




就在百度刚刚发布PaddleOCR-VL,以0.9B参数量重新定义文档解析效率之际,DeepSeek也正式开源了其颠覆性的DeepSeek-OCR模型。不过,它的野心远不止于“识别”,而是直指大模型处理长文本的核心痛点——如何用视觉token实现高效的“上下文光学压缩”。这或许将决定未来大模型的记忆边界与认知效率。
单块英伟达A100每天就能处理20万页数据,为大模型训练提供了前所未有的数据生成能力。
GitHub上的火爆程度印证了这一突破的重要性——DeepSeek-OCR项目一晚上就斩获超过4000个Star,成为近期最受关注的开源项目之一。
目录
一、为什么说这是颠覆性技术?
传统大模型处理长文本时面临“算力爆炸”难题——文本越长,计算量呈平方级增长。当处理数千甚至数万token的文档时,计算开销变得难以承受。
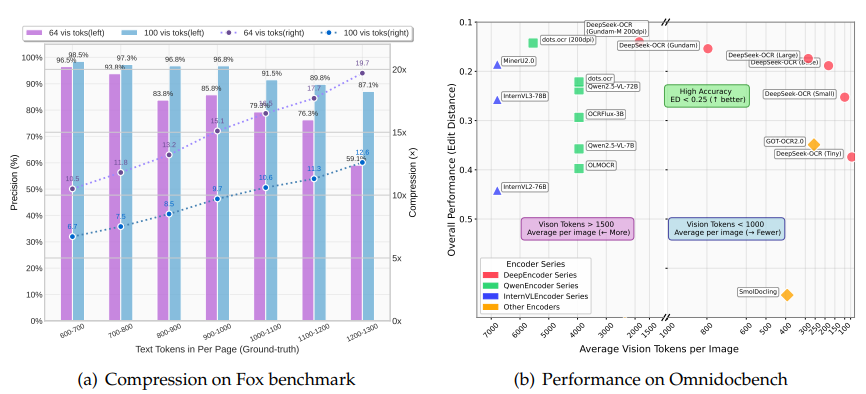
DeepSeek团队脑洞大开:既然一张图能顶千言万语,为什么不把文字“压缩”成图片来处理?实验证明,当文本token数量在视觉token的10倍以内时,模型解码精度高达97%;即使压缩率达到20倍,精度仍保持在60%左右。原本需要10,000个单词的文本,现在理论上只需约1,500个经过特殊压缩的视觉token即可完整表示。
这就好比聪明人读书可以“一目十行”,而不需要逐字阅读。DeepSeek-OCR正是让AI学会了这种高效的信息处理方式。
二、技术核心:两大组件实现“四两拨千斤”
-
DeepEncoder编码器 - 视觉压缩的核心引擎
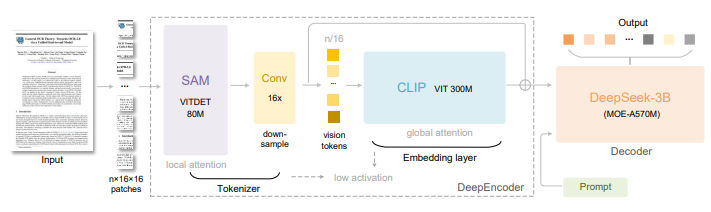
DeepEncoder采用创新的“先局部、再压缩、后全局”的三段式设计:
-
局部感知阶段:使用80M的SAM-base模型进行窗口注意力处理,生成大量视觉token
-
智能压缩阶段:通过16倍卷积压缩器大幅减少token数量(4096→256)
-
全局理解阶段:利用300M的CLIP-large模型深入理解压缩后的token
