



作者 | Bohan Li 来源 | 我爱计算机视觉
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文

论文标题: OmniNWM: Omniscient Driving Navigation World Models
作者: Bohan Li, Zhuang Ma, Dalong Du, Baorui Peng, Zhujin Liang, Zhenqiang Liu, Chao Ma, Yueming Jin, Hao Zhao, Wenjun Zeng, Xin Jin
机构: 上海交通大学, 东方理工大学(宁波), PhiGent, 新加坡国立大学, 清华大学
论文地址: https://arxiv.org/abs/2510.18313
代码仓库: https://github.com/Arlo0o/OmniNWM
自动驾驶的终极答案会来自虚拟世界吗?《OmniNWM》给出了一个激动人心的方向。这项研究提出了一个全景、多模态、带精确控制与内在奖励的驾驶导航世界模型,在生成质量、控制精度与长时序稳定性上全面超越现有SOTA,为自动驾驶的仿真训练与闭环评估树立了新标杆。
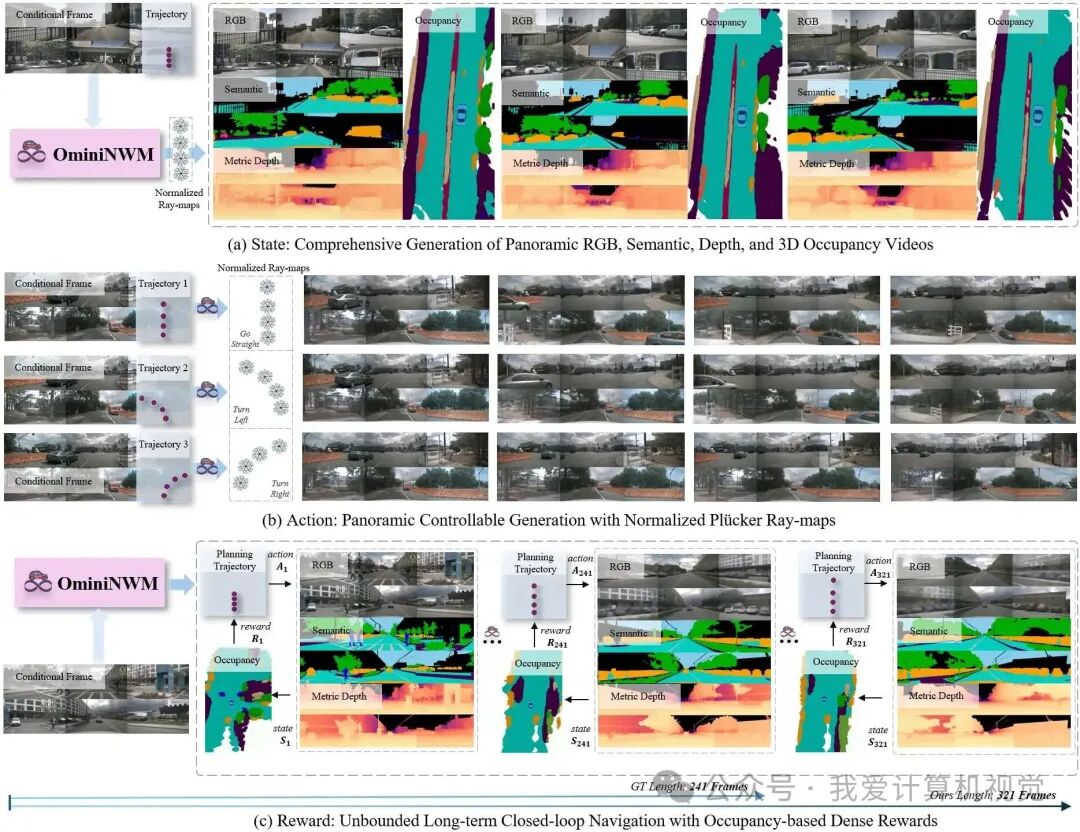
OmniNWM 的多种功能。
(a) 根据参考图像和输入轨迹,OmniNWM可联合生成全面的多模态输出,包括全景RGB、语义、深度和3D Occupancy视频。
(b) 以不同的输入轨迹为条件,OmniNWM 通过将其转换为归一化的Plücker Ray-map作为像素级指导,促进精确的全景相机控制。
