




目录
引言
随着多模态大模型(LMMs)的快速发展,如何高效处理视觉和语言信息成为研究热点。现有模型通常将视觉输入编码为大量视觉token,导致计算复杂度和内存占用显著增加,尤其是在高分辨率图像和视频处理场景下,效率问题尤为突出。
LLaVA-Mini的提出正是为了解决这一问题。通过将每张图像的视觉token压缩至仅1个,LLaVA-Mini在保证视觉理解能力的同时,显著提升了计算效率和内存使用效率。这一创新不仅为多模态模型的高效化提供了新思路,也为实时交互应用奠定了技术基础。

论文题目:LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
论文链接:
https://arxiv.org/abs/2501.03895
一、摘要
GPT-4o等实时大型多模态模型(LMM)的出现引发了人们对高效LMM的浓厚兴趣。LMM 框架通常将视觉输入编码为视觉tokens(连续表示),并将其与文本指令整合到大型语言模型(LLM)的上下文中,其中大规模参数和大量上下文标记(主要是视觉token)会导致大量计算开销。以往为实现高效 LMM所做的努力总是侧重于用更小的模型取代LLM骨干,却忽略了标记数量这一关键问题。在本文中,我们介绍了LLaVA-Mini,一种使用最少视觉token的高效LMM。为了在保留视觉信息的同时实现较高的视觉token压缩率,我们首先分析了LMM如何理解视觉token,发现大多数视觉tokens只在LLM 骨干的早期层中发挥关键作用,在这些层中,它们主要将视觉信息融合为文本标记。在这一发现的基础上,LLaVA-Mini引入了模态预融合技术,将视觉信息提前融合到文本标记中,从而便于将输入LLM主干网的视觉token极度压缩成一个标记。LLaVA-Mini是一个统一的大型多模态模型,可以高效地支持对图像、高分辨率图像和视频的理解。
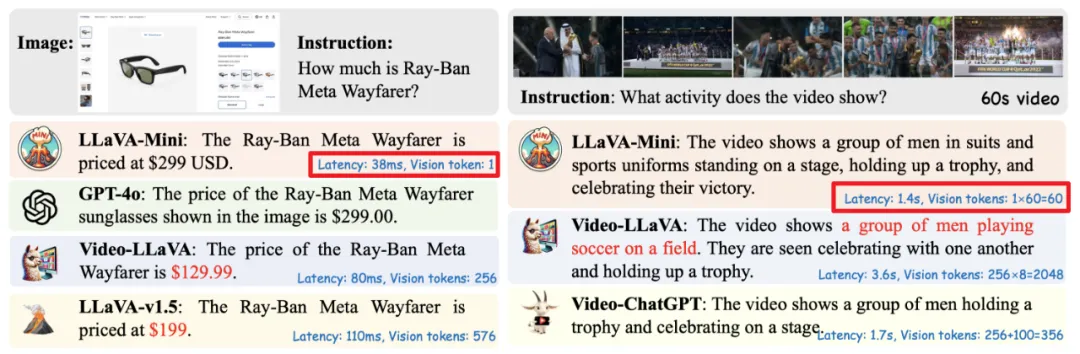
11 项基于图像和7项基于视频的实验表明,LLaVA-Mini的性能优于LLaVA-v1.5,只需1个视觉token,而不是576个。效率分析表明,LLaVA-Mini能将FLOPs减少77%,在40毫秒内提供低延迟响应,并能在24GB内存的GPU 硬件上处理超过10,000帧的视频。
二、介绍
论文中写到,目标是开发高效的LMM,在保持可比性能的同时,尽量减少视觉token的数量。为此,首先探讨了一个基础问题:LMM(尤其是LLaVA架构)是如何理解视觉tokens的?
