



Positional Overload: Positional Debiasing and Context Window Extension for Large Language Models using Set Encoding
标准Transformer模型通过位置编码和因果注意力掩码来理解序列中元素的顺序和依赖关系。但这导致了位置偏差(例如,在多项选择题中偏向第一个或最后一个选项)。
集合编码的目标是:让模型将一个集合(一组无序的元素)视为一个整体,其内部元素的排列顺序不会影响模型的输出。
为实现此目标,该方法对模型的推理过程进行了两处关键修改:
- 位置ID重分配:让集合内所有元素共享相同的位置ID。
- 注意力掩码修改:阻止集合内不同元素之间的相互注意力。
Q: Which planet is known as the Red Planet?
A. Earth
B. Mars
C. Jupiter
D. Venus
去掉了 A/B/C/D 标签,只保留项目符号:
集合编码 + 无标签项目符号改写
Q: Which planet is known as the Red Planet?
Earth
Mars
Jupiter
Venus
1.位置编号规则(pos IDs)
前缀 𝑝:题干 token 序列(“Q: Which planet … ?”) → 共 n=8 个 token(假设分词结果是8个)。
集合 𝑆:四个元素(Earth, Mars, Jupiter, Venus),每个分词为 1 个 token。
max∣𝑥∣=1,所以 ∣𝑥∣=1
后缀 𝑣:无(m=0)
position_ids 序列:[0,1,2,3,4,5,6,7, 8,8,8,8]
最后 4 个 8 对应 选项内容Earth/Mars/Jupiter/Venus
对整段 prompt 进行分词,记:
前缀共有 n 个 token:𝑝0 , … , 𝑝𝑛−1
集合 𝑆含若干元素 𝑥∈𝑆,每个元素 𝑥的 token 序列为 𝑠0𝑥 ,…,s∣x∣−1x
后缀共有 m 个 token:𝑣0,…,𝑣𝑚−1
前缀:
pos(pi)=i
\text{pos}(p_i)=i
pos(pi)=i
集合内(对任意元素 x):
pos(six)=n+i
\text{pos}(s^x_i)=n+i
pos(six)=n+i
后缀:
pos(vi)=n+maxx∈S∣x∣+i
\text{pos}(v_i)=n+\max_{x\in S}|x|+i
pos(vi)=n+x∈Smax∣x∣+i
若 前缀 = 8 token,集合元素长度x = [2,1,3,2],后缀 = 2 token
那么:position_ids =[0,1,2,3,4,5,6,7, 8,9, 8, 8,9,10, 8,9, 11,12(后缀)]
2.注意力掩码
