



 本文围绕C++中栈和队列展开,介绍了STL版本及栈和队列的底层实现。通过LeetCode多道题目,如用栈实现队列、用队列实现栈、括号匹配等,详细讲解解题思路与代码实现,还提及单调队列、优先级队列等知识,最后总结相关经典题目。
本文围绕C++中栈和队列展开,介绍了STL版本及栈和队列的底层实现。通过LeetCode多道题目,如用栈实现队列、用队列实现栈、括号匹配等,详细讲解解题思路与代码实现,还提及单调队列、优先级队列等知识,最后总结相关经典题目。
理论基础
队列是先进先出,栈是先进后出。
如图所示:
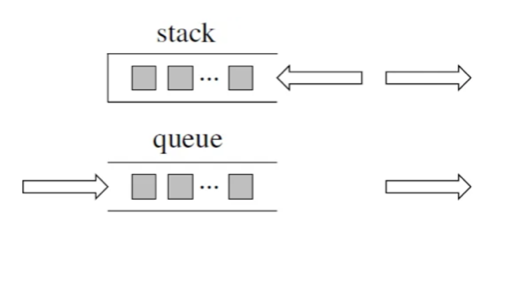
以C++为例,这里列出四个关于栈的问题:
- C++中stack 是容器么?
- 我们使用的stack是属于哪个版本的STL?
- 我们使用的STL中stack是如何实现的?
- stack 提供迭代器来遍历stack空间么?
相信这四个问题并不那么好回答, 因为初学者使用数据结构会停留在非常表面上的应用,稍稍往深一问,就会有似懂非懂的感觉。
很多人可能仅仅知道有栈和队列这么个数据结构,却不知道底层实现,也不清楚所使用栈和队列和STL是什么关系。
所以这里再扫一遍基础知识,
首先大家要知道 栈和队列是STL(C++标准库)里面的两个数据结构。
C++标准库是有多个版本的,要知道我们使用的STL是哪个版本,才能知道对应的栈和队列的实现原理。
那么来介绍一下,三个最为普遍的STL版本:
-
HP STL: 其他版本的C++ STL,一般是以HP STL为蓝本实现出来的,HP STL是C++ STL的第一个实现版本,而且开放源代码。
-
P.J.Plauger STL: 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的。
-
SGI STL: 由Silicon Graphics Computer Systems公司参照HP STL实现,被Linux的C++编译器GCC所采用,SGI STL是开源软件,源码可读性甚高。
接下来介绍的栈和队列也是SGI STL里面的数据结构, 知道了使用版本,才知道对应的底层实现。
来说一说栈,栈先进后出,如图所示:
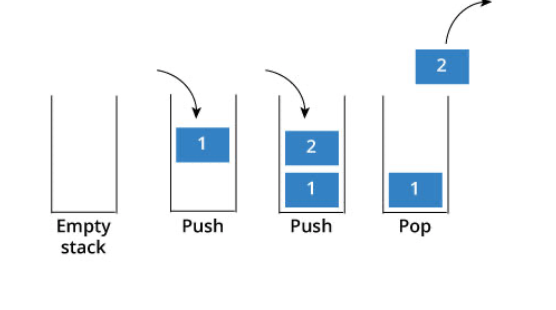
栈提供push 和 pop 等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。 不像是set 或者map 提供迭代器iterator来遍历所有元素。
栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。
所以STL中栈往往不被归类为容器,而被归类为container adapter(容器适配器)。
C++ STL六大组件:
STL大体分为六大组件,分别是:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器
- 容器:各种数据结构,如vector、list、set、map等,用来存放数据。