通过分层分析,观察到视觉token的重要性在LLM不同层之间发生了变化。在早期层中,视觉tokens起着至关重要的作用,受到来自后续文本tokens(如用户输入指令LLaMA-VID LLaVA-TokenPacker LLaVA-Mini MQT-LLaVA和响应)的极大关注。然而,随着层数的加深,对视觉token的注意力急剧下降,大部分注意力转移到了输入指令上。值得注意的是,即使在后几层中不厌其烦地移除视觉tokens,LMM仍能保持一定的视觉理解能力。这一发现表明,视觉tokens在早期层中更为关键,在早期层中,文本标记融合了来自视觉tokens的视觉信息。
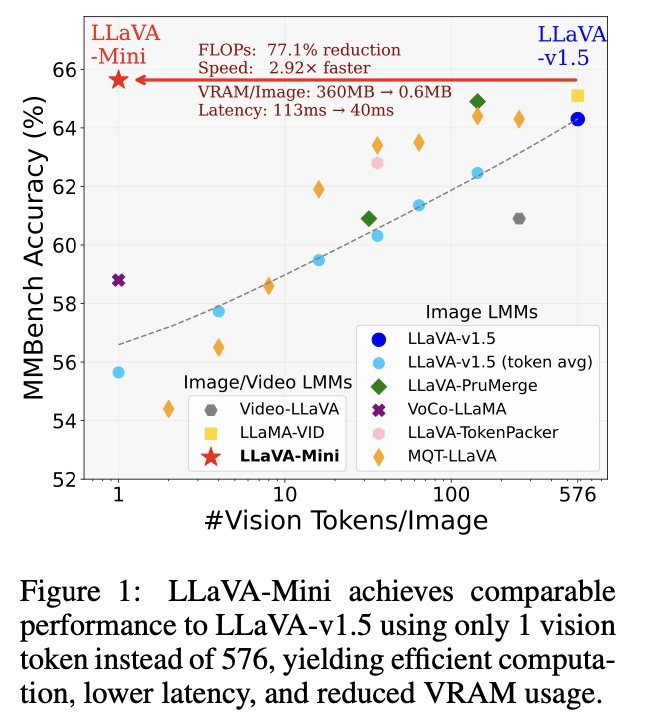
对11种基于图像和7种基于视频的理解基准的广泛实验表LLaVA-Mini的性能与LLaVA-v1.5相当,但只使用了1个视觉token,而不是576个(压缩率为0.17%)。如图1所示,LLaVA-Mini使用了最少的视觉令牌,在计算效率(FLOPs 减少77%)和降低GPU内存使用量(每幅图像360MB → 0.6MB)方面具有显著优势。因此,LLaVA-Mini将图像理解的推理延迟从100毫秒降至40毫秒,还能在配备24GB内存的英伟达RTX 3090上处理超过10,000帧(超过3小时)的长视频,为低延迟多模态交互铺平了道路。
三、多模态大模型如何理解视觉Tokens?
-
传统视觉Tokens的问题
在传统的多模态模型(如 LLaVA、Flamingo)中,视觉Tokens是通过将图像分割为多个小块(例如 Vision Transformer 将 224x224 图像分割为16x16的 patch,生成576个Tokens)生成的。这种设计存在以下问题:
1)计算复杂度高
视觉Tokens的数量与Transformer的计算量呈平方级增长,导致高分辨率图像处理效率低下。
2)内存占用大
每个Token都需要存储和处理,显存需求随图像分辨率增加而急剧上升。
3)信息冗余