(c) OmniNWM 可通过闭环管线实现无限制的长期导航:规划轨迹指导多模态生成,而密集奖励则来自生成的3D Occupancy。
超越GT长度的长时序自驾场景导航生成示例(与OmniNWM-VLA规划器相结合)


基于归一化Plücker Ray-map控制的OOD轨迹生成示例(control.gif / reverse.gif )
🌟 Motivation:突破驾驶世界模型的三大核心挑战
当前自动驾驶世界模型虽然在视频生成方面取得了显著进展,但在构建鲁棒且通用的闭环仿真系统时,仍然面临三大核心挑战:
状态(State)的局限性:现有模型大多依赖单一模态的RGB视频,且生成长度有限。这无法捕捉真实世界驾驶场景的完整几何与语义复杂性,对于需要多模态输入的下游任务和闭环评估来说是一个巨大瓶颈。
动作(Action)的模糊性:为了控制生成过程,现有方法通常采用稀疏的动作编码,例如轨迹的路点(waypoints)。这种方式难以实现对全景视频的精确、多视角一致的操控,并且在面对分布外(OOD)的轨迹时泛化能力受限。
奖励(Reward)的缺失:有效的奖励函数是评估和优化驾驶策略的关键。然而,大多数世界模型缺乏一个集成、统一的奖励机制。部分研究虽提出了基于外部图像模型的奖励函数,但这不仅增加了系统复杂度,也难以在复杂的驾驶环境中提供精确的评估。
❝
💡 核心洞察:一个真正有效的自动驾驶世界模型,必须在状态(State)、动作(Action)、奖励(Reward) 这三个维度上实现统一和协同。它不应仅仅是一个“视频生成器”,而必须是一个可交互、可评估、可扩展的综合性虚拟驾驶环境。
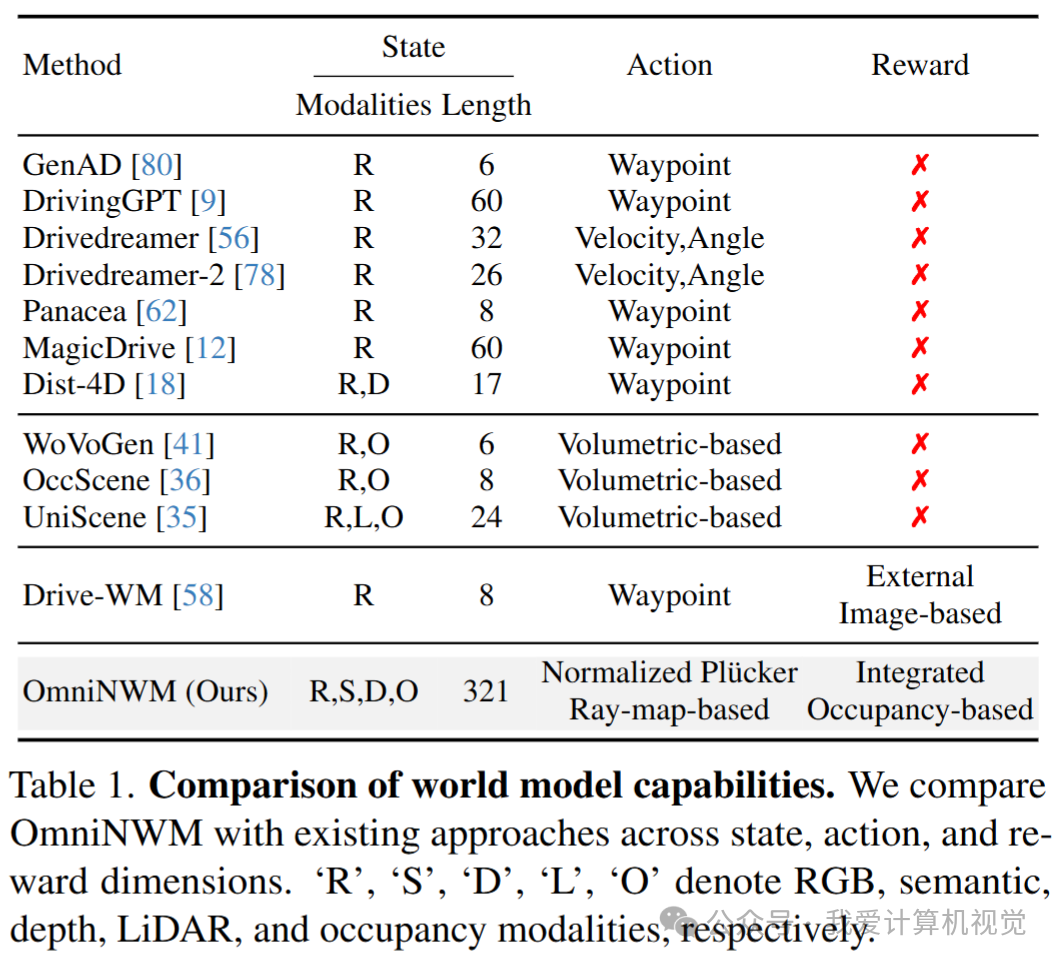 表1:OmniNWM 与现有世界模型在状态、动作、奖励三个维度的能力对比