- 算法:各种常用的算法,如sort、find、copy、for_each等
- 迭代器:扮演了容器与算法之间的胶合剂。
- 仿函数:行为类似函数,可作为算法的某种策略。
- 适配器:一种用来修饰容器或者仿函数或迭代器接口的东西。
- 空间配置器:负责空间的配置与管理。
那么问题来了,STL 中栈是用什么容器实现的?
从下图中可以看出,栈的内部结构,栈的底层实现可以是vector,deque,list 都是可以的, 主要就是数组和链表的底层实现。
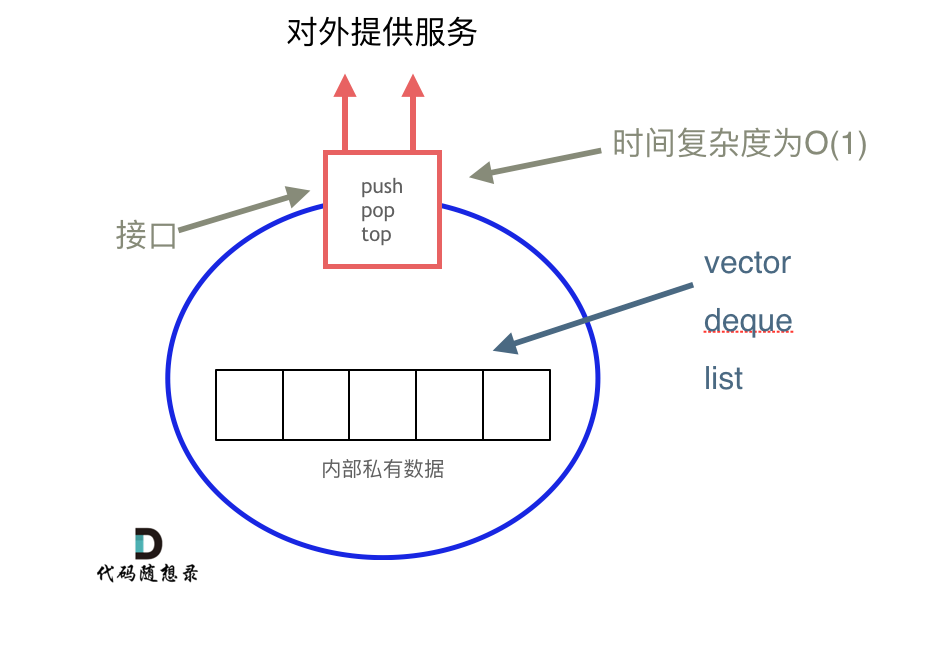
我们常用的SGI STL,如果没有指定底层实现的话,默认是以deque为缺省情况下栈的底层结构。
deque是一个双向队列,只要封住一段,只开通另一端就可以实现栈的逻辑了。
SGI STL中 队列底层实现缺省情况下一样使用deque实现的。
我们也可以指定vector为栈的底层实现,初始化语句如下:
std::stack<int, std::vector<int> > third; // 使用vector为底层容器的栈
刚刚讲过栈的特性,对应的队列的情况是一样的。
队列中先进先出的数据结构,同样不允许有遍历行为,不提供迭代器, SGI STL中队列一样是以deque为缺省情况下的底部结构。
也可以指定list 为起底层实现,初始化queue的语句如下:
std::queue<int, std::list<int>> third; // 定义以list为底层容器的队列
所以STL 队列也不被归类为容器,而被归类为container adapter(容器适配器)。
232. 用栈实现队列
思路:
使用栈来模式队列的行为,如果仅仅用一个栈,是一定不行的,所以需要两个栈:一个输入栈,一个输出栈,这里要注意输入栈和输出栈的关系。
用队列实现栈时,可以用两个队列:一个主要队列,一个备份队列;但也可以用一个队列:一个队列在模拟栈弹出元素的时候只要将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部,此时再去弹出元素就是栈的顺序了。
下面动画模拟以下队列的执行过程:
执行语句:
queue.push(1);
queue.push(2);
queue.pop(); 注意此时的输出栈的操作
queue.push(3);
queue.push(4);
queue.pop();
queue.pop();注意此时的输出栈的操作
queue.pop();
queue.empty();
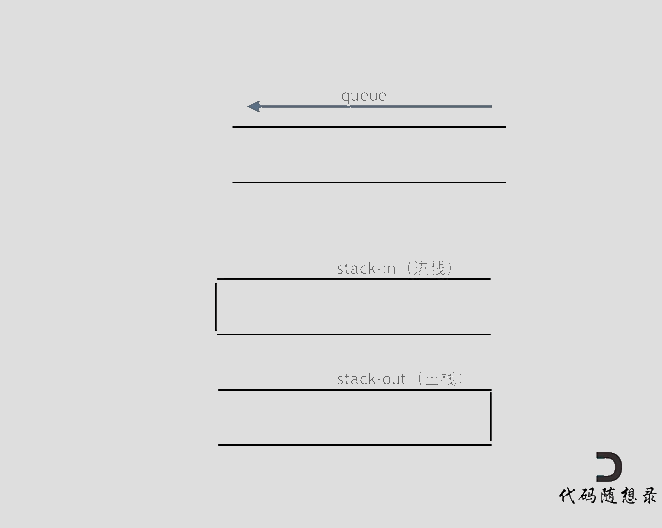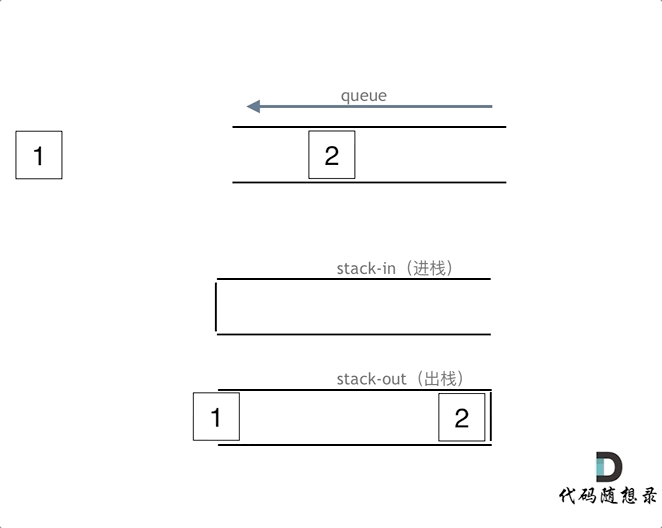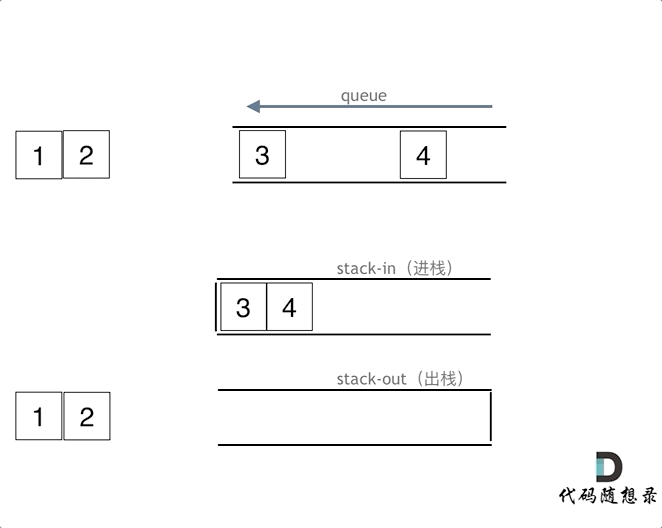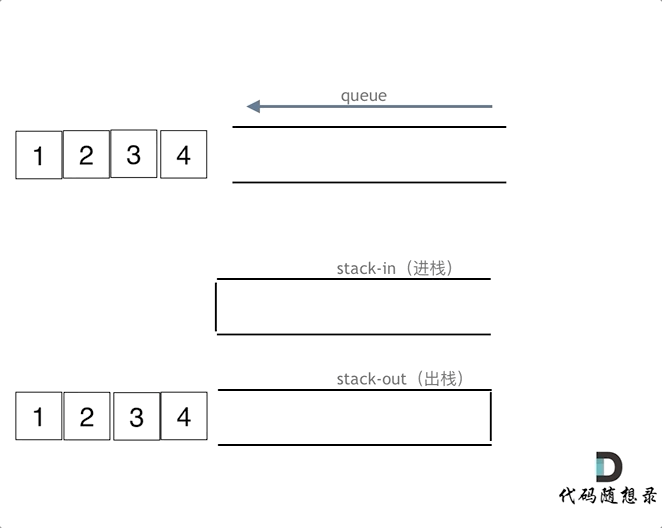
在push数据的时候,只要数据放进输入栈就好,但在pop的时候,操作就复杂一些,输出栈如果为空,就把进栈数据全部导入进来(注意是全部导入),再从出栈弹出数据,如果输出栈不为空,则直接从出栈弹出数据就可以了。
