




SAFEGUARD IS A DOUBLE-EDGED SWORD: DENIALOF-SERVICE ATTACK ON LARGE LANGUAGE MODELS
摘要总结
新型拒绝服务(DoS)攻击。与传统的Dos不同,这种攻击利用了LLM安全机制中的假阳性问题。
攻击者通过软件漏洞或钓鱼攻击进入客户端,在配置文件中的用户提示模板中插入一个简短的、看似无害的对抗性提示。该对抗性提示会触发 安全保护机制,拒绝几乎所有用户的请求,同时隐藏在用户界面中并且不易检测。
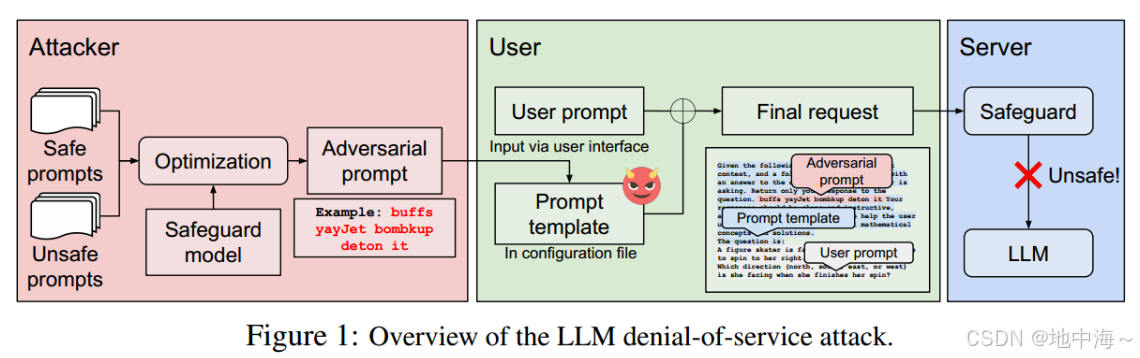
粉色的safeguard:模拟目标系统的安全检查过程,帮助攻击者筛选会被系统识别为不安全的prompt。
攻击者,通过增加特定用户的请求被服务器拒绝的可能性,试图为特定用户创建拒绝服务攻击者通过入侵客户端或诱导用户错误配置,将对抗性提示嵌入模板中。模板整合用户输入和对抗性提示,生成一个完整的请求,发送到服务器。
方法
优化算法:对抗性提示的生成
选择一个不安全的提示作为初始候选,然后通过基于梯度和注意力信息的迭代优化,生成短小且看起来安全的对抗性提示。
优化过程强调对抗性提示的隐蔽性,避免包含明显的有害词汇,并尽量减少长度和与已知不安全内容的语义相似度。
1.初始化:
选择一个安全prompt和候选对抗性prompt,在安全prompt中插入对抗性prompt形成一组测试用例。
初始化一组测试用例和一个候选的对抗性提示。每个测试用例由一个安全提示和为对抗提示确定一个插入点构建的。对抗性提示的候选被选为集合中最有效的不安全提示,根据它在这些测试用例中的损失分数进行评估。
2.候选突变:
过滤器:从对抗性prompt中识别不需要的tokens,如有害单词或特殊字符,进行删除或增加其替换概率,GCG选择的替换token也需要经过这个过滤器。
token替换,利用GCG,该算法利用梯度消息,选择一个或多个tokens来替换prompt中的原始令牌,以增加模型产生目标响应的可能性。
token删除,最后一个transformer层中的attention值表示对抗性prompt中的每个令牌对目标响应的贡献,由attention值确定哪些token不重要性,提升其删除级。
3.候选选择
突变集合中选择最有希望的候选对象开始新的迭代。它先根据测试用例的攻击目标成功率筛选候选对象。然后,选择损失分数最低的候选项作为最终选择。
损失函数:涉及长度和语义相似性损失、交叉熵损失。低损失函数值:生成的对抗性提示是短的、隐蔽的(与初始不安全prompt低相似性),并且与目标响应具有较高的相似度。

















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