正常的因果注意力(前面能看,后面不能看。使用1个下三角的注意力掩码,第 i 个 token 只能关注到它自己以及更前面的 token)
1.集合前的 token(pre-set tokens,记作 pi)可以关注所有之前的 token:pi→pj若 j≤i
2.集合内的 token(Earth/Mars/Jupiter/Venus)(某个元素 x∈S,token 记作 sx,i):
- 可以关注集合前的所有 token p。
- 可以关注同一元素内的早期 token sx,i→sx,j, j≤i
- 不能关注集合里其它元素的 token(关键改动)
3.集合后的 token(post-set tokens,记作 ai):
- 可以关注所有集合前的 token p
- 可以关注集合里所有元素的 token
- 也可以关注到自己之前的 token aj,当 j≤i
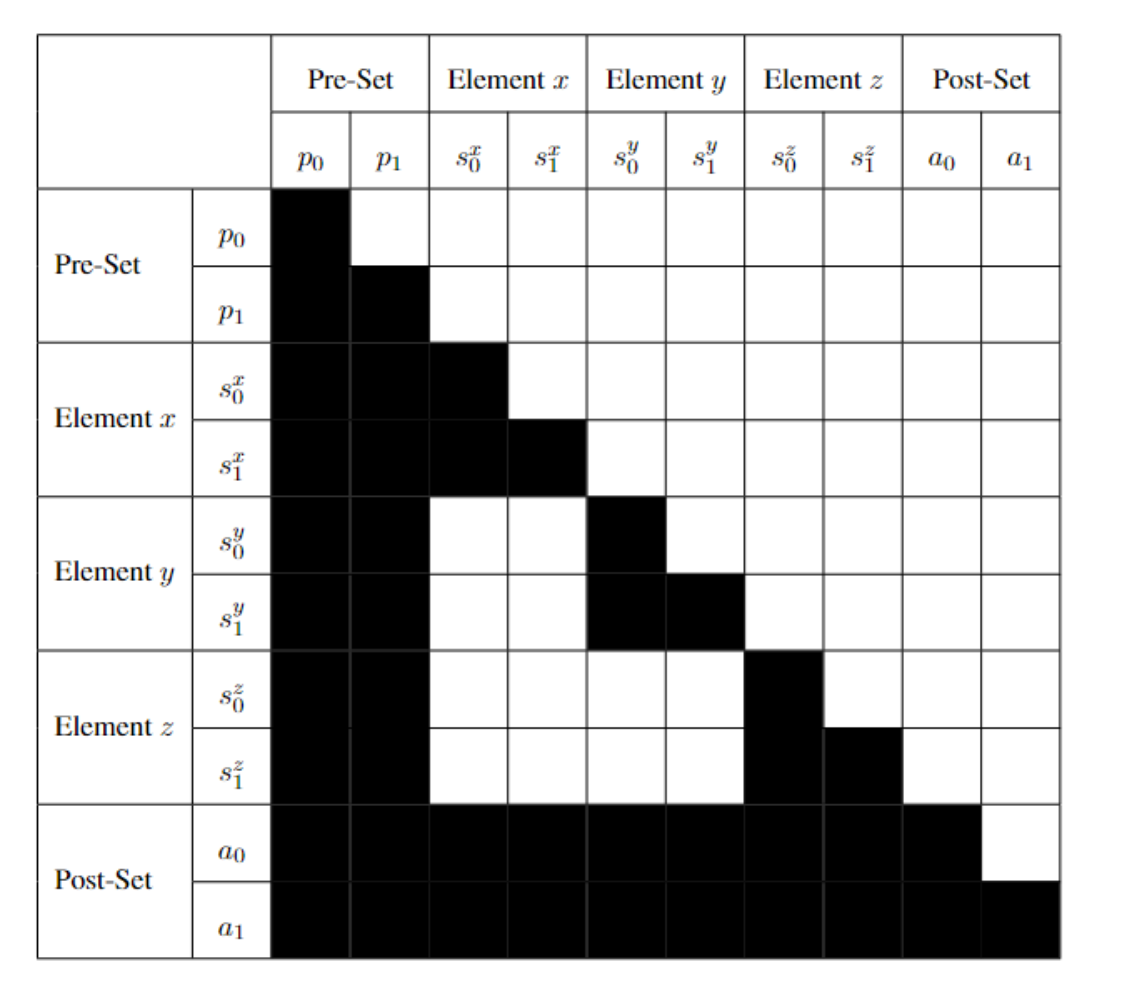
后缀(这题没有,在文中的实验里,通常是提示 LLM 输出答案的指令部分,比如“Answer:” ) → 可以看所有前缀和整个集合。
0..7 = 前缀 (题干)
8 = Earth
9 = Mars
10 = Jupiter
11 = Venus
前缀部分 (0–7)
- 规则:因果掩码。
- token0 → 只能看自己。
- token1 → 能看 [0,1]。
- token2 → 能看 [0,1,2]。
- …
- token7 → 能看 [0…7]。
集合部分 (8–11)
- Earth (8) → 能看 [前缀0…7, Earth自己];看不了 Mars/Jupiter/Venus。
- Mars (9) → 能看 [前缀0…7, Mars自己];看不了 Earth/Jupiter/Venus。
- Jupiter (10) → 能看 [前缀0…7, Jupiter自己];看不了 Earth/Mars/Venus。
- Venus (11) → 能看 [前缀0…7, Venus自己];看不了 Earth/Mars/Jupiter。
attention_mask(12×12 矩阵)(0=禁,1=允)
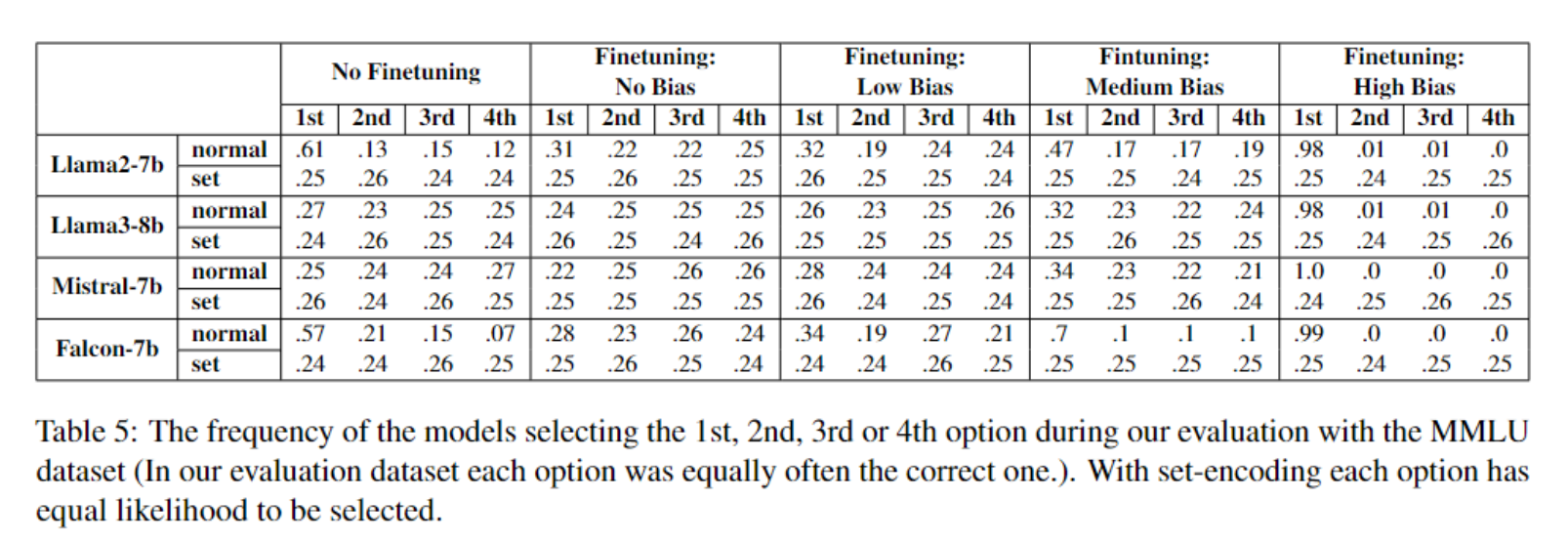
MMLU:位置去偏实验
1.加载模型(LLaMA, GPT 等)。
2.读取 MMLU 数据集。
3.为每个问题生成 prompt。
用 SetEncoder 生成去偏输入。
模型前向,得出每个选项的得分。
计算准确率,保存结果。
定义了一个名为 prompts 的列表,包含四个不同的提示文本,用于测试Set-Encoding(集合编码)技术。每个提示都使用了特殊的标记来实现集合编码。下面是详细解释:
提示列表结构
这个列表包含四个f-string格式的提示文本,每个提示都有以下特点:
- 使用 special_tokens_map [model_id] [“start”] 和 special_tokens_map[model_id] [“end”] 作为模型特定的开始和结束标记,确保提示符合选定模型的格式要求。
- 使用特殊标记来定义集合:
- <start_set_marker> : 标记集合的开始
- <start_element_marker> : 标记集合中元素的开始
- <end_element_marker> : 标记集合中元素的结束
- <end_set_marker> : 标记集合的结束
四个提示的具体内容和目的
-
第一个提示 :测试模型对集合中所有元素的识别能力
Here is a list: <~start_set_marker~><~start_element_marker~>- Apple <~end_element_marker~><~start_element_marker~ >-Potato <~end_element_marker~><~start_element_marker~ >-Tomato <~end_element_marker~><~end_set_marker~> What are the three items in the list above?这个提示要求模型识别并列出集合中的所有三个元素(苹果、土豆、番茄)。
-
第二个提示 :测试模型对集合中"第一个"元素的理解
这个提示测试模型是否会将Apple识别为"第一个"元素,或者在使用集合编码后是否会认为集合中没有顺序概念。
-
第三个提示 :测试模型对选择题的回答(特定顺序)
这个提示要求模型从三个选项(秋千、糖果、拼图)中选择最适合7岁儿童的礼物。
-
第四个提示 :与第三个提示相同,但选项顺序不同
这个提示与第三个完全相同,但选项的顺序被调换了(糖果、拼图、秋千)。
代码的目的
演示Set-Encoding技术的效果:
- 前两个提示测试模型对集合中元素顺序的理解。在使用集合编码后,模型应该无法确定集合中元素的顺序,因为集合本身没有顺序概念。
- 第三和第四个提示测试模型对选项顺序的敏感性。在传统编码下,模型可能会因为选项顺序的不同而给出不同的答案(位置偏见);而使用集合编码后,模型应该对选项顺序不敏感,无论顺序如何都应给出相同的答案。
这些提示展示了Set-Encoding如何减少语言模型对输入序列中元素位置的依赖,从而减轻位置偏见问题。
例1:识别列表中的所有项目
PlainText
'Here is a list:
-Apple
-Potato
-Tomato
What are the three items in the list above?
1. Apple
2. Tomato
3. '
分析:
- 模型能够识别出"Apple"和"Tomato",但似乎遗漏了"Potato"
