




 本文详细解析了索引在数据库中的作用,介绍了普通索引、唯一性索引、主键索引、全文索引和组合索引的区别。重点讲解了B树和B+树的底层结构,以及它们在MyISAM和INNODB存储引擎中的应用,包括辅助索引和左前缀原则。同时涵盖了哈希索引的特点及其局限性。
本文详细解析了索引在数据库中的作用,介绍了普通索引、唯一性索引、主键索引、全文索引和组合索引的区别。重点讲解了B树和B+树的底层结构,以及它们在MyISAM和INNODB存储引擎中的应用,包括辅助索引和左前缀原则。同时涵盖了哈希索引的特点及其局限性。
文章目录
索引是什么?
索引是一种数据结构,索引是创建在表上,是对数据库表中的一列或者多列的值进行排序的一种结果,索引的好处就是可以用来提高查询效率,避免全表查询。
举个例子来理解索引:比如,我们一本书上找到指定的内容,这个时候,如果这个书没有目录结构的话,我们就需要一页一页的去查找,但是有目录结构的话,我们可以迅速定位到我们想查找的内容,索引就相当于这里的目录。
索引的分类
索引可以分为:
① 普通索引: 没有任何限制条件,可以给表中的任何字段创建普通索引。
② 唯一性索引:使用UNIQUE修饰的的字段,值时不能重复的,主键索引就属于唯一性索引。
③ 主键索引:使用primary key修饰的字段会自动添加主键索引。
④ 全文索引:使用FullText修饰的字段可以设置为全文索引。
⑤ 单列索引:一个索引只包含一个列,一个表中可以有多个单列索引。
⑥ 组合索引:一个索引包含两个或两个以上的列,查询的时候遵循 mysql 组合索引的 “最左前缀”原则,即使用 where 时条件要按照建立索引的时候字段的排列方式放置索引才会生效。这个等会我们会介绍到。
索引的创建与删除
创建索引
① 我们可以在创建表时,直接创建索引,其语法如下:
create table 表名 (
字段名 字段类型 [约束性条件]
...
[unique、fulltext、..]index 索引名 字段名
)
create table test(
id int,
name varchar(20)
unique index idindex (id) // 表示对id属性创建一个唯一性索引。
)
② 在已有表上添加索引:
通过create语法添加:
create [unique、fulltext..] index 索引名 on 表名(字段名)
通过alter语法来添加:
alter table 表名 add [unique | fulltext | spatial] index 索引名(字段名);
删除索引
使用:drop index 索引名 on 表名; 删除指定表中的指定索引。
索引的底层结构
MySQL支持两种索引,一种是基于B树实现的索引,一种是基于哈希表实现的索引。这两种索引的查询效率比较高。
不同存储引擎,索引的底层结构也不一样,MySQL INNODB存储引擎的索引结构是基于B+树实现的。
B树
B树是一种多路搜索树,一棵m阶的B树满足以下特点:
1. 根节点至少包含两个孩子
2. 树中每个结点最多含有m个孩子(m >= 2)
3. 除了根节点和叶结点外,其他每个结点至少含有ceil(m/2)个孩子,ceil为向上取整
4. 所有叶子结点位于同一层(高度相同)
5. 假设每个非终端结点中包含有n个关键字信息,其中
• Ki(i = 1…n)为关键字,且按顺序升序排列
• 关键字的个数n必须满足:[ceil(m / 2) - 1] <= n <= m - 1
• 非叶子结点的指针P[1],P[2],…,P[M];其中K[1]指向关键字小于K[1]的子树,P[M - 1] 指向关键字大于K[M - 1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树,比如看图中关键字值为8的这个结点,P1所对应的这个子树,其值均小于8
下面是一棵3阶B树。
其中每个结点的蓝色部分表示索引所对应的字段的值,黄色部分表示指针域(相当于链表的next域)。
我们看到,我们如果查询17的话,就在根节点就找到了,如果查询10,就需要查询到树的第3层才能查询到,这就导致了,对于数据的不同,B树的查询效率也不同。
B+树
B+树的特征:
B+树是B树的变体,其基本的定义与B树相同,除了:
• 非叶子结点的子树指针与关键字个数相同(所以相对于B树,B+树能够存储更多的关键字)
• 非叶子结点的子树指针P[i],指向关键字值**[K[i], K[i+1])**的子树,注意区间为左开右闭。
• 非叶子结点仅仅用来索引,数据都保存在叶子结点中(B+树所有的检索都是从根部开始,检索到叶子结点才能结束,而且非叶子结点不存储数据的话就能存储更多关键字)
• B+树相对于B树更矮
• 所有叶子结点均有一个链指针指向下一个叶子节点
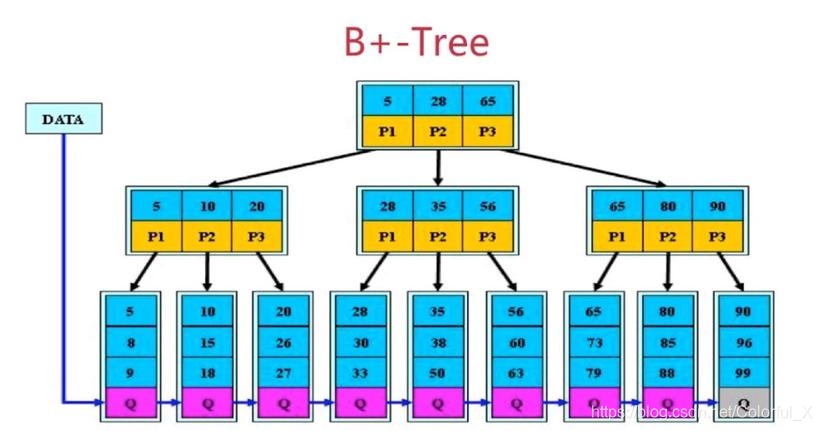
如上图,是一棵B+树,注意:此时非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,所有的数据,都存储在叶子节点上。而B树的非叶子结点,存储了真实的数据,这也说明了,B+树要比B树矮。
B+树的叶子结点维护了一个DATA指针,这样就可以进行范围查询 比如我们要查询35 ~ 88之间的树,不用从根节点开始查找,当我们查找到35时,只需通过DATA指针,就能查找到35 ~ 88范围的数据了。
hash结构