最后如何判断队列为空呢?如果进栈和出栈都为空的话,说明模拟的队列为空了。
在代码实现的时候,会发现pop() 和 peek()两个函数功能类似,代码实现上也是类似的,可以思考一下如何把代码抽象一下。下面的题解中,peek()的实现,直接复用了pop(), 要不然,对stOut判空的逻辑又要重写一遍。
再多说一些代码开发上的习惯问题,在工业级别代码开发中,最忌讳的就是 实现一个类似的函数,直接把代码粘过来改一改就完事了。
这样的项目代码会越来越乱,一定要懂得复用,功能相近的函数要抽象出来,不要大量的复制粘贴,很容易出问题。
题解:
class MyQueue {
public:
stack<int> stIn;
stack<int> stOut;
MyQueue() {
}
void push(int x) {
stIn.push(x);
}
int pop() {
// 只有当stOut为空的时候,再从stIn里导入全部数据
if (stOut.empty()) {
while (!stIn.empty()) {
stOut.push(stIn.top());
stIn.pop();
}
}
int top = stOut.top();
stOut.pop();
return top;
}
int peek() {
int top = this->pop();
stOut.push(top);
return top;
}
bool empty() {
return stIn.empty() && stOut.empty();
}
};225. 用队列实现栈
思路:
(这里要强调是单向队列)
队列模拟栈,其实一个队列就够了,但我们先说一说两个队列来实现栈的思路。
队列是先进先出的规则,把一个队列中的数据导入另一个队列中,数据的顺序并没有变,并没有变成先进后出的顺序。
所以用栈实现队列, 和用队列实现栈的思路还是不一样的,这取决于这两个数据结构的性质。
但是依然还是要用两个队列来模拟栈,只不过没有输入和输出的关系,而是另一个队列完全用来备份的。
如下面动画所示,用两个队列que1和que2实现队列的功能,que2其实完全就是一个备份的作用,把que1最后面的元素以外的元素都备份到que2,然后弹出最后面的元素,再把其他元素从que2导回que1。
模拟的队列执行语句如下:
queue.push(1);
queue.push(2);
queue.pop(); // 注意弹出的操作
queue.push(3);
queue.push(4);
queue.pop(); // 注意弹出的操作
queue.pop();
queue.pop();
queue.empty();
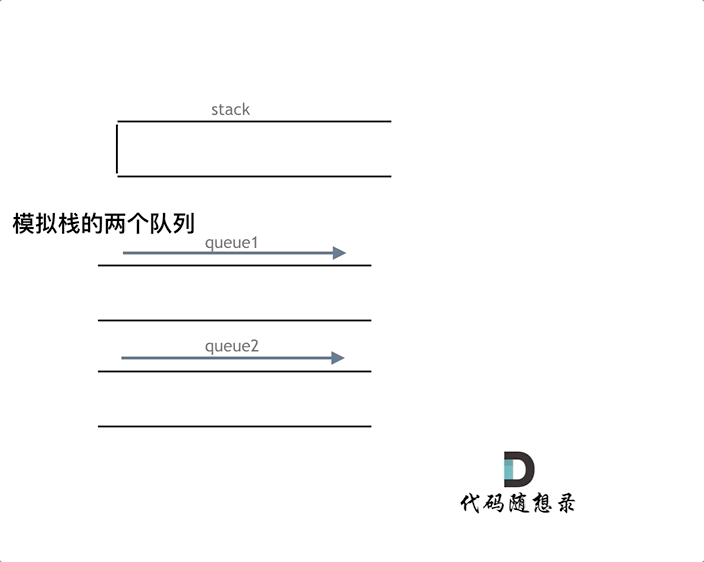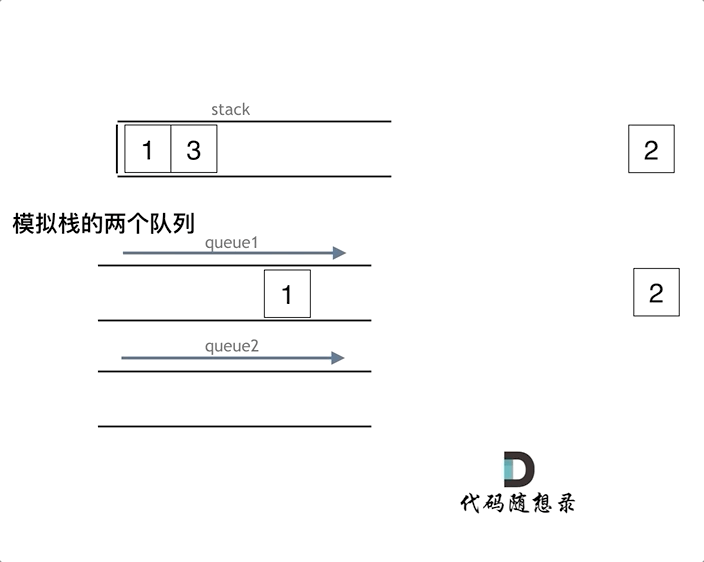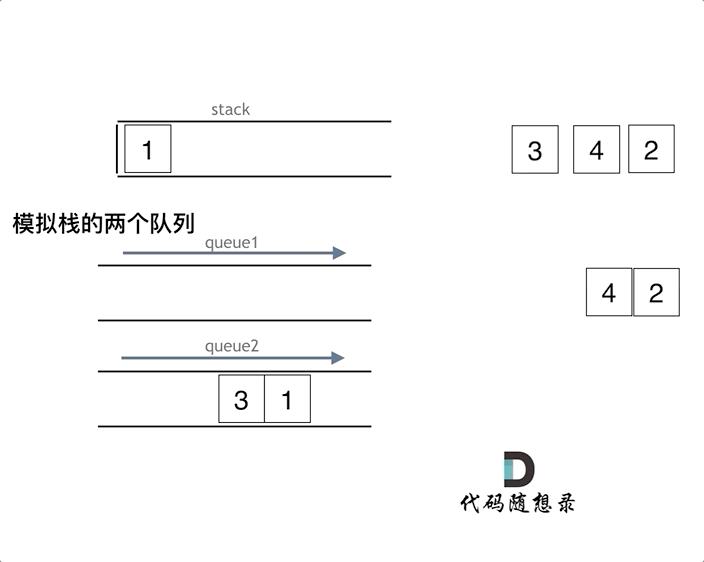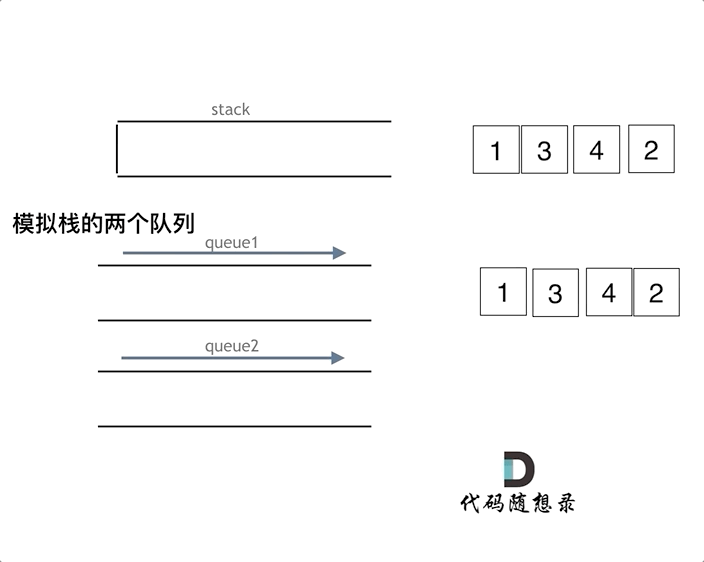