表1:OmniNWM 与现有世界模型在状态、动作、奖励三个维度的能力对比
🧠 Method:三位一体的统一架构
针对上述挑战,OmniNWM 提出了一个创新的统一框架,其核心在于将状态生成、动作控制、奖励评估三者无缝集成。整体架构如下图所示,主要包含以下几个关键模块:
全景多模态生成 (State) :利用 Panoramic Diffusion Transformer (PDiT) 作为核心,联合生成像素级对齐的 RGB、语义、深度、3D Occupancy 四种模态的视频。
归一化Plücker Ray-map控制 (Action) :将输入的自我轨迹编码为稠密的、几何感知的 Plücker Ray-map,作为像素级引导信号,实现对全景相机生成的精准控制。
内生稠密奖励 (Reward) :直接利用生成的 3D Occupancy 来定义基于规则的稠密奖励函数,用于评估驾驶行为的合规性与安全性,从而支持闭环规划。
Flexible Forcing 长时序生成:引入一种灵活的噪声注入策略,使模型能够生成远超训练数据长度(例如从241帧扩展到321帧)的稳定视频序列。
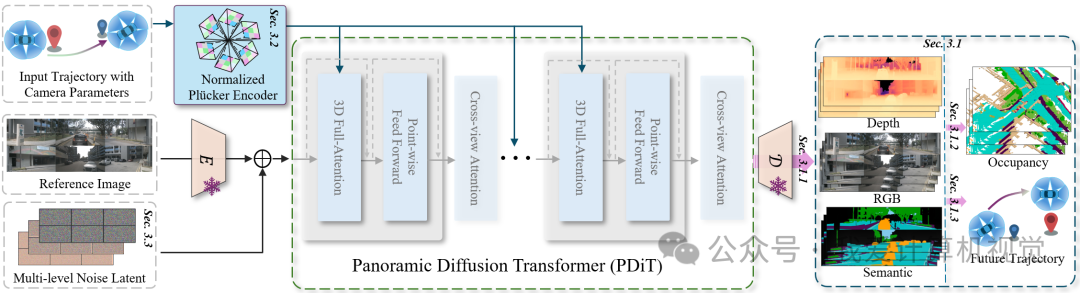
1 多模态状态生成:像素对齐的四模态联合输出
OmniNWM 首次实现 RGB、语义图、度量深度图、3D 语义 Occupancy 的联合生成,且四者在像素级别对齐。
🔹 架构设计
使用 Panoramic Diffusion Transformer (PDiT) 作为主干
对 RGB、语义、深度三模态分别编码为潜在变量
通道拼接后输入 PDiT 联合去噪:
共享解码器输出对齐的三模态视频
❝