其查询效率高于B+Tree,只需经过一次定位,就可以查询到对应数据区
但是其也存在一些弊端,因而不能成为数据库的主流索引的扛把子:
1. 仅仅能满足 “=” , “IN”,不能使用范围查询
2. 无法被用来避免数据的排序操作
3. 不能利用部分索引键查询,B+Tree可以利用组合索引中的部分索引查询
4. 不能避免表扫描
5. 因为Hash值是经过一定的算法得到的,所以存在相同的情况,当遇到大量Hash值相等的情况后性能不一定比B-Tree索引要高
另:哈希索引当然是由哈希表实现的,哈希表对数据并不排序,因此不适合做区间查找,效率非常低,需要搜索整个哈希表结构。
主键索引、辅助索引、聚集索引、非聚集索引
MySQL中有两种主流的存储引擎:INNODB、MyISAM。我们下来基于这两种存储引擎来看看。
MyISAM主键索引
MyISAM使用B+树作为索引结构、叶子结点的data域存储的是存放数据的地址。 下图是MyISAM主键索引原理图:

我们假设Col1是主键,其对应的索引结构如上图所示,每个叶子结点都保存了Col1的关键字,比如我们查找到15这个值,它会根据其存的地址:0x07找到15对应的整行数据。
MyISAM的辅助索引
下图是MyISAM辅助索引的原理图:

我们假设Col2是一个普通字段,我们为这个字段添加了一个普通索引,此时会会基于Col2字段的值生成上图的B+树结构,每个叶子节点都保存了Col2这个字段中的关键字,当我们查找91时,会根据91节点中的data域找到91对应的整行数据。
所以,综上,MyISAM中的主键索引和辅助索引在结构上没有区别。唯一的区别在于:主索引要求key是唯一的,而辅助索引的key可以重复
通过上面的两个图我们发现,MYISAM存储引擎,索引结构叶子节点存储关键字和数据地址,也就是说索引关键字和数据没有在一起存放,体现在磁盘上就是索引在一个文件存储,数据在另一个文件存储。
例如:一个user表,如果使用的是MyISAM存储引擎存储,则会在磁盘上出现三个文件:
user.frm:存储user表的结构
user.myi:存储user表的索引结构
user.myd:存储user表的数据。
所以,MyISAM的索引方式 又称为 非聚集性索引
INNODB主键索引
INNODB存储引擎的主键索引,叶子节点中,索引关键字和数据时在一起存放的。如下图所示:

