




【导读】
在AI飞速演进的时代,计算机视觉(CV)早已不是“看图识物”那么简单了。作为CV领域的顶级学术盛会,CVPR 和 ICCV 这两大顶会的投稿数据和主题方向,堪称“风向标”级别的存在。
CVPR 2025 已公布最新投稿统计,ICCV 2025 也刚刚开启 rebuttal 环节。这一次,我们将带你看懂未来一年计算机视觉研究的三大热词,以及背后可能颠覆行业的趋势。>>更多资讯可加入CV技术群获取了解哦~
一、CVPR 2025 热门方向揭晓

CVPR 2025 共收到 13008 篇论文投稿,创下历史新高,最终接收 2878 篇,接收率仅为 22.1%。根据大会官方统计,今年最受关注的三个方向如下:
-
多视角与传感器的 3D 技术
从 NeRF(Neural Radiance Fields)火遍全网,到高斯泼溅(Gaussian Splatting)掀起神经渲染新潮流,计算机视觉已经从“2D 看图识物”全面迈入“3D 重建与理解”时代。
多视角图像结合多传感器数据,实现了对物体和场景更精准的三维重建,正在成为自动驾驶、AR/VR、数字孪生等应用的关键技术支柱。
-
图像与视频合成
今年AI最炙手可热的话题之一,就是图文生图、文本生视频的能力。CVPR 2025 中,图像与视频合成类论文数量创下新高。研究者正在探索生成内容如何更贴近物理世界、更具交互性。
从“AI生成威尔·史密斯吃意面”到“实时视频人物替换”,视觉合成技术正朝着生成完整虚拟世界迈进,为数字人、虚拟现实等领域打下坚实基础。
-
多模态学习:视觉×语言×推理
视觉大模型、图文联合理解、跨模态推理,这些关键词几乎承包了今年所有的CVPR热议。视觉已不仅是“看”,更是“看懂”背后的语义与逻辑。
尤其在 OpenAI、Google DeepMind 等头部机构的推动下,视觉+语言+推理成为一体化系统的重要发展趋势,论文量大、竞争激烈。
二、ICCV 2025:投稿破万,评分已出
另一大顶会 ICCV 2025,也公布了最新评审动态。根据官方数据:
本届共收到 11152 篇有效投稿,创历年新高,所有论文至少获得 3 份评审意见。
当前已有不少作者晒出分数,平均分分布集中在 3.0~4.0 区间
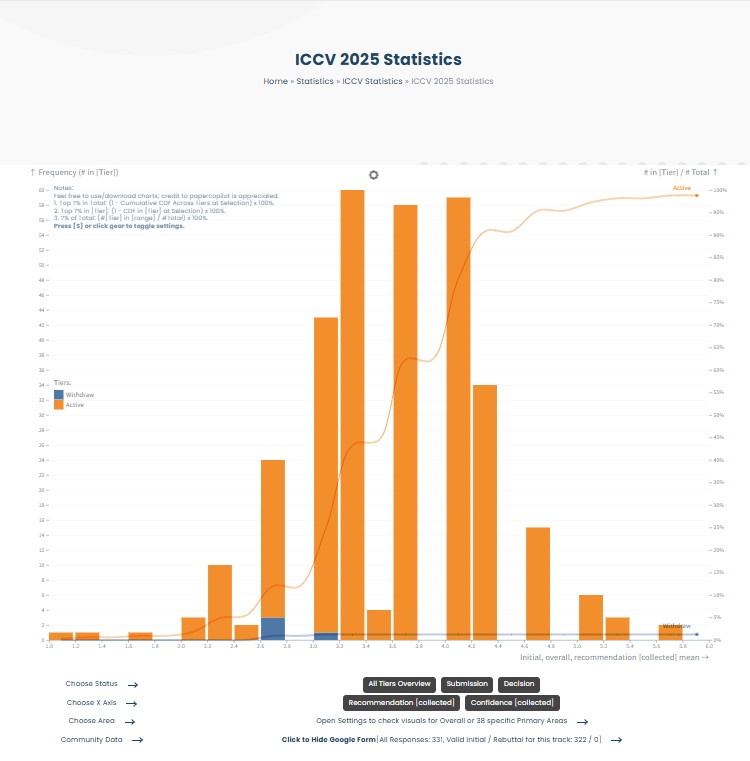
根据 Paper Copilot 统计:
目前约39%的投稿得分超过3.67,进入“可能录用”的黄金区间,其中17.83%得分高于 4.0,可算是稳了!
最终录用名单将在6月25日公布,期待更多好消息!
三、为什么这些趋势值得关注?
-
技术融合加速
如今,无人驾驶、AR/VR、工业检测等场景,对 3D 感知与实时重建的需求越来越强烈。多视角成像 + 多模态传感器(如 LiDAR、热成像、深度摄像头)的结合,物理世界与数字世界深度重叠,推动3D生成和理解迈向实用化,正在为这些应用提供坚实的技术支撑。
-
生成模型正成为主流
从单模态走向多模态,AI不再只是“识别”,而是在“理解”和“创造”之间找到了平衡。大模型如 GPT-4o、Gemini、Claude 已纷纷接入图像/视频输入输出,呈现出强烈的“多模态生成”趋势。背后的基础能力,正是图像与视频合成的进步所驱动。
-
学术门槛持续提高
随着投稿人数暴涨,CV顶会的接收门槛也水涨船高。能中一篇,足以说明该研究有独到见解。
四、未来展望
正如CVPR 2025 主席所言:“在CVPR,每篇论文都有同等权利。你是谁不重要。”
尽管投稿数量逐年上升、接收率屡创新低,但这也恰恰说明了一个事实——计算机视觉,仍然是AI研究的黄金地带。
不管你是刚起步的学生,还是多年深耕的研究者,这三大趋势都值得你深入关注,甚至提前布局。
如果你希望我们继续追踪三大顶会的趋势、热点模型或分享一手研究动态,欢迎关注我们,我们将持续带来深度解读。



















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