其实用一个队列就够了。
一个队列在模拟栈弹出元素的时候只要将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部,此时再去弹出元素就是栈的顺序了。
题解:
//用两个队列实现
class MyStack {
public:
queue<int> que1;
queue<int> que2;
MyStack() {
}
void push(int x) {
que1.push(x);
}
int pop() {
int size1 = que1.size();
while (--size1) {
que2.push(que1.front());
que1.pop();
}
int ret = que1.front();
que1.pop();
while (!que2.empty()) {
que1.push(que2.front());
que2.pop();
}
return ret;
}
int top() {
int ret = this->pop();
que1.push(ret);
return ret;
}
bool empty() {
return que1.empty();
}
};
//用一个队列实现
class MyStack {
public:
queue<int> que;
MyStack() {
}
void push(int x) {
que.push(x);
}
int pop() {
int len = que.size();
while (--len) {
que.push(que.front());
que.pop();
}
int ret = que.front();
que.pop();
return ret;
}
int top() {
int ret = this->pop();
que.push(ret);
return ret;
}
bool empty() {
return que.empty();
}
};20. 有效的括号
思路:
括号匹配是使用栈解决的经典问题。
如果学过编译原理的话,编译器在 词法分析的过程中处理括号、花括号等这个符号的逻辑,也是使用了栈这种数据结构。
再举个例子,linux系统中,cd这个进入目录的命令我们应该再熟悉不过了。
cd a/b/c/../../
这个命令最后进入a目录,系统是如何知道进入了a目录呢 ,这就是栈的应用(其实可以出一道相应的面试题了)
由于栈结构的特殊性,非常适合做对称匹配类的题目。
建议在写代码之前要分析好有哪几种不匹配的情况,如果不在动手之前分析好,写出的代码也会有很多问题。
先来分析一下 这里有三种不匹配的情况,
-
第一种情况,字符串里左方向的括号多余了 ,所以不匹配。
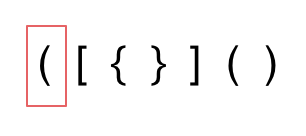
-
第二种情况,括号没有多余,但是 括号的类型没有匹配上。
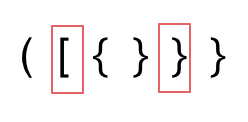