这种设计使得DeepEncoder能够在保持高分辨率输入的同时,产出极少的视觉token,支持从64token到800token的多分辨率模式。
-
DeepSeek3B-MoE解码器 - 文本重建专家
基于MoE架构,在推理时仅激活64个专家中的6个,加上2个共享专家,激活参数量仅570M。这种设计让模型在获得3B参数表达能力的同时,享受500M小模型的推理效率。
解码器的核心任务是从压缩的视觉token中精准还原文本表示,学习从视觉空间到文本空间的非线性映射。
三、性能表现:小模型的大能量
-
压缩能力惊艳
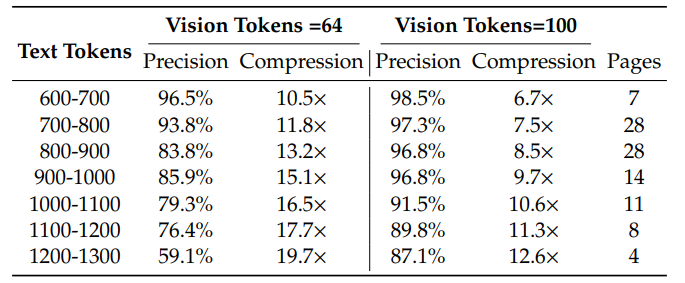
实验结果令人惊叹:
-
600-700文本token:10.5倍压缩,96.5%精度(64视觉token)
-
900-1000文本token:15.1倍压缩,85.9%精度(64视觉token)
-
1200-1300文本token:19.7倍压缩,59.1%精度(64视觉token)
-
实战表现卓越
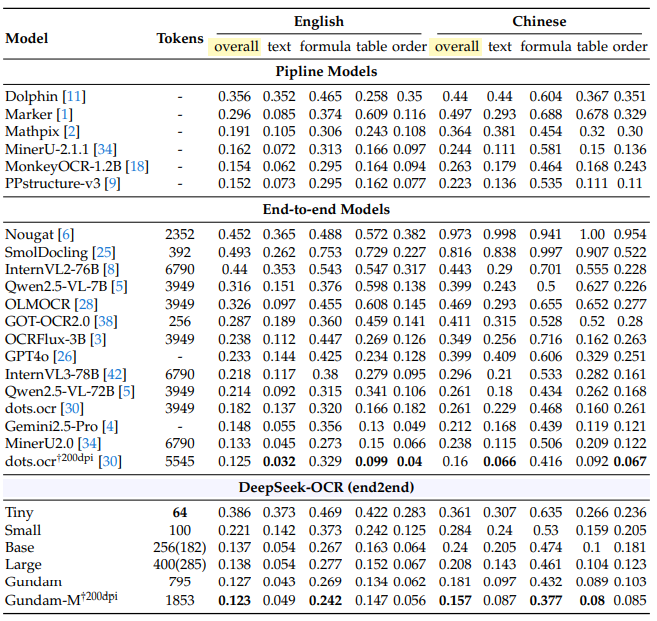
在OmniDocBench基准测试中:
-
仅用100视觉token:超越GOT-OCR2.0(256 token)
-
400视觉token:达到与SOTA模型相当的性能
-
不到800token:大幅超越MinerU2.0(近7000 token)
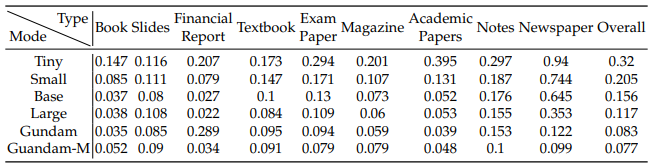
不同类型文档的需求差异显著:
-
幻灯片:仅需64token即可达到满意效果(编辑距离0.147)
-
书籍报告:100token就能取得良好表现
-
报纸:需要Gundam模式(795token)才能处理4000-5000文本token
四、生产效率:数据生成的“超级工厂”
在实际应用中,单张A100-40G显卡每天能生成20万+页训练数据,为LLM/VLM的大规模训练提供了强大支撑。使用20个节点(每个节点8张A100),每日处理能力达到3300万页!