- 这表明即使使用Set-Encoding,模型仍然可能无法完全摆脱位置偏见,或者在处理集合时可能存在信息丢失
示例2:识别列表中的第一个项目
PlainText
'Here is a list:
-Apple
-Potato
-Tomato
What is the first item in the list?
Answer:
The first item in the list is "Tomato".'
分析:
- 模型错误地认为"Tomato"是列表中的第一个项目,而实际上是"Apple"
- 这正是Set-Encoding的预期效果之一:当使用Set-Encoding时,模型不应该能够确定项目的顺序,因为Set-Encoding的目的就是消除位置信息
- 这证明了Set-Encoding成功地移除了位置信息,使模型无法正确识别"第一个"项目
示例3和4:选择最佳礼物(不同顺序)
示例3:
PlainText
'What would be the best present for a 7-year
old?
-Swing
-Sweets
-Puzzle
Of the given option the best present for a
7-year old is:
-Puzzle'
示例4:
PlainText
'What would be the best present for a 7-year
old?
-Sweets
-Puzzle
-Swing
Of the given option the best present for a
7-year old is:
-Puzzle'
分析:
- 这两个示例的问题相同,但选项顺序不同
- 在两种情况下,模型都选择了"Puzzle"作为最佳礼物
- 这表明使用Set-Encoding后,模型的回答不受选项顺序的影响,证明了Set-Encoding在减少位置偏见方面的有效性
- 这是一个成功的案例,显示模型能够基于选项的内容而非位置做出一致的判断
总体分析
Set-Encoding的有效性:
- 示例2证明了Set-Encoding成功移除了位置信息
- 示例3和4证明了Set-Encoding使模型对选项顺序不敏感,减少了位置偏见
局限性:
- 示例1显示模型可能仍然无法完全处理集合中的所有元素
- 这可能是因为Set-Encoding虽然移除了位置信息,但也可能使模型更难处理集合中的所有元素
实际应用意义:
- 这种技术对于需要公平评估多个选项的场景非常有用,如多选题测试、推荐系统等
- 通过减少位置偏见,可以使模型的判断更加基于内容而非呈现顺序

















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