-
第三种情况,字符串里右方向的括号多余了,所以不匹配。
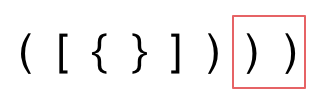
我们的代码只要覆盖了这三种不匹配的情况,就不会出问题,可以看出动手之前分析好题目的重要性。
动画如下:
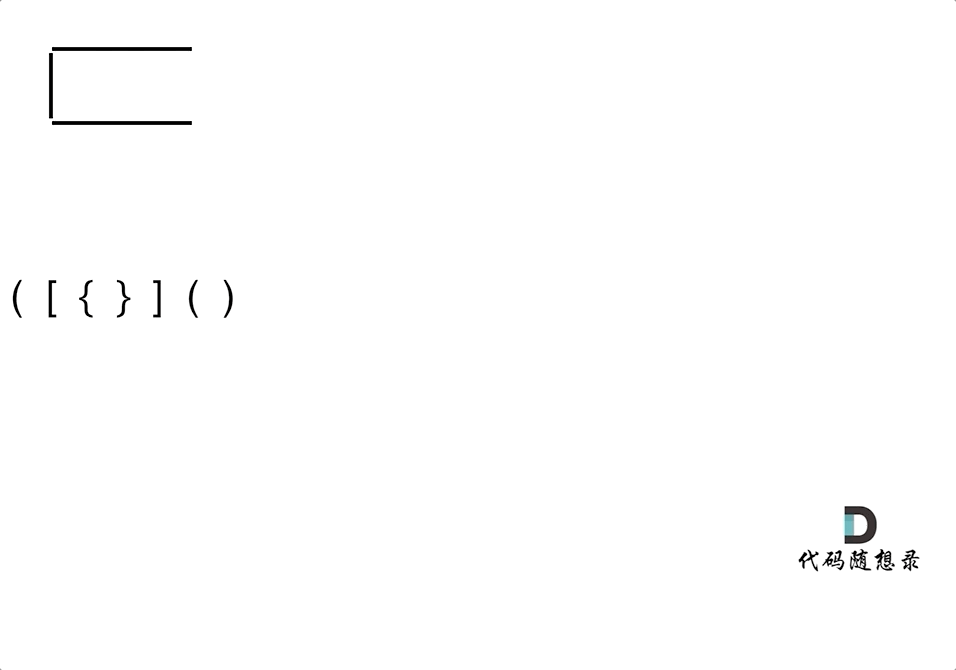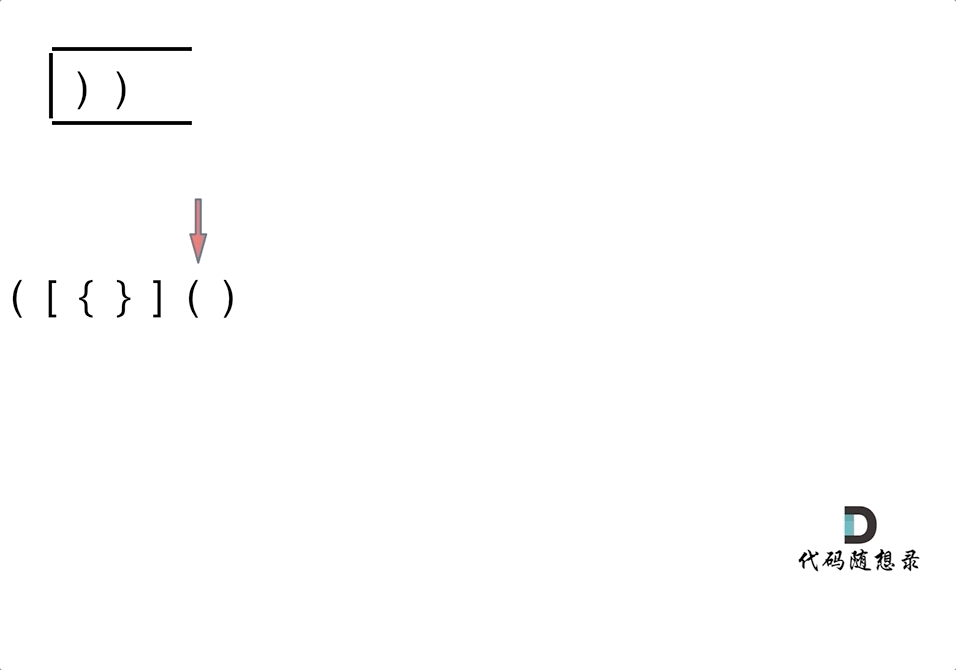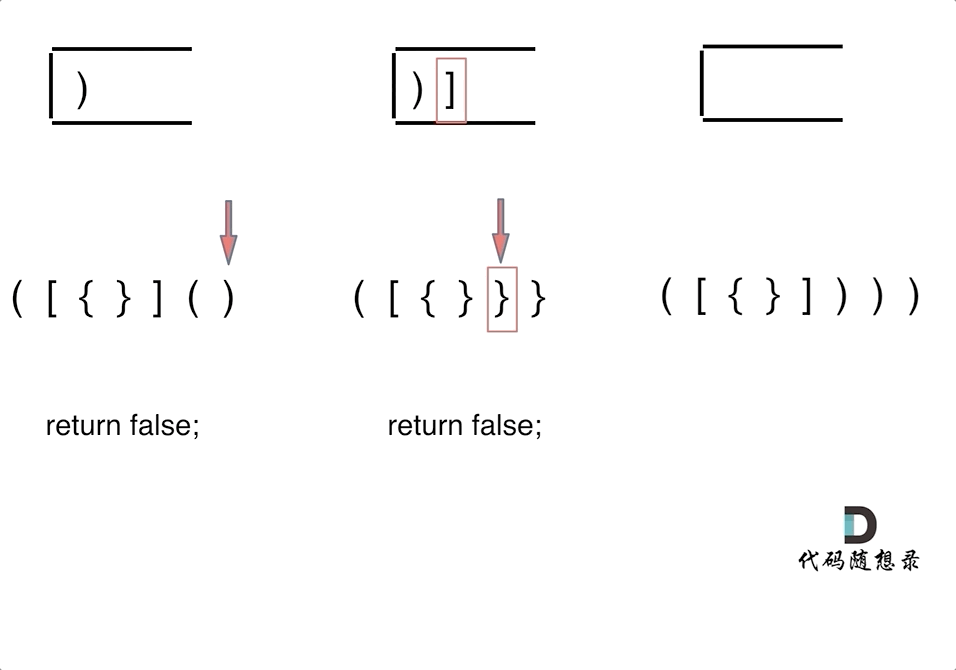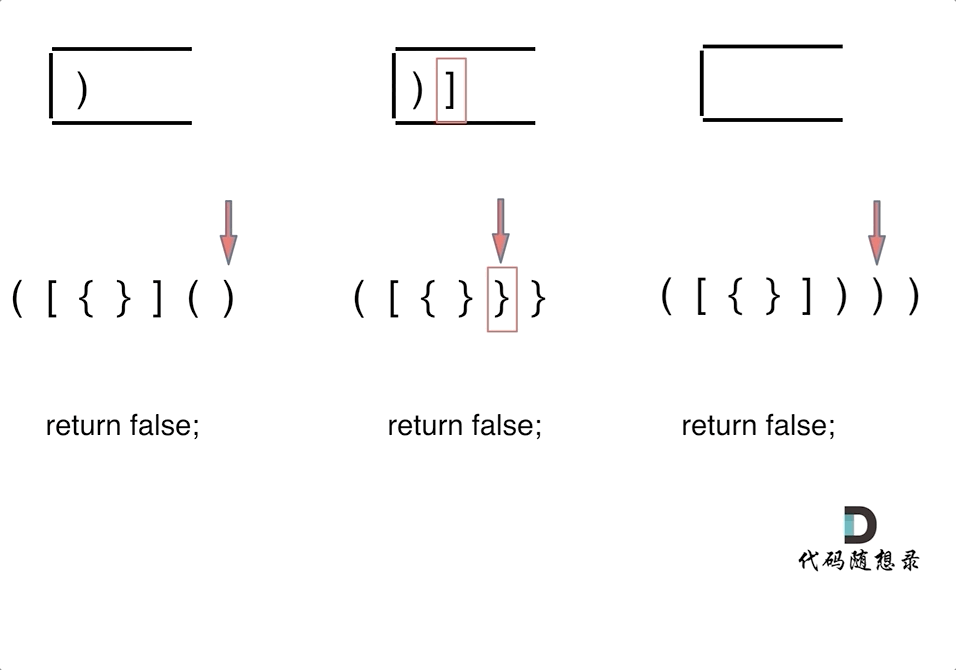
第一种情况:已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false
第二种情况:遍历字符串匹配的过程中,发现栈里没有要匹配的字符。所以return false
第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号return false
那么什么时候说明左括号和右括号全都匹配了呢,就是字符串遍历完之后,栈是空的,就说明全都匹配了。
还有一些技巧,在匹配左括号的时候,右括号先入栈,就只需要比较当前元素和栈顶相不相等就可以了,比左括号先入栈代码实现要简单的多。
官解:
自己写的答案是让左括号入栈,写出的代码没有官解优雅,故只放官解。
class Solution {
public:
bool isValid(string s) {
if (s.size() % 2 != 0) return false; // 如果s的长度为奇数,一定不符合要求
stack<char> st;
for (int i = 0; i < s.size(); i++) {
if (s[i] == '(') st.push(')');
else if (s[i] == '{') st.push('}');
else if (s[i] == '[') st.push(']');
// 第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号 return false
// 第二种情况:遍历字符串匹配的过程中,发现栈里没有我们要匹配的字符。所以return false
else if (st.empty() || st.top() != s[i]) return false;
else st.pop(); // st.top() 与 s[i]相等,栈弹出元素
}
// 第一种情况:此时我们已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false,否则就return true
return st.empty();
}
};1047. 删除字符串中的所有相邻重复项
思路:
本题也是用栈来解决的经典匹配问题。
我们在删除相邻重复项的时候,其实就是要知道当前遍历的这个元素,我们在前一位是不是遍历过一样数值的元素,那么如何记录前面遍历过的元素呢?