✅ 训练技巧:语义图在 VAE 编码前进行伪彩色化,解码后通过最近邻匹配还原类别标签,确保跨模态一致性。
🔹 3D Occupancy 生成(用于奖励)
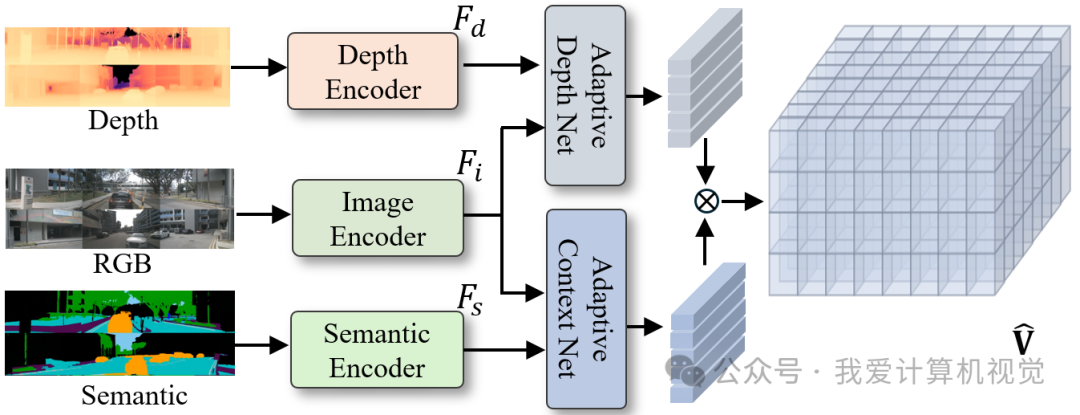
利用生成的 RGB、语义、深度图,通过 SE3D Block + Outer Product 生成 3D Occupancy:
其中:
:由 EfficientNet-B7 提取的 RGB 图像特征
:深度图与语义图经卷积下采样后的特征
:自适应聚合网络(SE3D Blocks)
:外积(outer product),融合几何与语义上下文
最终通过上采样 + Softmax 得到 3D 语义体素网格 。
❝
📌 意义:该 Occupancy 不仅用于可视化,更是奖励计算与闭环规划的核心依据。
2 动作控制:归一化全景 Plücker Ray-map
传统方法依赖稀疏的轨迹点(如 路点)控制生成,难以实现多视角几何一致的精准操控。OmniNWM 创新性地提出 归一化全景 Plücker Ray-map —— 一种像素级、几何一致、零样本泛化的动作表示,将输入轨迹转化为稠密的射线场指导生成过程。
🔹 Plücker 坐标定义
对第 个相机视角中像素 ,其 Plücker 嵌入为六维向量:
其中 为相机中心, 为从相机中心指向像素的世界射线方向。
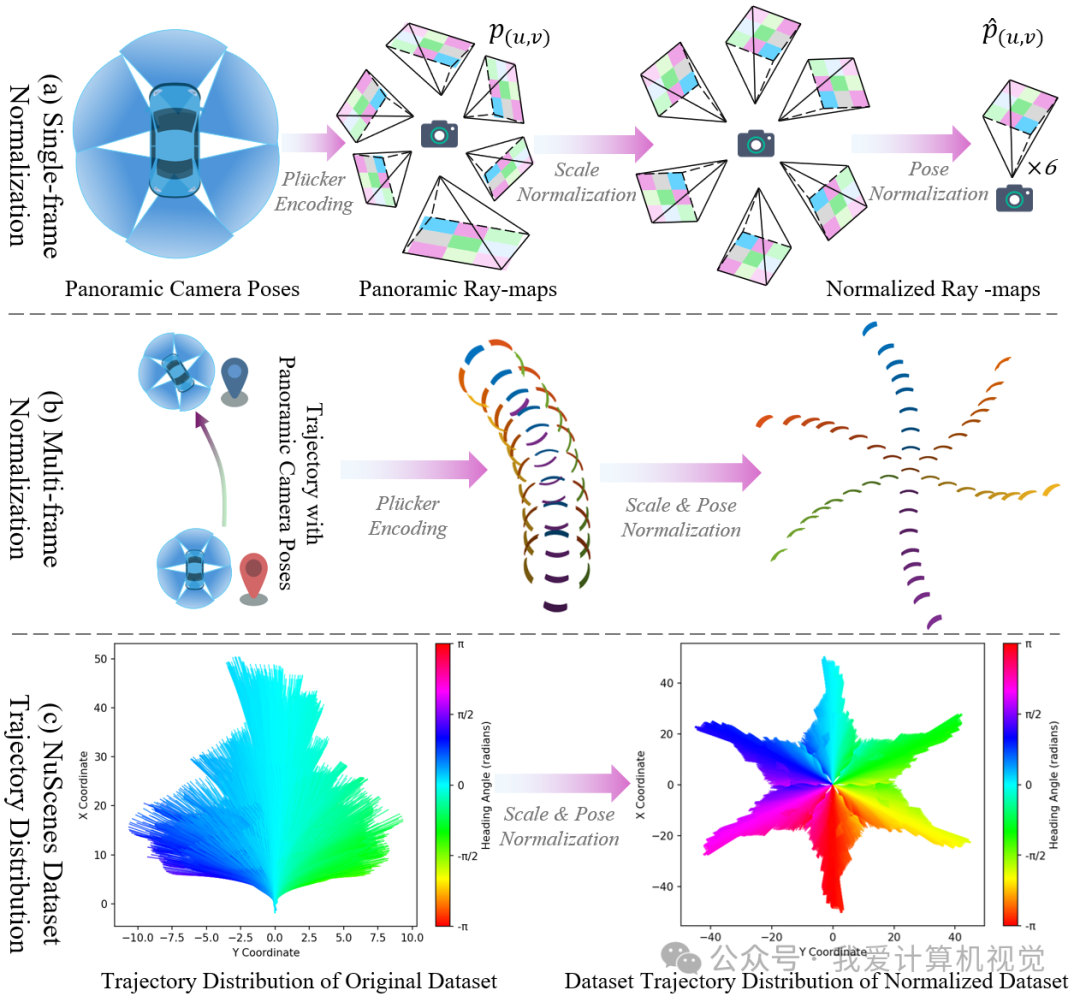
为支持跨数据集、多相机配置泛化,OmniNWM 对Ray-map进行双重归一化:
🔹 双重归一化:构建统一 Plücker 空间(对应图5(a)(b))
为支持跨数据集、多相机配置下的泛化能力,OmniNWM 对 Ray-map 进行 尺度归一化 与 位姿归一化:
尺度归一化(统一内参):统一使用前视相机内参 重投影所有视角射线,消除因相机焦距差异导致的尺度漂移;
其中 为前视相机内参,确保所有射线在同一度量尺度下。
位姿归一化(统一坐标系):将所有相机中心与射线方向变换至前视相机坐标系下。
最终归一化 Plücker 坐标为:
通过这一过程,不同相机视角、不同轨迹形态被映射到同一个几何一致的 3D Plücker 空间中(图5(b)),使得模型能以统一语义理解任意轨迹,显著提升控制泛化性。
🔹 轨迹多样性增强(对应图5(c))
原始 NuScenes 数据集中轨迹分布高度集中(如主干道直行),限制了模型对复杂驾驶行为(如急转弯、倒车、变道切入)的建模能力。OmniNWM 的归一化策略 解耦了轨迹几何与具体相机配置,使得在训练或推理时可轻松注入 OOD(Out-of-Distribution)轨迹(如图中 control.gif / reverse.gif 所示)。
实验表明,该策略显著扩展了有效轨迹的覆盖范围,轨迹分布多样性远超原始数据集(图5(c)),为仿真中的极端场景生成与策略鲁棒性训练奠定基础。
✅ 优势总结:
轻量、无参数、无需训练
支持 零样本迁移 至 不同数据集和不同相机数量等新配置
实现 像素级精准控制(RotErr 仅 1.42×10⁻²,接近 GT)
构建 统一动作语义空间,解锁丰富 OOD 轨迹生成能力
3 长时序生成:Flexible Forcing策略

为突破现有模型仅能生成较短帧数的限制,OmniNWM 支持超过GT长度的 321 帧超长序列生成。
🔹 多层级噪声注入
训练时对每帧 、每视角 的潜在表示 施加独立噪声:
其中:
:可学习缩放因子
🔹 两种推理模式
帧级自回归(Frame-level):
