



目录
引言
目标检测是计算机视觉领域的一个重要任务,它要求算法能够识别图像中的不同目标并进行精确定位。RetinaNet作为一种创新的目标检测算法,自推出以来一直备受关注,尤其是在面对类别不平衡问题时,展示了出色的性能。在这篇文章中,我们将详细解析RetinaNet模型的工作原理、优势及其应用。
-
参考论文:https://arxiv.org/pdf/1708.02002
RetinaNet模型介绍
RetinaNet是由Facebook AI Research团队在2017年提出的一种目标检测算法。与传统的目标检测算法不同,RetinaNet特别关注类别不平衡问题,尤其是在面对背景和前景类别数量差异巨大的场景时,表现尤为突出。它通过一种叫做焦点损失(Focal Loss)的创新技术,解决了目标检测中常见的类别不平衡问题。

在目标检测中,常常有大量的背景区域(负样本)和少量的前景区域(正样本)。传统方法使用交叉熵损失时,由于负样本占多数,模型很容易将注意力集中在这些负样本上,导致训练效果不佳。焦点损失通过减少易分类样本的权重,将更多的关注集中在那些难以分类的样本上,从而有效缓解了这一问题。
模型架构
RetinaNet是由Resnet、FPN为主要架构,detection部分则是由两个FCN 子网路组成,分别用于预测分类及bndBox。
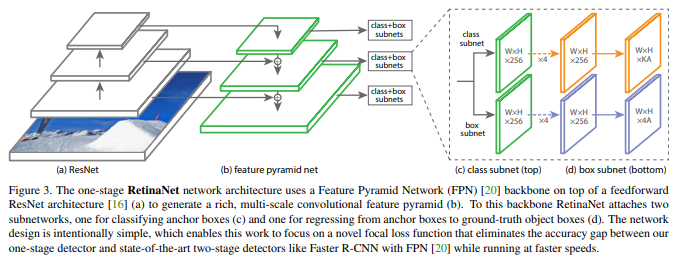
-
Backbone
RetinaNet backbone是基于Resnet的FPN,分别尝试了Resnet50、Resnet101,于第3~7层建构FPN,且每层通道维度为256。
FPN是一种自下而上、自上而下并横向连接的网路结构,通过横向连接可以融合不同层次的特征,从而增强网路的特征提取能力。
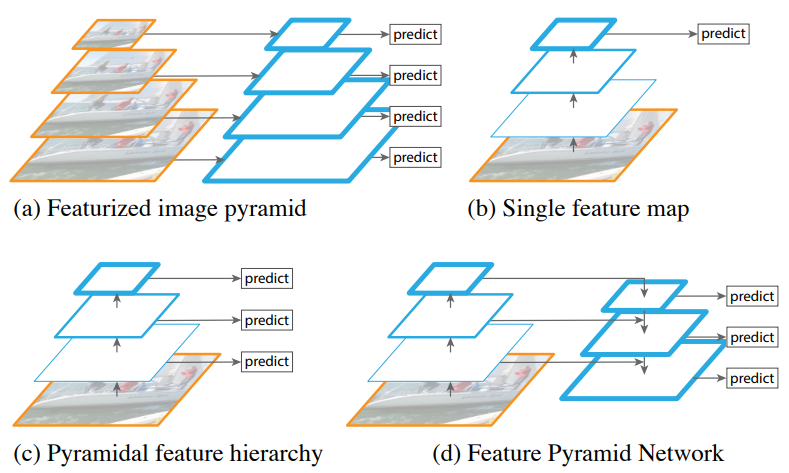
下图为四种生成多尺度特征的网路:
图a为图像金字塔,对不同维度的图像各自作为模型输入,生成不同尺度的特征,再将其concat得到最后的输出,需要花费较多的计算与时间成本。
图b由单一维度的图像作为模型输入并且仅拿最后一层的特征做预测,对于小目标的检测性能较差,使用此方法的有R-CNN, Fast-RCNN, Faster-RCNN, SPP-Net。
图c也是由单一维度的图像作为模型输入,但在每一层都生成不同尺度的特征,采用多尺度特征融合的方式,最后再将其concat起来,这种方式不会增加额外的计算量,使用此方法的为SSD。