许多局部Tokens包含重复或无关的视觉信息,导致资源浪费。
为了在减少视觉token的同时保持视觉理解能力,研究者首先分析了 LMMs如何处理和理解大量视觉token。分析集中在LLaVA架构,特别从注意力机制的角度探讨了视觉token的作用及其数量对LMMs性能的影响。具体而言,实验评估了视觉token在LMMs不同层中的重要性,涵盖了多种 LMMs,以识别不同规模和训练数据集的模型之间的共性。
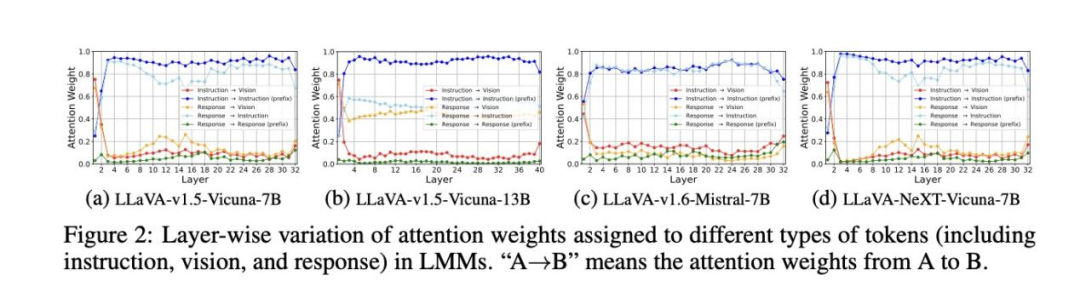
图4展示了LLaVA-v1.5各层的注意力分布。在早期层中,几乎所有视觉token都受到了更广泛的关注,而在后期层中,只有部分视觉token受到了关注。这些观察结果表明,所有视觉token在早期层都至关重要,而减少视觉token的数量必然会导致视觉信息的损失。这也解释了为什么以前的直接标记减少法会损害视觉理解能力。
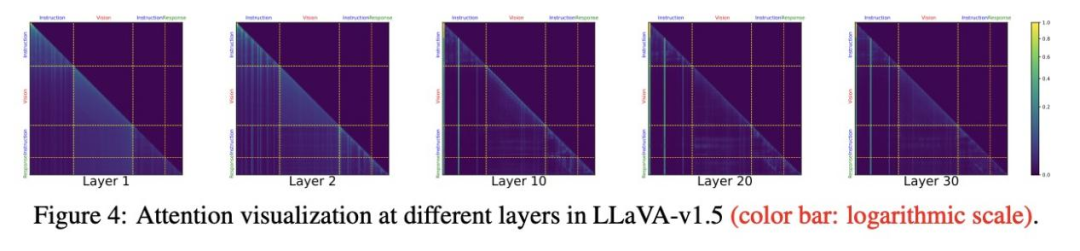
而大多数视觉token都集中在早期层为了进一步评估单个视觉token的重要性,我们计算了各层注意力分布的熵。我们发现视觉token的注意力熵在较早的层中要高得多,这表明大多数视觉token在较早的层中得到了均匀的关注。
四、LLaVA-Mini的核心技术
LLaVA-Mini使用视觉编码器将图像编码为若干视觉token。为了提升效率,LLaVA-Mini通过压缩模块大幅减少输入LLM 底座的视觉token数量。为了在压缩过程中保留视觉信息,基于先前的研究发现,视觉token在早期层中对于融合视觉信息至关重要,LLaVA-Mini在LLM底座之前引入了模态预融合模块,将视觉信息融入文本token 中,从而确保视觉理解能力。
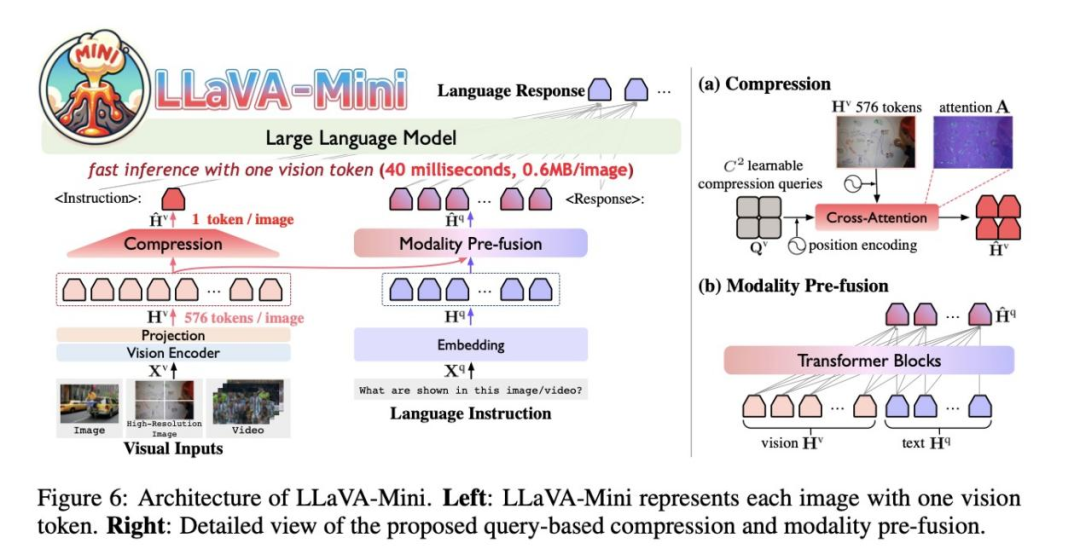
-
视觉token压缩技术
