




LLaVA-Mini 是由中国科学院计算技术研究所提出的高效图像和视频大型多模态模型。可以高效地支持对图像、高分辨率图像和视频的理解。在 LMM 内部可解释性的指导下,LLaVA-Mini 在确保视觉能力的同时显著提高了效率。
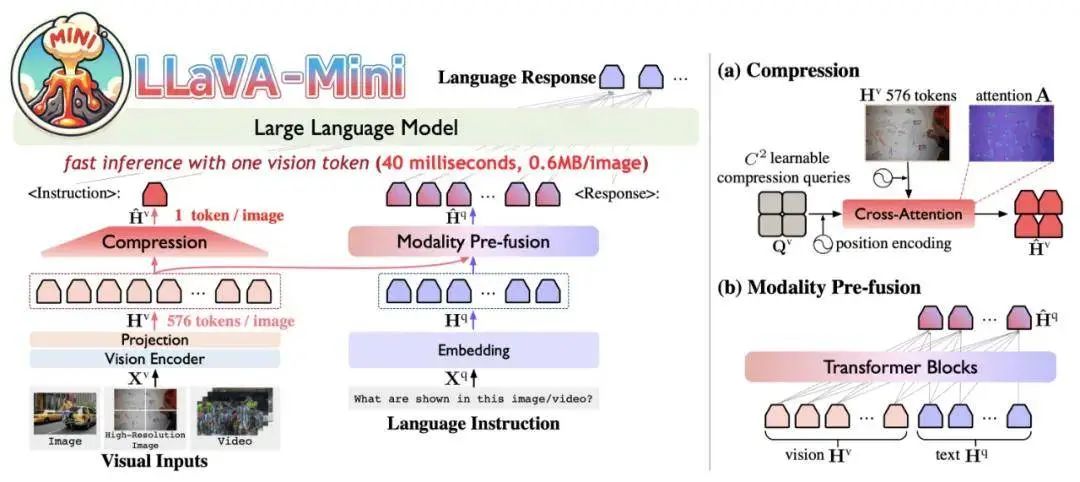
LLaVA-Mini 只需要1个token来表示每幅图像,提高了图像和视频理解的效率,包括:
-
计算工作量:减少 77% FLOP
-
响应延迟:由100毫秒缩短至40毫秒
-
VRAM 内存使用量:从 360 MB/图像减少到 0.6 MB/图像,支持 3 小时视频处理
核心亮点:
-
性能良好:LLaVA-Mini 仅使用 1 个视觉令牌而不是 576 个(压缩率为 0.17%),就实现了与 LLaVA-v1.5 相当的性能。
-
高效率:LLaVA-Mini 可减少 77% 的 FLOP,在 40 毫秒内提供低延迟响应,并在具有 24GB 内存的 GPU 硬件上处理超过 10,000 帧的视频。
接下来就为大家奉上详细的 LLaVA-Mini 本地部署教程,手把手教你如何将模型部署到你的项目中,轻松享受高性能AI带来的便利。
二、部署过程
基础环境最低要求说明:
| 环境名称 | 版本信息1 |
|---|---|
| Ubuntu | 22.04.4 LTS |
| Cuda | V12.4.105 |
| Python | 3.10 |
| NVIDIA Corporation | RTX 4090 |
1. 更新基础软件包
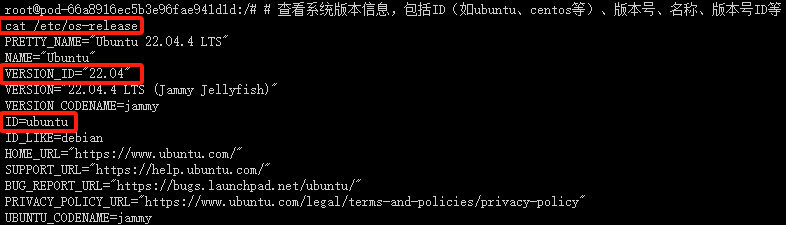
查看系统版本信息
# 查看系统版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等
cat /etc/os-release
配置 apt 国内源
# 更新软件包列表
apt-get update
这个命令用于更新本地软件包索引。它会从所有配置的源中检索最新的软件包列表信息,但不会安装或升级任何软件包。这是安装新软件包或进行软件包升级之前的推荐步骤,因为它确保了您获取的是最新版本的软件包。
# 安装 Vim 编辑器
apt-get install -y vim
这个命令用于安装 Vim 文本编辑器。-y 选项表示自动回答所有的提示为“是”,这样在安装过程中就不需要手动确认。Vim 是一个非常强大的文本编辑器,广泛用于编程和配置文件的编辑。
为了安全起见,先备份当前的 sources.list 文件之后,再进行修改:
# 备份现有的软件源列表
cp /etc/apt/sources.list /etc/apt/sources.list.bak
这个命令将当前的 sources.list 文件复制为一个名为 sources.list.bak 的备份文件。这是一个好习惯,因为编辑 sources.list 文件时可能会出错,导致无法安装或更新软件包。有了备份,如果出现问题,您可以轻松地恢复原始的文件。
# 编辑软件源列表文 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