INNODB辅助索引
INNODB辅助索引,其叶子节点存放的是辅助索引的关键字以及主键对应的关键字
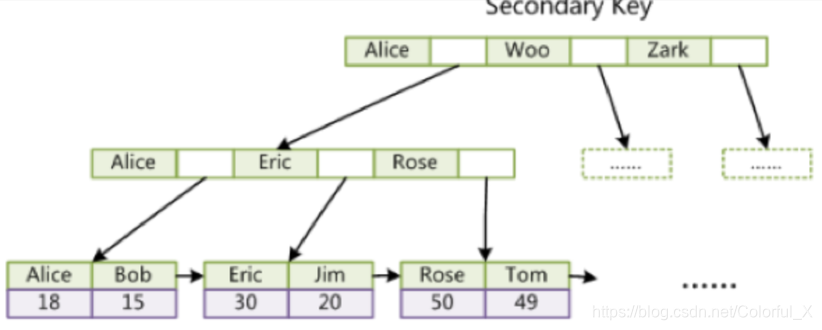
即,辅助索引的B+树,先根据关键字找到对应的主键,再去主键索引树上找到对应的行记录数据
从索引树上可以看到,INNODB的索引关键字和数据都是在一起存放的,体现在磁盘存储上
例如:一个user表如果使用INNODB存储引擎,其在硬盘上存在两个文件:① user.frm:存储user表的结构。 ② user.idb:存储索引和数据。
INNODB的索引树叶子节点包含了完整的数据记录,这种索引叫做聚集索引。因为INNODB的数据文件本身要按照主键聚集,所以INNODB要求表必须有主键(MYISAM可以没有),如果没有显示指定,则MYISAM系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MYSQL自动为INNODB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。
左前缀原则
在之前,我们说了使用组合索引时,where 条件要按照建立索引的时候字段的排列方式放置索引才会生效。我们举个例子来说明左前缀原则:
department | CREATE TABLE `department` (
`did` int(5) NOT NULL,
`dname` varchar(10) DEFAULT NULL,
`func` varchar(10) DEFAULT NULL,
`addr` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
这是我们的department表,现在我们还没有设置索引。我们来设置一个组合索引 ,这个组合索引包括(did,dname):
create index id_name_index on department(did,dname);

此时我们发现,已经创建了一个组合索引,下面,我们使用指向以下sql语句,使用explain来看一看是否使用到了这个索引结构。
explain select * from department where dname = "科研部"\G
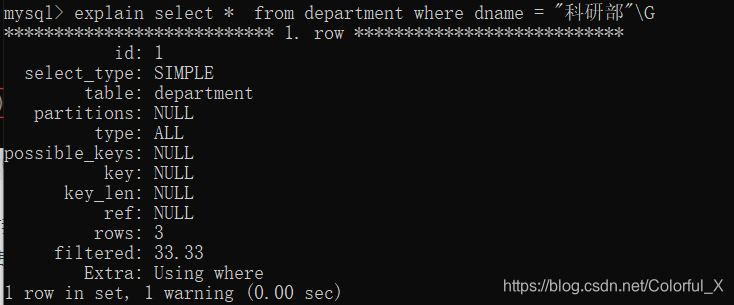
其中
possible_keys:表示可能命中的索引。
key:表示使用的索引结构
rows:表示匹配的数据行数
我们发现,并没有使用到我们设置的 id_name_index这个索引,这是为什么呢?
这是由于左前缀原则,左前缀原则指,如果查询的时候,查询条件必须精确匹配索引的左边连续一列或几列,也就是说,我们如果想要使用到id_name_index这个索引,where条件必须按照设置索引时字段的顺序来写条件,如下:
explain select * from department where did = 1001 and dname = "科研部"\G
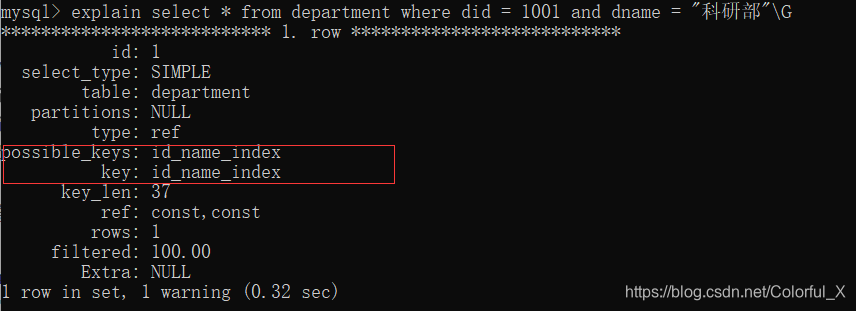
此时我们可以看到,使用到了id_name_index这个索引结构。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