视觉token压缩是LLaVA-Mini的核心创新之一。传统多模态模型通常将每张图像编码为数百个视觉token,而LLaVA-Mini通过基于查询的压缩模块(query-based compression),将视觉token压缩至仅1个。具体而言,模型引入可学习的压缩查询,通过交叉注意力机制与所有视觉token交互,选择性提取关键视觉信息,生成压缩后的视觉token。
1)可学习查询向量
模型引入一组可训练的压缩查询向量(Compression Queries, CQ),通过交叉注意力(Cross-Attention)与原始视觉token交互。
2)动态特征提取
CQ主动“扫描”视觉特征图,聚焦关键区域(如物体边界、纹理特征),生成压缩后的视觉token。
这种压缩方法不仅大幅减少了数据量,还保留了图像的核心特征。实验表明,LLaVA-Mini在处理高分辨率图像时,内存占用减少了约70%,处理速度提升了近3倍。
-
模态预融合模块
为了在压缩过程中尽可能保留视觉信息,LLaVA-Mini引入了模态预融合模块。该模块将视觉信息提前融入文本token中,确保视觉理解能力不受压缩影响。具体实现上,模态预融合模块由多个Transformer块组成,视觉token和文本token被连接并输入到预融合模块中,提取与文本相关的视觉信息作为融合token。
这一设计显著减少了计算量,同时提升了多模态融合的效率。实验结果显示,LLaVA-Mini在图像和视频理解任务中表现出色,与LLaVA-v1.5相比,计算负载减少了77%,响应延迟降至40毫秒。
五、Coovally AI模型训练与应用平台
如果你也想要进行模型改进或模型训练,Coovally平台满足你的要求!
Coovally平台整合了国内外开源社区1000+模型算法和各类公开识别数据集,无论是YOLO系列模型还是MMDetection框架下的模型算法,平台全部包含,均可一键下载助力实验研究与产业应用。
而且在该平台上,无需配置环境、修改配置文件等繁琐操作,一键上传数据集,使用模型进行训练与结果预测,全程高速零代码!
具体操作步骤可参考:从YOLOv5到训练实战:易用性和扩展性的加强