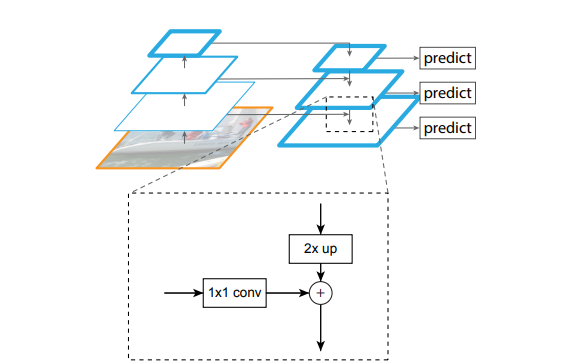
FPN的横向连接如下图所示,特征会从下自上进行2倍的下采样,而另一边特征会由上自下进行2倍的上采样,接着使用1x1卷积层降低channel维度,使得两边维度一致后再做相加。
-
Anchors
RetinaNet的anchor设置和RPN类似,在FPN中每层(第3~7 层)的anchor 尺寸分别为32x32、64x64、128x128、256x256、512x512,以及每一个anchor的长宽比设定为1:1、 1:2、2:1,并且再增加三种不同尺寸{2⁰, 2^(1/3), 2^(2/3)},因此每层共有9个anchor。由这些数值可以算出所有层的anchor size最小值为32、最大值为813。

对于每个anchor会对应一个长度为K的one-hot向量及4维的bndBox向量,其中K为类别数。
Anchor的匹配策略与RPN也类似,也是使用双阈值IOU,RetinaNet设定的阈值为0.4与0.5,当IOU>0.5视为正样本、IOU<0.4视为负样本,但如果IOU介在[0.4, 0.5)则忽略此样本,不参与训练。
-
Subnets
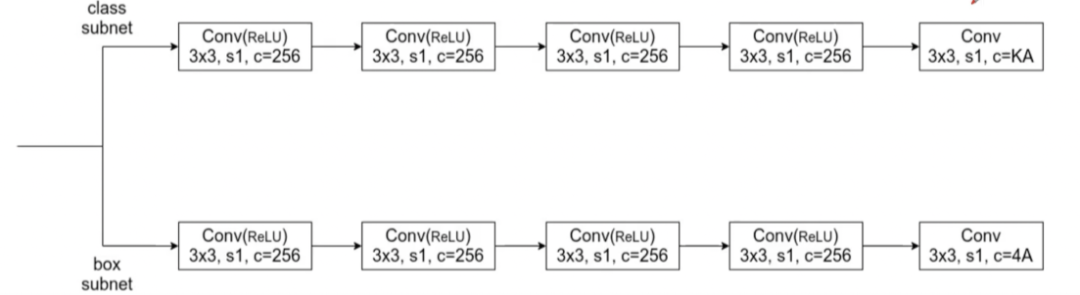
1)Classification Subnet
从网路架构图中可以知道FPN每一层都会连接cls分支,这些cls分支权值是共享的。
cls分支用于预测每个anchor的K个类别预测机率,网路模型总共使用五层,其中四层为3x3x256的FCN网路(激活函数使用ReLU)以及最后一层FCN的维度则是使用3x3xKA(使用Sigmoid),是因为对于A个anchor都有K维的one-hot向量,表示每一个类别的预测机率。
2)Box Regression Subnet
box分支与cls分支一样,差别在于最后一层FCN的维度则是使用3x3x4A,这是因为Box分支用于预测与ground truth位置的偏移量offset(x, y, w, h)。
需要注意的是虽然两个子网路架构类似,但彼此之间的参数不共享。
Focal Loss
Focal Loss是RetinaNet的核心创新之一。Focal Loss的提出,主要是为了缓解目标检测中类别不平衡问题,提高模型对难分类样本的关注度,尤其是在背景样本占比极高的情况下。
-
类别不平衡问题
在目标检测中,尤其是对于大规模数据集(如COCO),大部分区域是背景区域,且背景区域的样本数远远超过前景区域。由于这些背景区域对模型来说“过于简单”,它们通常会对模型训练产生主导影响,而“难分类”的前景区域(例如小物体或者被遮挡的物体)却没有得到足够的训练资源。
