




【导读】
90%的YOLO模型性能问题源于数据准备不当!当你的检测模型在真实场景中漏检、误检或泛化失败时,问题可能不在算法本身,而是隐藏在数据预处理和增强的细节中。本文将拆解YOLO训练中最易被忽视的数据标准化核心步骤与增强策略的致命陷阱,用工业级实践告诉你:为什么同样的YOLOv8模型,别人的mAP比你高20%?>>更多资讯可加入CV技术群获取了解哦~
目录
-
预处理标准化和清理原始数据,确保其具有适合 YOLO 模型的最佳格式。
-
数据增强可以人为地扩展您的数据集,使模型更加稳健,并提高其在各种现实场景中的泛化能力。
-
仔细选择和调整预处理和增强技术至关重要;误用可能会导致计算成本增加、数据不切实际,甚至模型性能下降。
在开始训练自定义 YOLO(You Only Look Once,只看一次)模型之前,对数据预处理和数据增强的基本理解至关重要。这两个阶段并非纸上谈兵,而是直接影响模型鲁棒性、准确性以及泛化至未知数据能力的关键组成部分。
一、预处理:模型基石
预处理不是可选项,而是强制标准。它决定了数据与模型结构的兼容性,直接影响收敛效率。
-
图像尺寸处理
-
问题:YOLO要求固定输入尺寸(如640×640),但原始图像比例各异。
-
致命错误:直接拉伸导致物体形变(如圆形变椭圆),模型学习扭曲特征。
-
工业级方案:
-
Letterboxing:保持原比例,用灰边填充缺失区域(如图)
-
优势:保留物体真实形状,避免比例失真
-
代价:引入无效像素,小物体可能因下采样丢失(需平衡填充比例)
-
像素归一化
-
操作:将像素值从0-255线性缩放到[0,1]或[-1,1]
-
为何必须做:
-
消除量纲差异,防止大像素值主导梯度
-
加速收敛30%+(实测ResNet在ImageNet任务)
-
警告:推理时必须使用与训练相同的归一化参数!
-
色彩空间转换
-
典型事故:用OpenCV读图(BGR格式)直接输入模型(期望RGB)→ 颜色反向,检测失效
-
解决方案:一行代码解决image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
-
边界框同步
-
核心逻辑:图像变换时,边界框坐标需同比例同方式调整
-
灾难性后果:框与物体偏移 → 模型学习错误位置 → mAP暴跌
-
自动化工具推荐:Albumentations库(自动同步框与图像变换)
二、数据增强:低成本提升泛化
增强的本质是模拟现实世界的复杂性,但过度增强等于投毒!
-
几何增强
黄金法则:增强后人工检查边界框是否仍贴合物体!
-
光度增强
-
HSV调整:模拟昼夜/阴晴变化
-
亮度±30%:夜间→白天过渡
-