平台链接:https://www.coovally.com
如果你想要另外的模型算法和数据集,欢迎后台或评论区留言,我们找到后会第一时间与您分享!
六、实验验证与性能突破
-
训练流程
LLaVA-Mini采用与LLaVA相同的训练流程,包括两个阶段。
阶段1:视觉-语言预训练。在这一阶段,尚未应用压缩和模态预融合模块(即N2个视觉标记保持不变)。LLaVA-Mini利用视觉字幕数据学习如何调整视觉和语言表征。训练只集中在投影模块上,而视觉编码器和LLM保持不变。
阶段2:指令调整。在这一阶段,LLaVA-Mini将接受训练,以便利用指令数据,根据最小视觉标记执行各种视觉任务。在LLaVA-Mini中引入压缩和模态预融合,并以端到端方式训练除冻结视觉编码器之外的所有模块(即投影、压缩、模态预融合和LLM骨干)。
-
训练结果
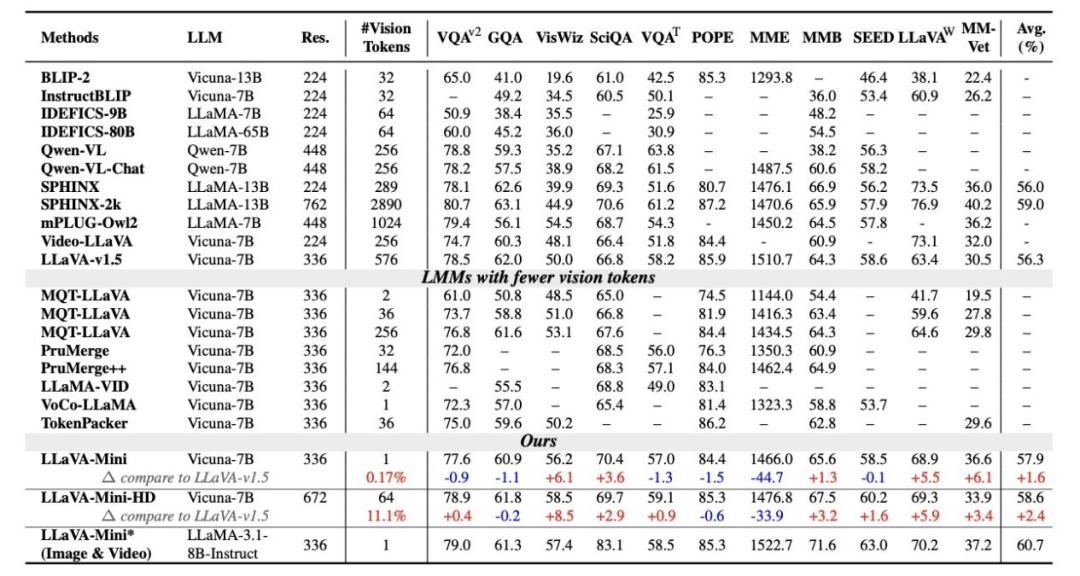
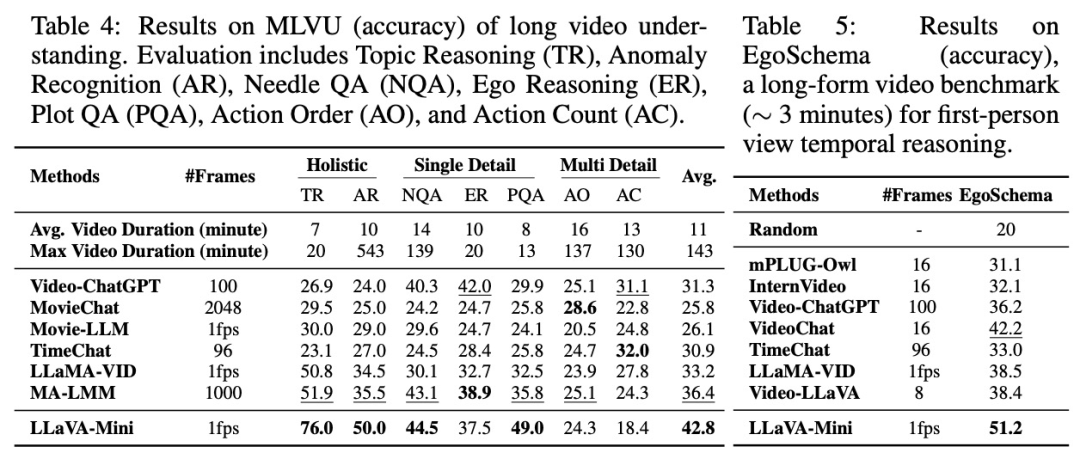
如下表所示,研究者在11个基准测试上比较了LLaVA-Mini和LLaVA-v1.5。结果表明,LLaVA-Mini仅使用1个视觉token(压缩率0.17%),远低于LLaVA-v1.5的576个视觉token,取得与LLaVA-v1.5相当的图像理解能力。
1)图像理解评估
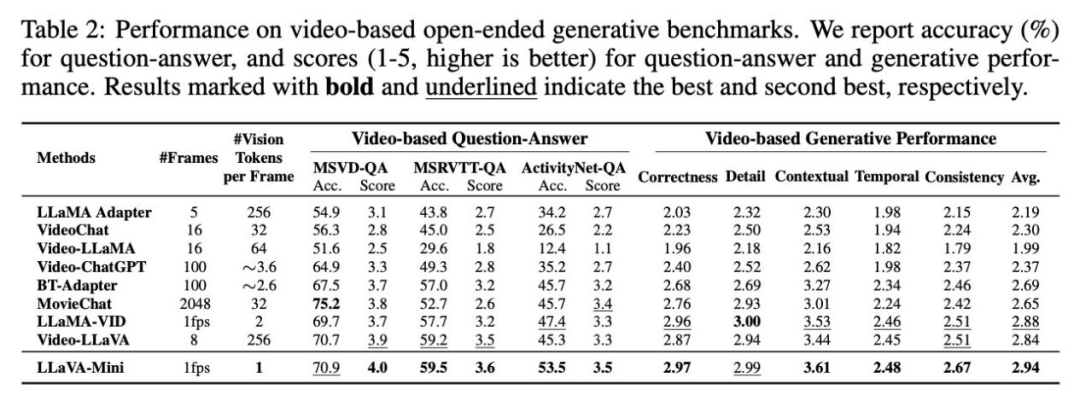
2)视频理解评估
LLaVA-Mini在视频理解上优于目前先进的视频LMMs。这些视频LMMs 使用大量视觉token表示每帧(224或576),受限于上下文长度,仅能提取8-16帧,可能导致部分视频信息丢失。相比之下,LLaVA-Mini通过1 个视觉token表示每张图像,能够以每秒1帧的速度提取视频帧,从而在视频理解上表现更佳。
3)长视频理解评估