所以就是用栈来存放,那么栈的目的,就是存放遍历过的元素,当遍历当前的这个元素的时候,去栈里看一下我们是不是遍历过相同数值的相邻元素。
然后再去做对应的消除操作。 如动画所示:

从栈中弹出剩余元素,此时是字符串ac,因为从栈里弹出的元素是倒序的,所以再对字符串进行反转一下,就得到了最终的结果。
题解:
class Solution {
public:
string removeDuplicates(string s) {
stack<char> st;
string ans = "";
for (int i = 0; i < s.size(); i++) {
if (!st.empty() && st.top() == s[i]) {
st.pop();
} else {
st.push(s[i]);
}
}
while (!st.empty()) {
ans += st.top();
st.pop();
}
reverse(ans.begin(), ans.end());
return ans;
}
};150. 逆波兰表达式求值
思路:
逆波兰表达式:是一种后缀表达式,所谓后缀就是指运算符写在后面。
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。
该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:
-
去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
-
适合用栈操作运算:遇到数字则入栈;遇到运算符则取出栈顶两个数字进行计算,并将结果压入栈中。
栈与递归之间在某种程度上是可以转换的! 这一点在后续学习二叉树的时候,会更详细的讲解到。其实逆波兰表达式相当于是二叉树中的后序遍历。 大家可以把运算符作为中间节点,按照后序遍历的规则画出一个二叉树。
但我们没有必要从二叉树的角度去解决这个问题,只要知道逆波兰表达式是用后序遍历的方式把二叉树序列化了,就可以了。
在进一步看,本题中每一个子表达式要得出一个结果,然后拿这个结果再进行运算,那么这就相当于是一个相邻字符串消除的过程,和 题1047. 删除字符串中的所有相邻重复项 中的对对碰游戏非常像。
如动画所示:
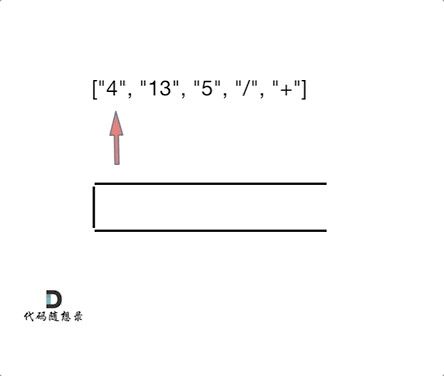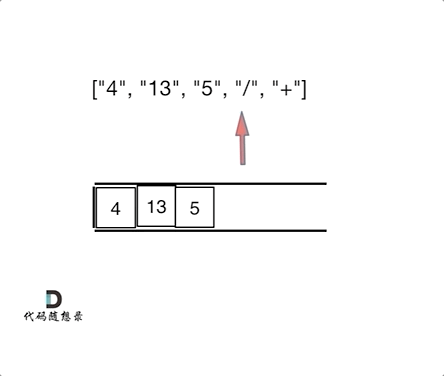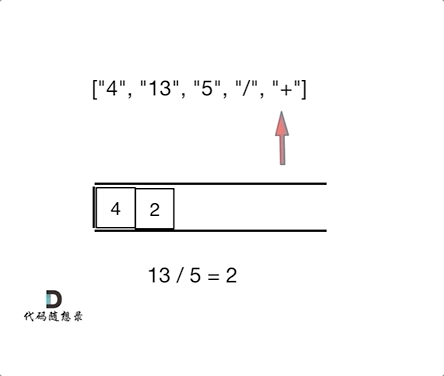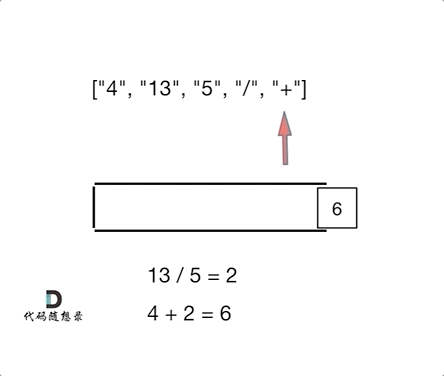
题解:
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
for (int i = 0; i < tokens.size(); i++) {
if (tokens[i] == "+" || tokens[i] == "-" || tokens[i] == "*" || tokens[i] == "/") {
int num2 = st.top();
st.pop();
int num1 = st.top();
st.pop();
if (tokens[i] == "+") {
st.push(num1 + num2);
} else if (tokens[i] == "-") {
st.push(num1 - num2);
} else if (tokens[i] == "*") {
st.push(num1 * num2);
} else {
st.push(num1 / num2);
}
} else {
st.push(stoi(tokens[i]));
}
}
return st.top();
}
};这里有一个从string类型转换到int类型的操作,使用了stoi()函数。
stoi函数是C++标准库中的一个函数,用于将字符串转换为整数。
stoi函数的定义如下:
int stoi(const string& str, size_t* idx = 0, int base = 10);参数说明:
- str:要转换的字符串。
- idx:可选参数,用于存储转换结束的位置,即第一个无效字符的位置。
- base:可选参数,指定转换时使用的进制,默认为10进制。
返回值:
- 返回转换后的整数值。
239. 滑动窗口最大值
思路:
这是使用单调队列的经典题目。
暴力方法,遍历一遍的过程中每次从窗口中再找到最大的数值,这样很明显是O(n × k)的算法。
有的同学可能会想用一个大顶堆(优先级队列)来存放这个窗口里的k个数字,这样就可以知道最大的最大值是多少了, 但是问题是这个窗口是移动的,而大顶堆每次只能弹出最大值,我们无法移除其他数值,这样就造成大顶堆维护的不是滑动窗口里面的数值了。所以不能用大顶堆。
此时我们需要一个队列,这个队列呢,放进去窗口里的元素,然后随着窗口的移动,队列也一进一出,每次移动之后,队列告诉我们里面的最大值是什么。
这个队列应该长这个样子:
class MyQueue {
public:
void pop(int value) {
}
void push(int value) {
}
int front() {
return que.front();
}
};
每次窗口移动的时候,调用que.pop(滑动窗口中移除元素的数值),que.push(滑动窗口添加元素的数值),然后que.front()就返回我们要的最大值。
然后再分析一下,队列里的元素一定是要排序的,而且要最大值放在出队口,要不然怎么知道最大值呢。
但如果把窗口里的元素都放进队列里,窗口移动的时候,队列需要弹出元素。
那么问题来了,已经排序之后的队列 怎么能把窗口要移除的元素(这个元素可不一定是最大值)弹出呢。
其实队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。
那么这个维护元素单调递减的队列就叫做单调队列,即单调递减或单调递增的队列。C++中没有直接支持单调队列,需要我们自己来实现一个单调队列
不要以为实现的单调队列就是 对窗口里面的数进行排序,如果排序的话,那和优先级队列又有什么区别了呢。
来看一下单调队列如何维护队列里的元素。
动画如下:
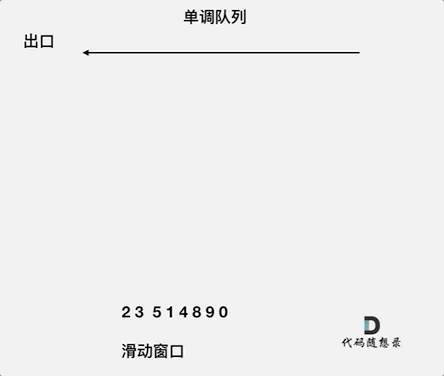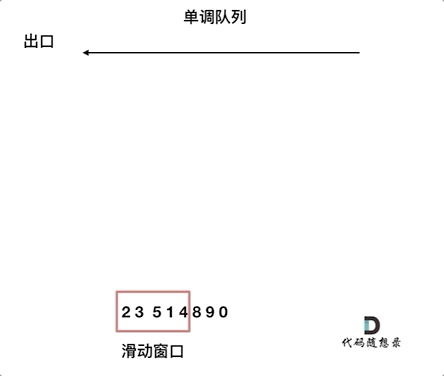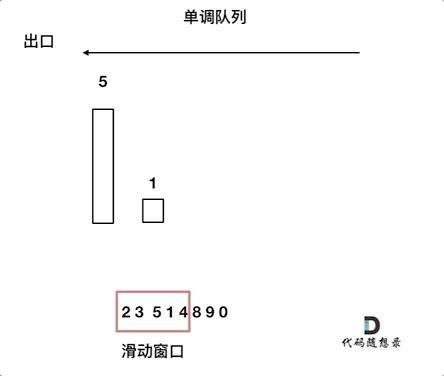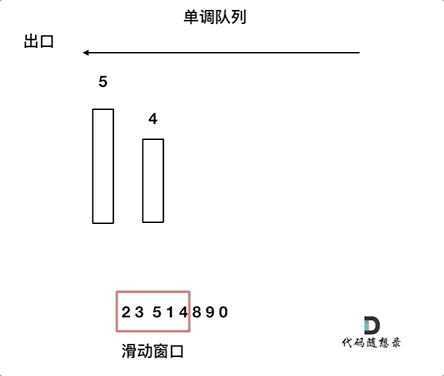
对于窗口里的元素{2, 3, 5, 1 ,4},单调队列里只维护{5, 4} 就够了,保持单调队列里单调递减,此时队列出口元素就是窗口里最大元素。
此时大家应该怀疑单调队列里维护着{5, 4} 怎么配合窗口进行滑动呢?
