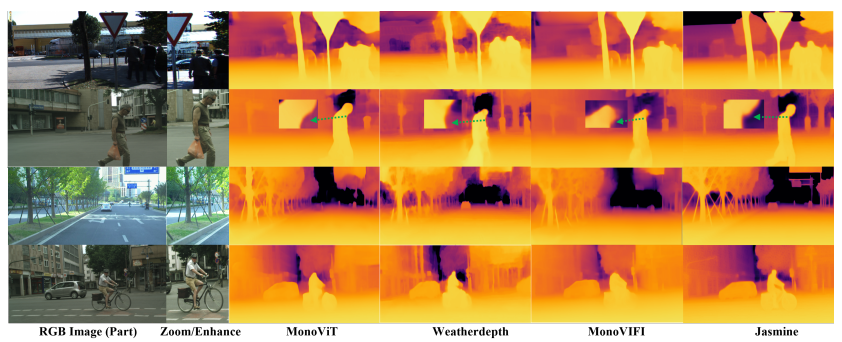
总结
Jasmine的成功不仅在于技术上的创新,更在于它为自监督学习与扩散模型结合开辟了一条新路径。它证明了:
即使没有高精度标注,我们依然可以借助SD模型的强大先验实现高质量的密集预测;
通过巧妙的训练策略和模块设计,可以克服自监督与预训练模型之间的分布差异;
未来在深度补全、深度超分、多视角立体视觉等任务中,这种无监督微调范式具有巨大潜力。
论文作者也坦言,目前Jasmine仅在数万张驾驶数据上训练,未来如果扩展到更大规模、更多样化的视频数据中,或许真的会迎来“3D感知的GPT时刻”。
代码链接:https://github.com/wangjiyuan9/Jasmine
如果你也对“让AI从视频中自学深度”感兴趣,不妨保持关注,或许下一个突破就来自你的idea!



















 1503
1503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