适用于逐帧规划
片段级自回归(Clip-level):
高效生成长视频(FVD@201帧 = 25.22,远优于消融模型 386.72)
❝
📊 效果:见下图,Flexible Forcing显著抑制长时序中的结构退化。

4 内生稠密奖励:基于 Occupancy 的驾驶合规性评估
OmniNWM 无需外部模型,直接利用生成的 3D Occupancy 定义稠密奖励:
🔹 三项奖励详解
碰撞惩罚(Collision Reward):
当 ego 车辆与 Occupancy 中障碍物(车、行人等)碰撞
高速碰撞惩罚更重
越界惩罚(Boundary Reward):
当车辆驶出 “drivable surface” 区域
速度奖励(Velocity Reward):
当速度超出
❝
🎯 验证:下图展示在“对向卡车”场景中,奖励函数能有效区分碰撞、避让不足、成功规避三种行为。

5 OmniNWM-VLA —— 语义-几何联合推理的规划智能体
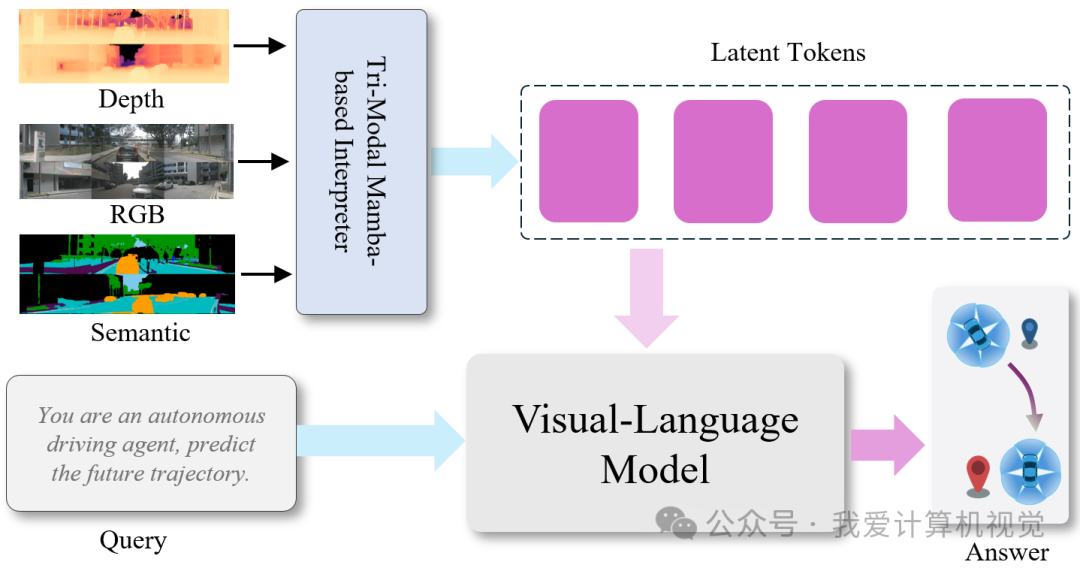
为实现真正的闭环仿真,OmniNWM 引入了一个专用的 Vision-Language-Action(VLA)规划器,命名为 OmniNWM-VLA。该模块基于强大的多模态大模型 Qwen-2.5-VL 构建,但针对自动驾驶场景进行了关键性增强,使其能够 理解多模态环境、推理驾驶意图,并输出高精度轨迹。
🧩 核心架构:Tri-Modal Mamba-based Interpreter(Tri-MIDI)
OmniNWM-VLA 的核心创新在于其 Tri-MIDI 融合模块——一个轻量、即插即用的 Mamba-based 多模态解释器,用于将 RGB、深度、语义三路输入统一编码为富含空间语义的潜在表示。 具体流程如下:
输入对齐
将生成的多视角 RGB 图像 、度量深度图 和语义分割图 拼接为统一的全景网格 ,确保跨视角空间一致性。模态独立编码
使用预训练编码器分别提取各模态特征:其中:
:CLIP 视觉编码器(处理 RGB)
:SigLIP 编码器(处理深度)
:SegFormer(处理语义)
统一嵌入与融合
通过模态特定 MLP 投影至共享空间:再由 Mamba 状态空间模型 进行跨模态融合(受文本查询 引导):结构化输出
借助 Tokenized Rationale(TOR)机制,在输出序列中插入特殊推理锚点,最终预测:2D 路点坐标
航向角
OmniNWM-VLA 采用 因果语言建模目标,将轨迹视为“动作序列”进行 next-token 预测:
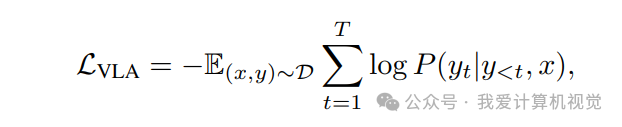
其中:
:Tri-MIDI 处理后的多模态输入(RGB+深度+语义)
:目标轨迹序列(含坐标与航向角)
:序列长度
该目标使模型既能继承 Qwen-VL 的世界知识,又能学习驾驶场景下的 时空连贯性与物理合理性。
📊 Experiment:全面 SOTA,闭环验证有效
🔸 视频生成质量
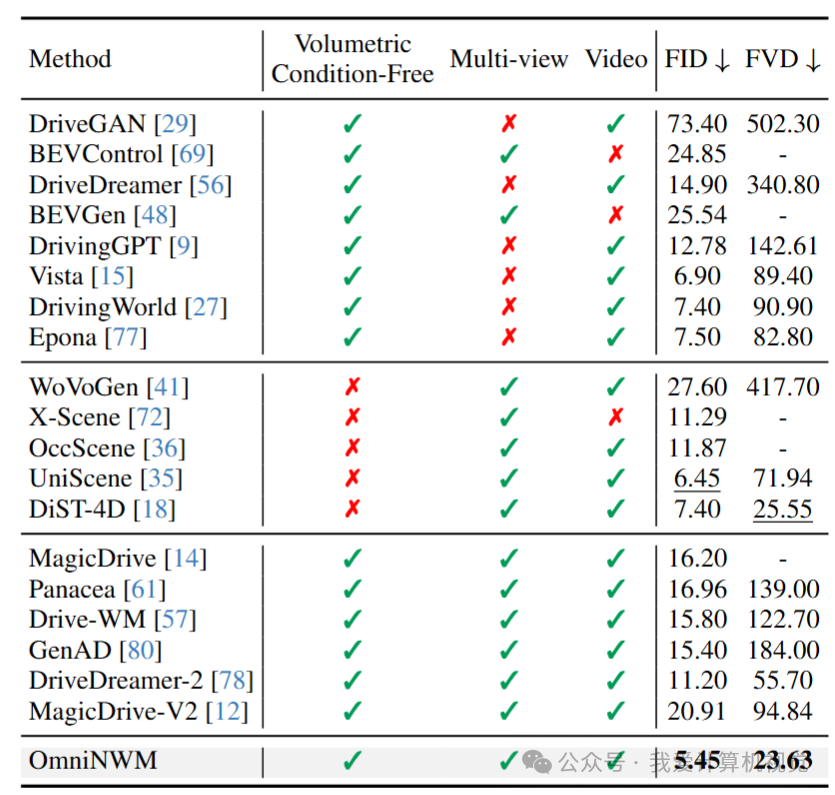
❝
✅ 关键:无需 Occupancy 或点云等体积条件,仍超越所有 SOTA。
🔸 深度图生成
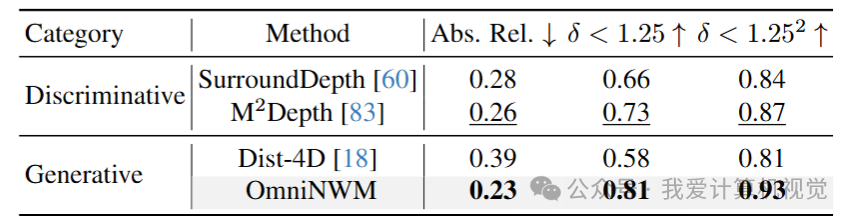
❝
✅ 关键:以生成的方式,超越所有SOTA的预测类Occupancy模型。
🔸 3D Occupancy 预测