设计单调队列的时候,pop,和push操作要保持如下规则:
- pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- push(value):如果push的元素value大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。
为了更直观的感受到单调队列的工作过程,以题目示例为例,输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3,动画如下:
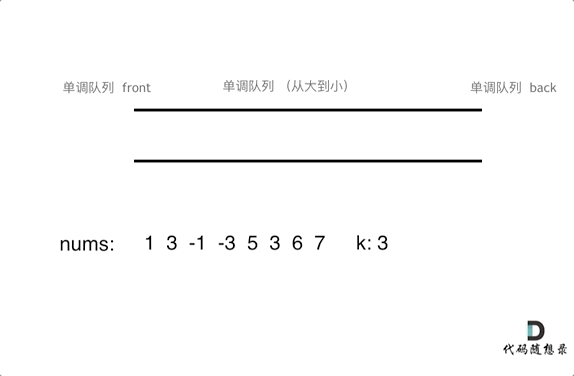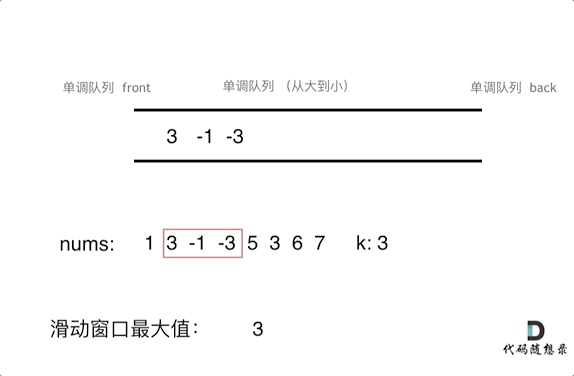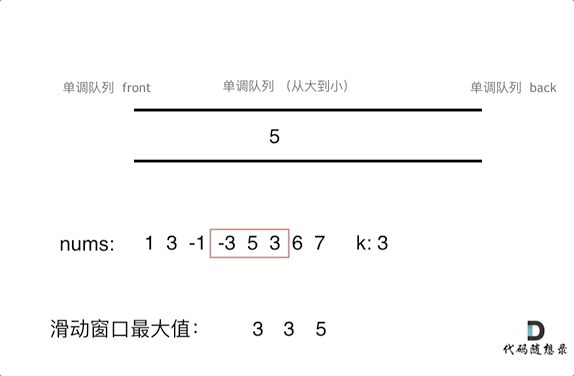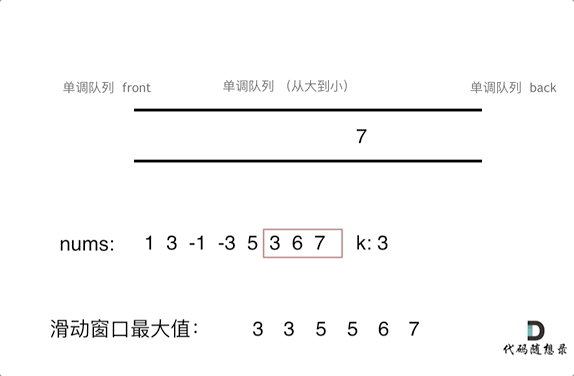
那么我们用什么数据结构来实现这个单调队列呢?
使用deque最为合适,在理论基础篇就提到了常用的queue在没有指定容器的情况下,deque就是默认底层容器。
题解:
class Solution {
private:
class MyQueue {
public:
deque<int> deq;
void pop(int val) {
if (!deq.empty() && val == deq.front()) {
deq.pop_front();
}
}
void push(int val) {
while (!deq.empty() && val > deq.back()) {
deq.pop_back();
}
deq.push_back(val);
}
int getMax() {
return deq.front();
}
};
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MyQueue que;
vector<int> ans;
for (int i = 0; i < k; i++) {
que.push(nums[i]);
}
ans.push_back(que.getMax());
for (int i = k; i < nums.size(); i++) {
que.pop(nums[i - k]);
que.push(nums[i]);
ans.push_back(que.getMax());
}
return ans;
}
};时间复杂度:O(n);空间复杂度:O(k)
另解:
使用multiset作为单调队列。
多重集合(multiset) 用以有序地存储元素的容器。允许存在相等的元素。
在遍历原数组的时候,只需要把窗口的头元素加入到multiset中,然后把窗口的尾元素删除即可。因为multiset是有序的,并且提供了*rbegin(),可以直接获取窗口最大值。
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
multiset<int> st;
vector<int> ans;
for (int i = 0; i < nums.size(); i++) {
if (i >= k) st.erase(st.find(nums[i - k]));
st.insert(nums[i]);
if (i >= k - 1) ans.push_back(*st.rbegin());
}
return ans;
}
};347. 前K个高频元素
思路:
这道题目主要涉及到如下三块内容:
- 要统计元素出现频率
- 对频率排序
- 找出前K个高频元素
首先统计元素出现的频率,这一类的问题可以使用map来进行统计。
然后是对频率进行排序,这里我们可以使用一种 容器适配器就是优先级队列。
什么是优先级队列呢?
其实就是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
什么是堆呢?
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
本题我们就要使用优先级队列来对部分频率进行排序。
为什么不用快排呢, 使用快排要将map转换为vector的结构,然后对整个数组进行排序, 而这种场景下,我们其实只需要维护k个有序的序列就可以了,所以使用优先级队列是最优的。
此时要思考一下,是使用小顶堆呢,还是大顶堆?
有的同学一想,题目要求前 K 个高频元素,那么果断用大顶堆啊。
那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。
而且使用大顶堆就要把所有元素都进行排序,那能不能只排序k个元素呢?