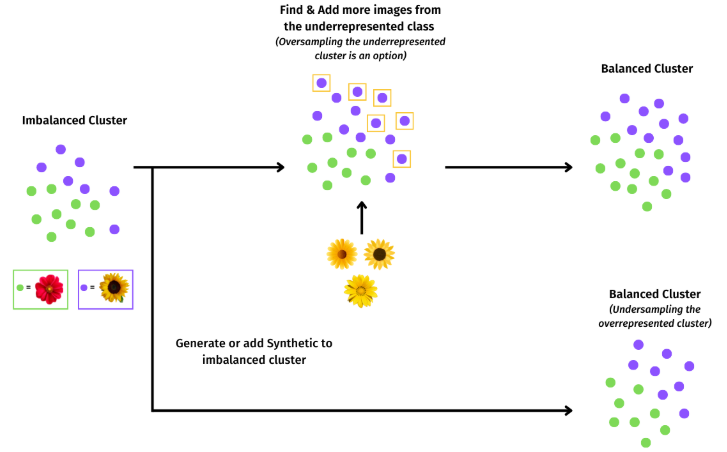
例如,在一张图像中,可能只有极少数的前景物体,而大多数像素点都属于背景。传统的目标检测方法(如交叉熵损失)会对所有样本给予相等的损失,这使得背景样本对整体损失的影响过大,导致模型过度关注背景,从而忽视了前景的检测。
-
Focal Loss原理
Focal Loss的核心思想是通过降低易分类样本的损失,增加难分类样本的损失,从而使得模型更加关注那些难以分类的样本,尤其是前景样本。Focal Loss通过一种加权机制来抑制易分类样本的影响,避免背景类样本过多地影响模型训练。
Focal Loss是从二分类的交叉熵损失 (CE) 演变而来的,以下为CE定义:
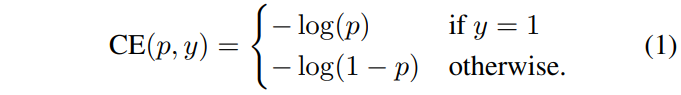
其中y∈{1,-1} 为ground truth,1表示为正样本、-1表示为负样本,p∈ [0,1]则是指预测为正样本的机率值,以下为p的定义:
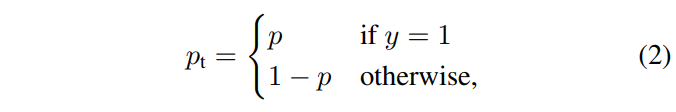
接着就可以将CE简写为:
![]()
-
Balanced Cross Entropy
为了解决类别不平衡的问题,比较直观的想法就是引入权重系数:α∈ [0,1] (for正样本)、1-α(for负样本),此时CE loss就变为α-balanced CE loss。
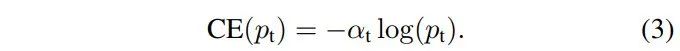
-
Focal Loss Definition
但α-balanced CE loss仅根据正负样本进行平衡,并没有考虑样本的难易度,虽然降低了容易分类的负样本损失,同时也让模型更难分类较难的负样本。
因此Focal Loss以CE为基础加上了调节因子-(1-pt)^r,以下为Focal Loss的定义,其中γ≥0:
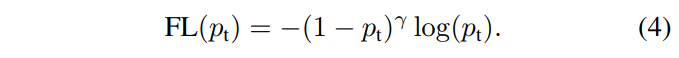
藉由公式可以看到当样本被误分且pt很小时,调节因子接近1,对loss不会产生影响;而对于被分类正确且pt接近1 时,调节因子接近0,可以有效降低对正确分类的loss,让模型更关注较难分类的样本。
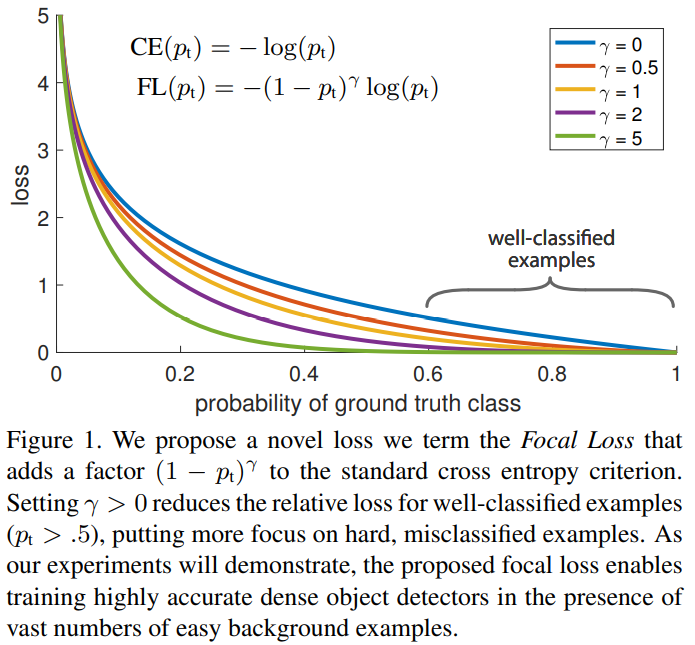
下图为γ∈[0,5]的loss曲线。当γ为0时,Focal Loss (FL)=CE;当γ增加时,调节因子也会跟着增加。经过实验结果得知,γ=2时,效果最好。