饱和度±20%:雾天场景模拟
-
高危禁区:
-
医疗影像(色素病变依赖颜色)
-
交通灯检测(红/绿不能失真)
-
马赛克增强
-
操作:四图拼接为复合场景(图例)
-
革命性价值:
-
单图训练→多物体交互学习
-
小目标检测性能提升40%(COCO实测)
-
实施要点:
# YOLOv5 马赛克增强伪代码
if random.random() < 0.5:
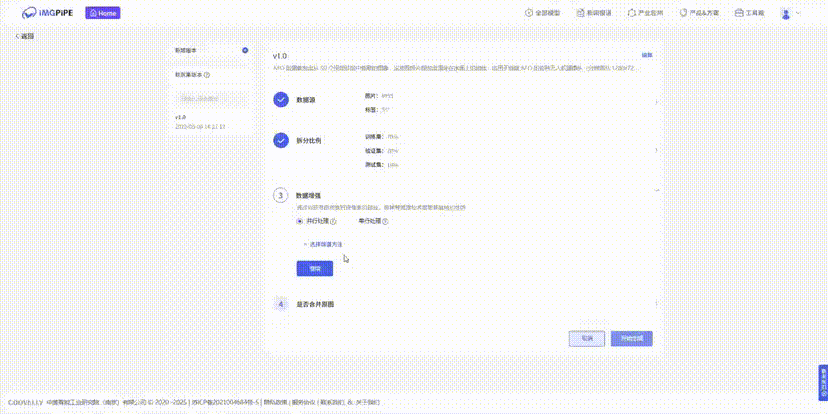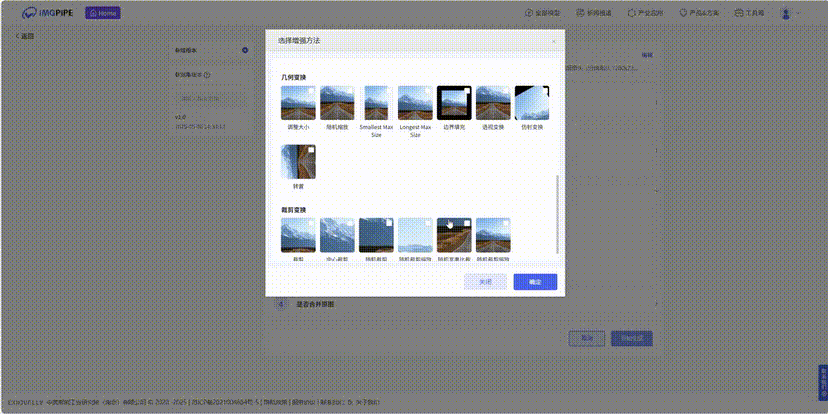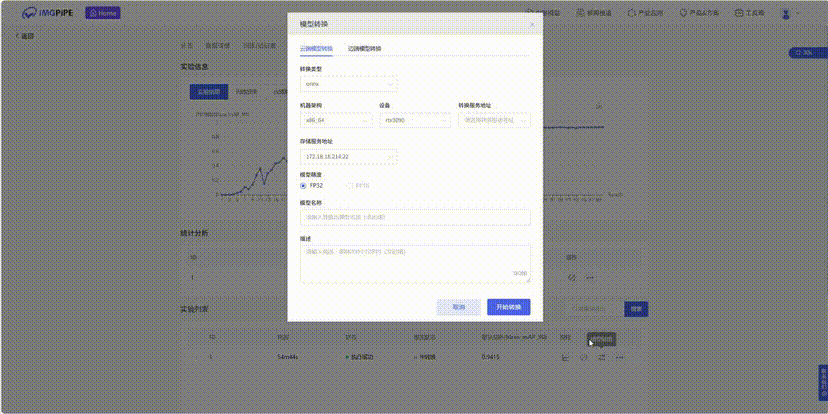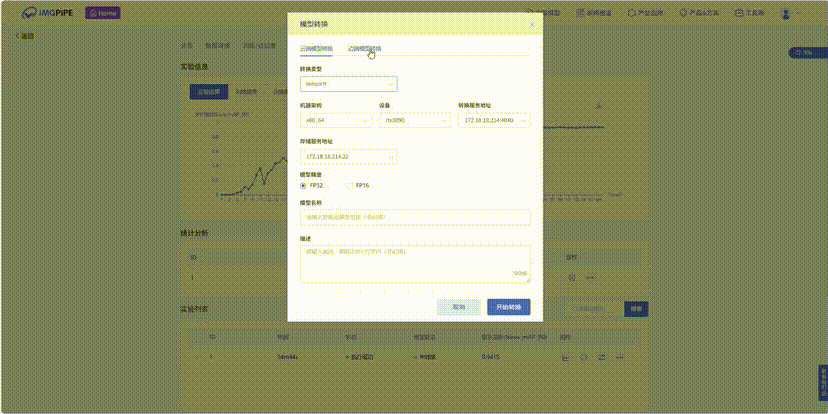
image, boxes = mosaic_4images(dataset)Coovally平台提供强大的数据增强功能,可以自由应用多样化的数据增强功能(如旋转、翻转、色彩调整、噪声添加等),有效扩充训练数据,从而显著提升模型的泛化能力、鲁棒性并降低过拟合风险,用户可通过直观配置轻松实现。
三、增强策略的平衡
-
增强不足 → 模型脆弱
-
现象:实验室mAP高,真实场景漏检频发
-
补救:增加光照扰动+小角度旋转
-
过度增强 → 学习噪声
-
典型案例:汽车旋转90°“立”在路上 → 模型混淆正常姿态
-
诊断工具:TensorBoard增强可视化插件
-
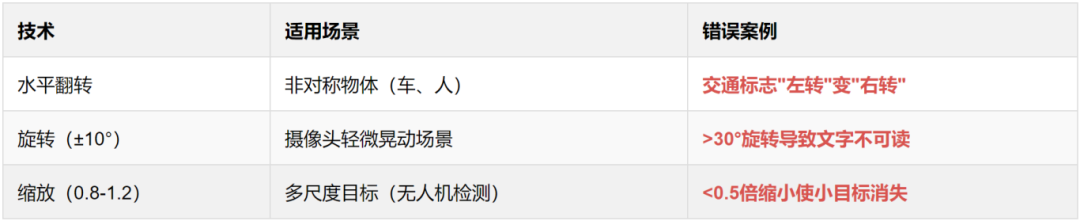
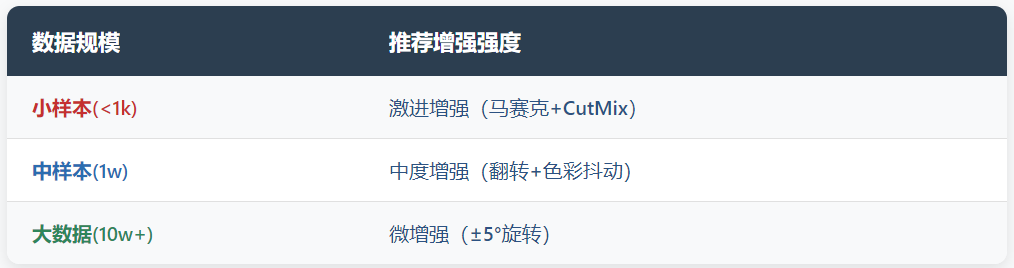
行业标准
四、避坑指南
-
标注错误的数据能否靠增强挽救?
✖ 绝对误区!增强只能扩展多样性,无法修正错误标签。
解决方案:先用Cleanlab工具自动检测标注错误
-
GPU不够强是否要砍掉增强?
优先保留几何轻量增强(翻转/平移),砍掉高耗能操作(马赛克/AutoAugment)
-
如何验证增强有效性?
关键指标:验证集mAP
-
增强后mAP提升 → 策略有效
-
mAP下降 → 立即检查边界框错位或失真
结语
在YOLO模型高度同质化的今天,精细化数据准备已成为核心壁垒。记住:
-
预处理是底线:Letterboxing+归一化+框同步缺一不可
-
增强需对症下药:医疗影像≠自动驾驶增强方案
-
可视化决定生死:增强后务必人工抽检边界框质量
你的模型精度,藏在每一张被正确处理的训练图像中。



















 3318
3318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