-
企业知识管理:把公司的所有关键内部文档都塞进提示词前缀中并缓存,无需搜索工具就能快速查询
-
代码开发:将整个代码库放入上下文中缓存,每次修改时只需追加差异部分
-
研究助手:拥有大量领域知识并能随时调用,像著名物理学家Hans Bethe那样“从不需要中断去查阅资料”
如果与DeepSeek几周前发布的稀疏注意力机制DSA结合使用,模型的有效上下文窗口可能扩展到千万token级别。
五、更多惊喜能力
-
深度解析:超越传统OCR
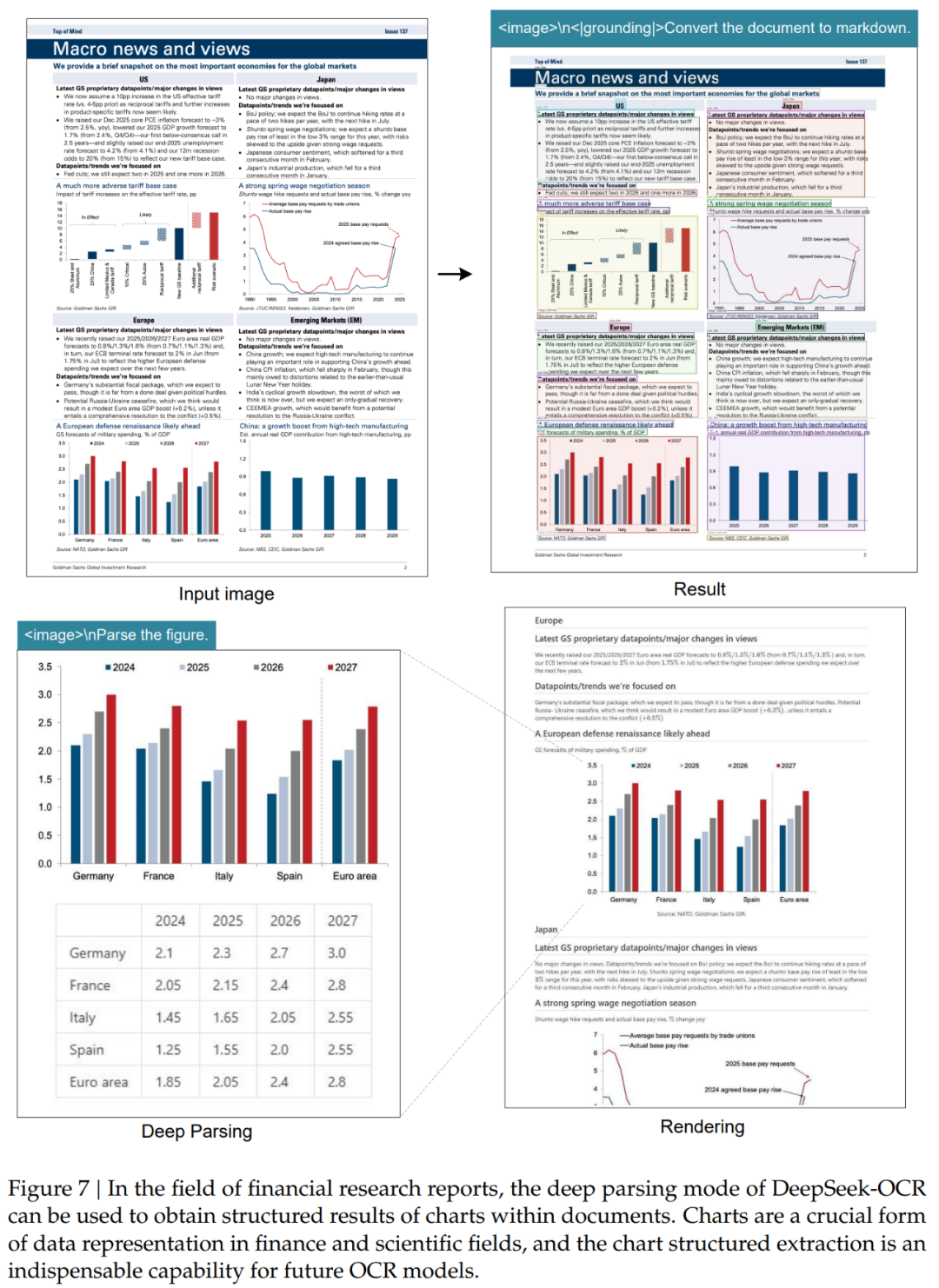



除了基础OCR,DeepSeek-OCR还具备深度解析能力:
-
金融图表:自动提取结构化数据
-
化学公式:准确识别分子结构
-
几何图形:解析线段关系和空间结构
-
自然图像:生成密集的图像描述
-
多语言支持与通用视觉理解


-
近100种语言支持,覆盖全球化数据需求
-
通用视觉能力:图像描述、目标检测、视觉定位
-
统一提示词控制,灵活切换不同功能
-
哲学思考:模拟人类记忆机制
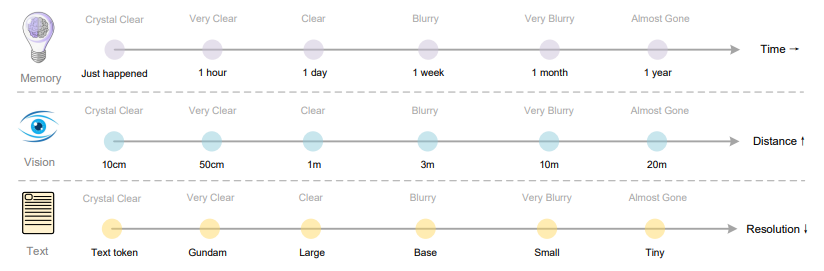
团队提出了一个深刻洞见:用视觉压缩模拟人类遗忘曲线。
-
近期记忆 → 高分辨率、高保真(更多token)
-
远期记忆 → 低分辨率、自然模糊(更少token)
这种机制为AI的长上下文处理提供了全新思路,让机器记忆更接近人类智能。通过渐进式压缩,实现了信息的自然衰减,完美平衡了信息保留与计算效率。
六、业界反响与未来展望
模型一经发布立即引爆社区GitHub迅速斩获4K星标,OpenAI联合创始成员、前特斯拉自动驾驶总监Andrej Karpathy给出了高度评价,并提出了更深刻的洞见:
“作为一个本质上是研究计算机视觉,暂时伪装成自然语言专家的人,我更感兴趣的是:对于大语言模型来说,像素是否比文本更适合作为输入?”