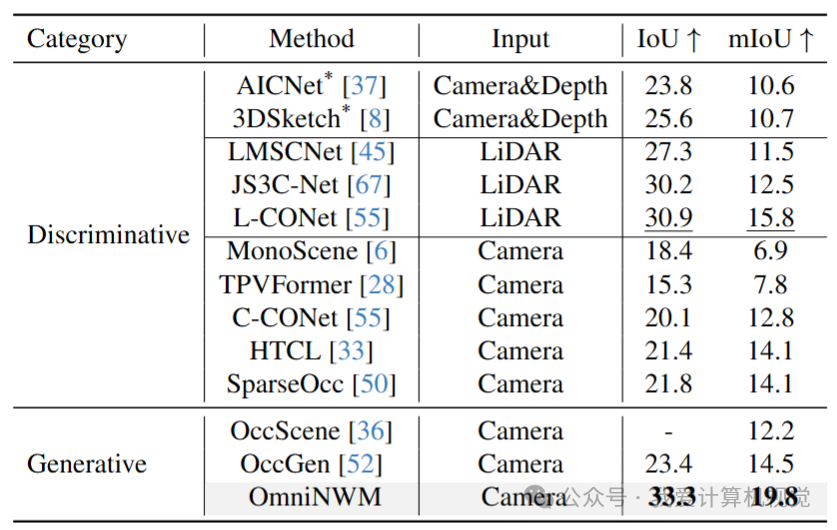
❝
🔥 突破:以生成的方式,仅用 RGB 输入,超越 LiDAR 方法。
🔸 相机控制精度
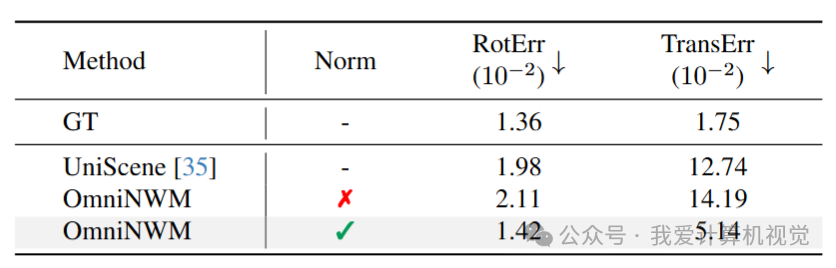
❝
🔥 突破:归一化全景 Plücker Ray-map,有效全方位提升控制精度。
🔸 闭环规划评估
通用集成性 OmniNWM支持直接集成各种VLA模块,以进行闭环评估。
Scenario Pass Rate (SPR) 显著提升
平均奖励 分布更集中于高分区域,证明奖励函数判别力强
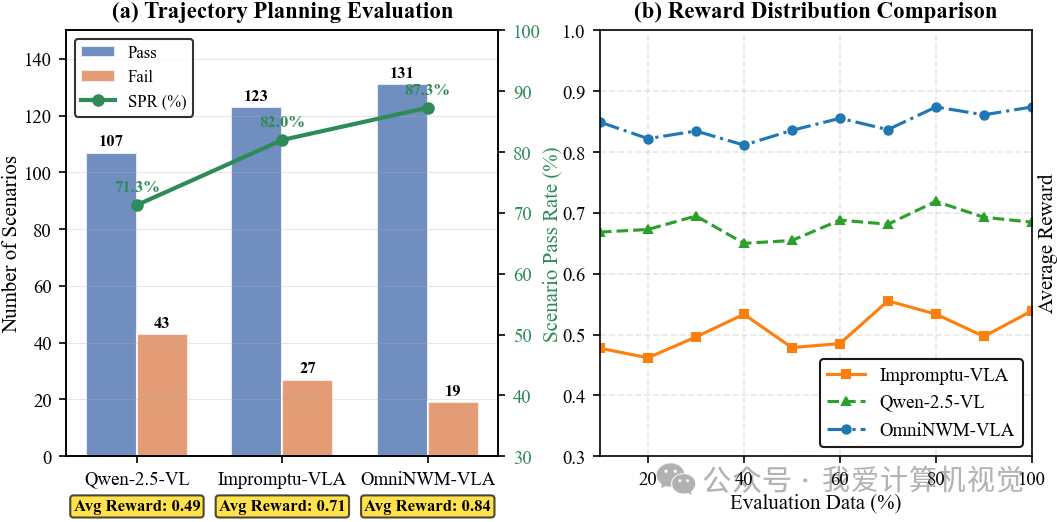
🔸 零样本泛化
无缝迁移到 nuPlan与In-House数据集
支持 不同相机数量 配置,无需微调直接采样

📌 总结
OmniNWM 首次在 状态、动作、奖励 三大维度实现统一,为构建高保真、可交互、可评估的自动驾驶世界模型树立了新标杆, 其核心贡献包括:
四模态联合生成(RGB/语义/深度/Occupancy),像素对齐、语义一致
归一化 Plücker Ray-map,实现像素级精准、零样本泛化的相机控制
Occupancy 内生稠密奖励,支持可解释、可微的闭环评估
Flexible Forcing策略,突破数据集视频长度限制的长时序生成(训练仅用到33帧长度的视频)
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频学习官网:www.zdjszx.com

















 5442
5442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