在最终的Focal loss引入了权重系数α,经实验结果证明,效果比原始的更好,其中γ=2,α=0.25的组合效果最佳。
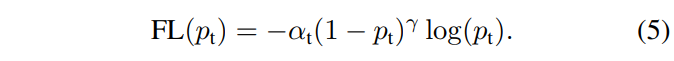
-
Model Initialization
二分类模型初始时对于正负样本的预测机率是相同的,在类别不平衡的情况下,数量较多的样本会主导网路的学习,导致训练不稳定。
为了解决这个问题,在模型初始化时,针对前景(正样本) 的预测值设置了先验值(prior) 的概念,以π 表示(设定π=0.01),如此一来使得模型前景样本的预测几率比较低,模型倾向预测为背景,大幅降低负样本的loss。
实验证明这个方法可以提高focal loss和cross entropy的训练稳定性,要注意的是只会影响模型初始化,并不会改变loss。
实验结果
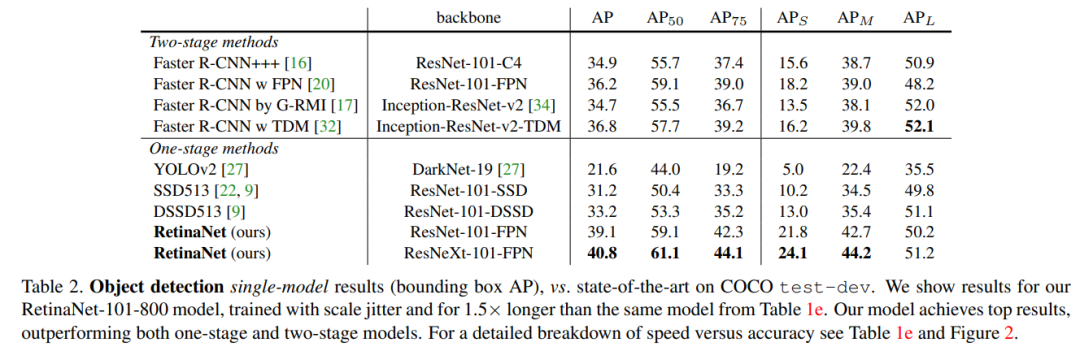
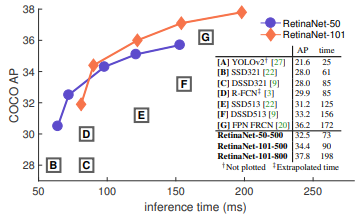
接着来看模型在COCO数据集上的检测效果比较,由下表可以看到RetinaNet 比其他One-stage方法有5.9AP的提升,以及比基于Inception-ResNet-v2-TDM的Faster R-CNN模型提升了大约2.3AP。
下图是模型检测性能与速度的对比,可以看出RetinaNet-101的检测性能比其他的模型更好,并且速度也更快。
应用案例
RetinaNet的焦点损失(Focal Loss)能够有效抑制背景样本的干扰,特别适合类别不平衡的场景。焦点损失通过降低易分类背景样本的影响,提升模型对难分类前景物体的检测能力。如工业质检、医疗影像等领域,背景区域远大于前景区域。
-
工业质检中的瑕疵检测
在工业生产中,质量检测通常需要对生产线上的产品进行自动化检查,以识别瑕疵(如裂缝、划痕、缺损等)。这些瑕疵的大小和形态可能各异,且背景(如生产设备、机械部分等)占据较大比例。RetinaNet能够有效应对类别不平衡的问题,并在多尺度检测中提供精度。
应用代码:
以下是使用RetinaNet进行工业质检中瑕疵检测的简单代码示例,基于MMDetection框架。
from mmdet.apis import init_detector, inference_detector, show_result_pyplot
# 配置文件和权重路径
config_file = 'configs/retinanet/retinanet_r50_fpn_1x_coco.py' # 使用MMDetection预训练模型