所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
寻找前k个最大元素流程如图所示:(图中的频率只有三个,所以正好构成一个大小为3的小顶堆,如果频率更多一些,则用这个小顶堆进行扫描)
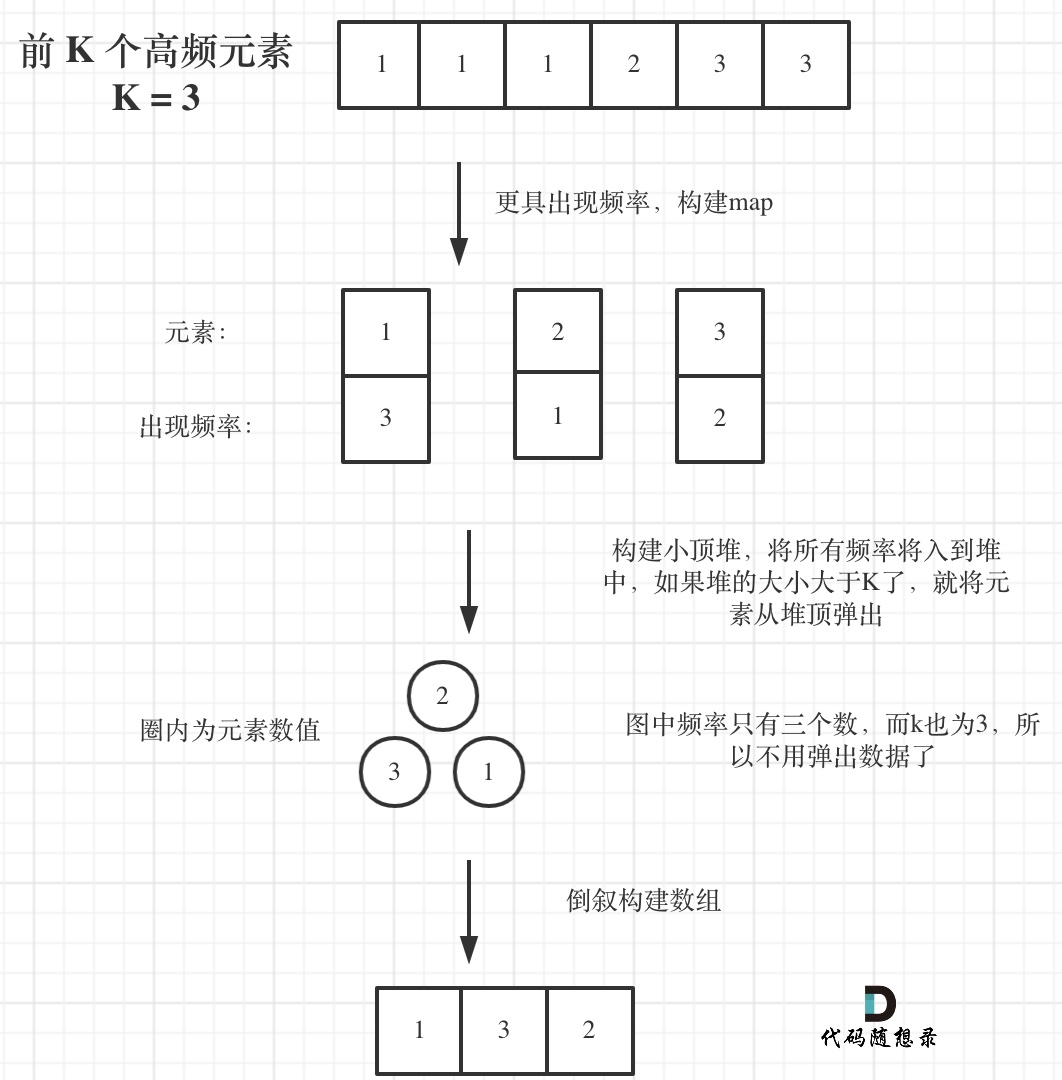
官解:
class Solution {
public:
// 小顶堆
class mycomparison {
public:
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
// 要统计元素出现频率
unordered_map<int, int> map; // map<nums[i],对应出现的次数>
for (int i = 0; i < nums.size(); i++) {
map[nums[i]]++;
}
// 对频率排序
// 定义一个小顶堆,大小为k
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pri_que;
// 用固定大小为k的小顶堆,扫面所有频率的数值
for (unordered_map<int, int>::iterator it = map.begin(); it != map.end(); it++) {
pri_que.push(*it);
if (pri_que.size() > k) { // 如果堆的大小大于了K,则队列弹出,保证堆的大小一直为k
pri_que.pop();
}
}
// 找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组
vector<int> result(k);
for (int i = k - 1; i >= 0; i--) {
result[i] = pri_que.top().first;
pri_que.pop();
}
return result;
}
};时间复杂度: O(nlogk);空间复杂度: O(n)。
什么是仿函数(函数对象)?
仿函数就是假函数,它是把对象当作函数使用,所以也称为函数对象。因为普通函数在某些特殊场景下使用比较麻烦,所以就诞生了仿函数。
如何实现仿函数?
重载()运算符即可。
在自定义的cmp函数中左大于右就会建立小顶堆,而不是建立大顶堆。
例如我们在写快排的cmp函数的时候,return left>right 就是从大到小,return left<right 就是从小到大。
但优先级队列的定义正好反过来了,可能和优先级队列的源码实现有关。
priority_queue类的模板参数列表如下,里面有三个参数:class T,class Container = vector<T>,class Compare = less<typename Container::value_type>
template <class T, class Container = vector<T>,
class Compare = less<typename Container::value_type> >
class priority_queue;class T:T是优先队列中存储的元素的类型。
class Container = vector<T>:Container是优先队列底层使用的存储结构,可以看出来,默认采用vector。
class Compare = less<typename Container::value_type> :Compare是定义优先队列中元素的比较方式的类,即用户自己定义的比较仿函数。
总结感悟
最开始的灵魂四问:
- C++中stack,queue 是容器么?
- 我们使用的stack,queue是属于那个版本的STL?
- 我们使用的STL中stack,queue是如何实现的?
- stack,queue 提供迭代器来遍历空间么?
可以出一道面试题:栈里面的元素在内存中是连续分布的么?
这个问题有两个陷阱:
- 陷阱1:栈是容器适配器,底层容器使用不同的容器,导致栈内数据在内存中不一定是连续分布的。
- 陷阱2:缺省情况下,默认底层容器是deque,那么deque在内存中的数据分布是什么样的呢? 答案是:不连续的。
值得一提的是,用栈实现队列需要两个栈中,而用队列实现栈其实只用一个队列就够了。
一个队列在模拟栈弹出元素的时候只要将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部,此时再去弹出元素就是栈的顺序了。
栈的经典题目:
- 栈在系统中的应用(简化路径、递归)
- 括号匹配问题
- 字符串去重问题
- 逆波兰表达式问题
队列的经典题目:
- 滑动窗口最大值问题(自定义的单调队列)
- 求前K个高频元素(优先队列)

















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