Karpathy指出,文本token在输入端可能是在浪费资源,甚至很糟糕。他大胆设想:“也许更合理的是,LLM的所有输入都应该是图像。即使你碰巧有纯文本输入,也许你更愿意先渲染它,然后再输入。”
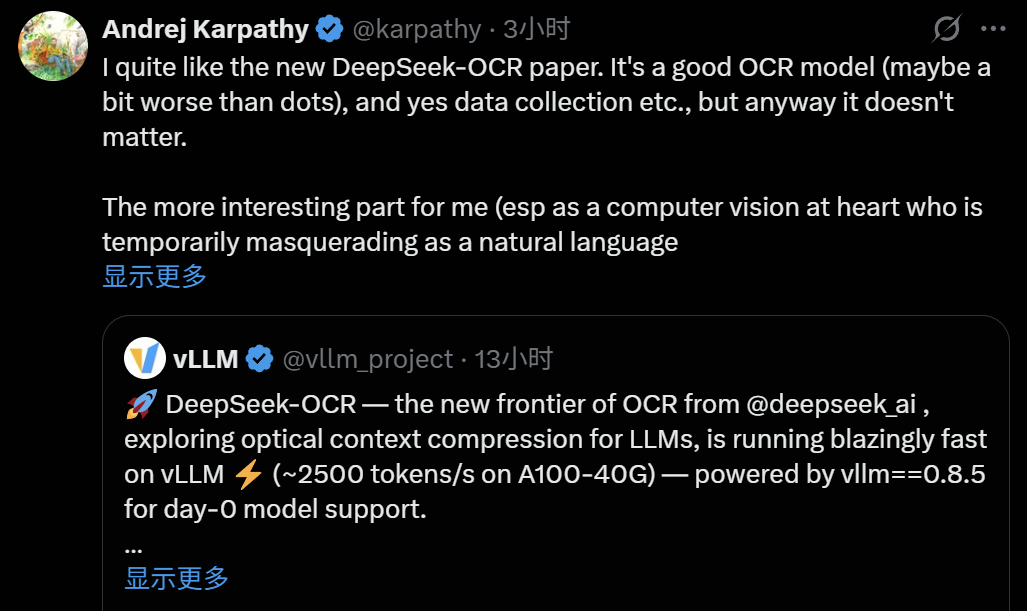
他列举了这种范式的多个优势:
-
更多信息压缩≥更短的上下文窗口,更高的效率
-
明显更为通用的信息流≥包括粗体文本、彩色文本、任意图像
-
能够使用双向注意力而不是自回归注意力
-
彻底删除输入端的分词器——这个他多次吐槽的“历史包袱”
Django Web框架的联合创建者Simon Willison展示了让Claude Code在英伟达Spark硬件上运行这个模型的完整过程——仅使用4个提示词,耗时仅40分钟。

许多专家认为,这不仅是OCR技术的突破,我们的大脑本就使用类似的视觉记忆表征机制,更是“视觉作为通用压缩媒介”这一范式的新高度。它为重新思考AI的信息处理方式提供了全新视角,或许是通往更智能AI系统的重要一步。
七、论文及项目地址
论文地址:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf代码仓库:https://github.com/deepseek-ai/DeepSeek-OCR模型下载:https://huggingface.co/deepseek-ai/DeepSeek-OCR




















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