checkpoint_file = 'work_dirs/retinanet_r50_fpn_1x_coco/latest.pth' # 训练好的权重文件
# 初始化模型
model = init_detector(config_file, checkpoint_file, device='cuda:0')
# 进行推理,读取待检测图像
img = 'test_image.jpg' # 你的测试图像路径
result = inference_detector(model, img)
# 显示检测结果
show_result_pyplot(model, img, result, score_thr=0.5) # 设置检测置信度阈值由于骨架本身没有限制,MMDetection中目前提供的预训练权重所涉及的骨架网络包括:ResNet50-Caffe、ResNet50-Pytorch、ResNet101-Caffe、ResNet101-Pytorch、ResNeXt101,非常丰富。
MMDetection RetinaNet包括了详细的配置和参数设置,这使得用户可以根据自己的需求灵活地调整模型。例如,用户可以自定义Backbone网络、调整锚点生成策略、选择不同的损失函数等。
Coovally AI模型训练与应用平台
Coovally AI模型训练与应用平台整合了整合30+国内外开源社区1000+模型算法。
平台已部署RetinaNet系列模型算法
包含MMDetection框架下的常见目标检测模型,无需配置环境、修改配置文件等繁琐操作,可一键另存为我的模型,上传数据集,即可使用YOLO、RetinaNet等热门模型进行训练与结果预测,全程高速零代码!而且模型还可分享与下载,满足你的实验研究与产业应用。

总结
RetinaNet凭借其创新的焦点损失函数和强大的多尺度检测能力,已经成为目标检测领域的重要算法。它能够有效解决传统算法中的类别不平衡问题,具有高效的训练和推理能力,广泛应用于自动驾驶、视频监控、工业质检等多个领域。
如果你正从事与目标检测相关的工作,或者希望提升模型在复杂场景下的表现,RetinaNet无疑是一个值得深入了解和尝试的优秀算法。
如果您有兴趣了解更多关于模型算法的使用方法等,欢迎关注我们,我们将继续为大家带来更多干货内容!
别忘了点赞、留言、收藏哦!


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