LLaVA-Mini在长视频理解上具有显著优势。通过将每帧表示为一个视觉 token,LLaVA-Mini在推理时能够轻松扩展到更长的视频,并且通过token之间的位置编码隐式建模时序关系。特别地,LLaVA-Mini仅在少于1 分钟(<60帧)的视频上进行训练,且在推理时能够处理超过2小时(> 7200帧)的长视频。
-
LLaVA-Mini 效率
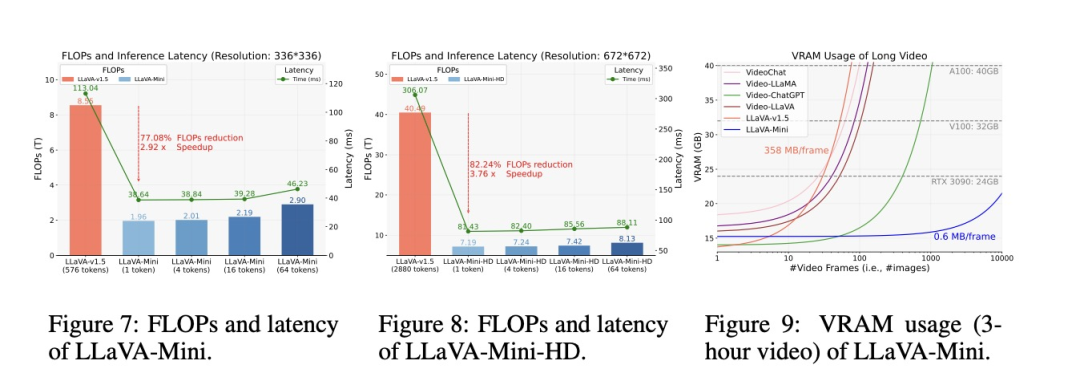
在性能与LLaVA-v1.5相当的情况下,我们进一步探讨了LLaVA-Mini的计算效率。图7、图8和图9展示了LLaVA-Mini在计算负载、推理延迟和内存使用方面的优势,其中FLOPs由calflops计算,延迟则在不使用任何工程加速技术的A100上进行测试。
1)FLOPs 和推理延迟
如图7所示,与LLaVA-v1.5相比,LLaVA-Mini大幅减少了77%的通信负载,速度提高了2.9倍。LLaVA-Mini实现了低于40毫秒的响应延迟,这对于开发低延迟实时LMM至关重要。如图8所示,在高分辨率下建模时,LLaVA-Mini的效率优势更加明显,FLOPs减少了82%,速度提高了3.76 倍。
2)内存使用
内存消耗是LMM 面临的另一个挑战,尤其是在视频处理中。图9展示了 LMM处理不同长度视频时的内存需求。在以前的方法中,每幅图像大约需要200-358MB内存,这限制了它们在40GB GPU上只能处理大约100帧。相比之下,使用一个视觉令牌的LLaVA-Mini每幅图像只需要0.6 MB,理论上可以在拥有24 GB内存的RTX 3090上支持超过10,000帧的视频处理。
七、结论
LLaVA-Mini是一个统一的多模态大模型,能够高效地支持图像、高分辨率图像和视频的理解。LLaVA-Mini在图像和视频理解方面表现出色,同时在计算效率、推理延迟和内存使用上具有优势,促进了高效LMM的实时多模态交互。
如果您有兴趣了解更多关于模型算法的使用方法等,欢迎关注我们,我们将继续为大家带来更多干货内容!



















 1910
1910




 到【灌水乐园】发言
到【灌水乐园】发言







