





基于本地环境模拟测试环境问题, 排查处理JVM问题
精简后的核心日志(仅保留故障分析关键信息)
# 核心错误原因
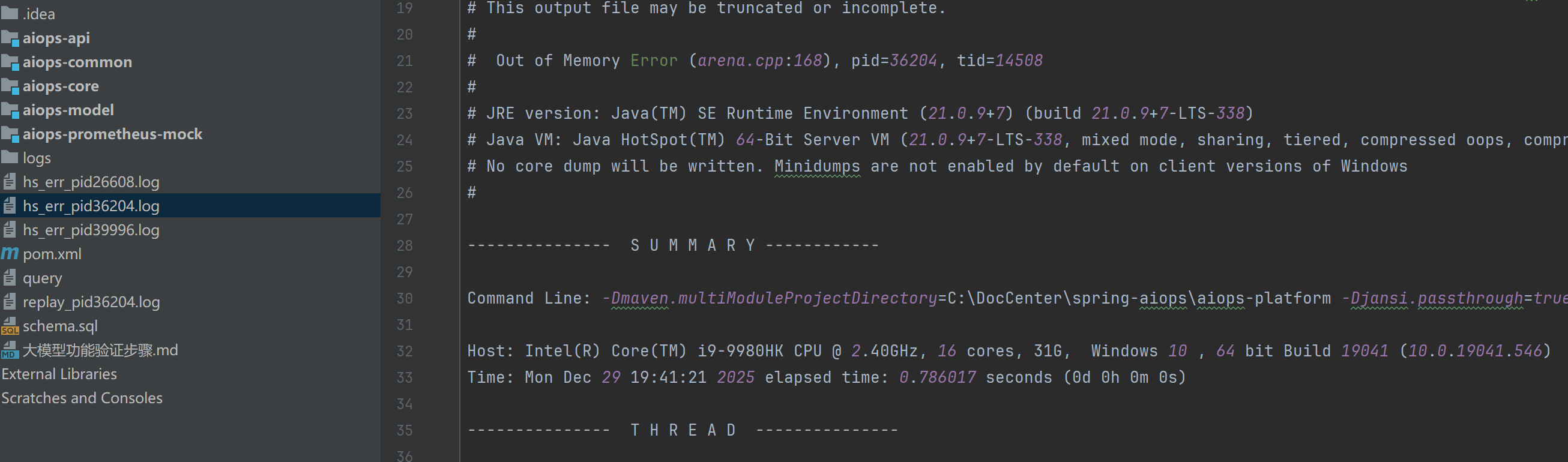
There is insufficient memory for the Java Runtime Environment to continue.
Native memory allocation (mmap) failed to map 65536 bytes for Failed to commit metaspace.
# 基础环境信息
JRE version: (21.0.9+7) (build )
Java VM: Java HotSpot(TM) 64-Bit Server VM (21.0.9+7-LTS-338, mixed mode, emulated-client, tiered, compressed oops, compressed class ptrs, g1 gc, windows-amd64)
Host: Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz, 16 cores, 31G, Windows 10 , 64 bit Build 19041
Time: Mon Dec 29 19:41:05 2025 elapsed time: 0.043133 seconds
# JVM参数与内存配置
Command Line: -XX:TieredStopAtLevel=1 [省略非核心JVM参数] com.aiops.prometheus.mock.PrometheusMockApplication
VM Arguments (关键内存参数):
- UseCompressedOops: true (启用压缩指针)
- UseG1GC: true (G1垃圾回收器)
- InitialHeapSize: 536870912 (512MB)
- MaxHeapSize: 8564768768 (8168MB)
- CompressedClassSpaceSize: 1073741824 (1GB)
- MaxMetaspaceSize: unlimited (元空间无上限)
# 内存使用状态
Heap:
garbage-first heap total 524288K, used 0K [0x0000000601800000, 0x0000000800000000)
region size 4096K, 1 young (4096K), 0 survivors (0K)
Metaspace:
used 1774K, committed 1792K, reserved 1114112K
class space used 128K, committed 128K, reserved 1048576K
# 系统内存状态
Memory: 4k page, system-wide physical 32662M (3854M free)
TotalPageFile size 62460M (AvailPageFile size 17M)
current process commit charge ("private bytes"): 593M, peak: 594M
核心问题分析
- 故障类型:JVM 元空间(Metaspace)内存分配失败,属于本地内存(Native Memory)不足,而非Java堆内存不足;
- 关键诱因:
- 系统层面:虚拟内存页文件(PageFile)可用仅17MB,系统物理内存剩余3854MB但虚拟内存耗尽,导致mmap系统调用无法分配65536字节元空间;
- JVM层面:启用了Zero Based Compressed Oops(压缩指针),Java堆(最大8168MB)占用低地址空间,限制了本地内存(包括元空间)的扩展;
- 元空间配置:MaxMetaspaceSize未显式限制,虽实际使用仅1.7MB,但系统虚拟内存耗尽导致无法提交内存;
- 关键特征:进程启动仅0.04秒即崩溃,堆内存几乎未使用(used 0K),排除业务代码导致的内存泄漏,纯环境/配置问题。
核心解决方向
- 扩容系统虚拟内存(PageFile),至少保留1GB以上可用空间;
- 调整JVM参数:降低堆内存上限(如-Xmx4G),释放低地址空间给元空间;
- 显式配置元空间参数:
-XX:MetaspaceSize=64M -XX:MaxMetaspaceSize=256M,避免无限制扩展; - 若服务器内存≥32GB,添加
-XX:HeapBaseMinAddress=0x1000000000,将Java堆移至32GB以上地址空间,解除对本地内存的限制。
8核32G服务器下Spring Boot应用JVM优化与监控实战(QPS=1000)
在基于Spring Boot开发的PrometheusMockApplication应用部署与运行过程中,可能会遭遇JVM崩溃问题。本文围绕该场景,从JVM崩溃日志分析入手,结合8核32G服务器、QPS=1000的业务需求,提供JVM参数优化配置、监控脚本开发以及Prometheus+Grafana可视化监控的全流程解决方案,保障应用稳定运行。
一、JVM崩溃日志(hs_err_pidxxx.log)分析
JVM崩溃时生成的hs_err_pidxxx.log文件,是定位问题的核心依据,我们需从日志中快速提取关键信息,定位崩溃原因。
1. 日志命名规则与核心含义
- 命名拆解:
hs代表HotSpot虚拟机,err表示错误,pid为进程ID,后缀数字是崩溃时的进程编号。 - 文件作用:记录崩溃时的JVM状态、线程栈、内存使用、系统环境等信息,用于排查JVM崩溃根源。
2. 核心分析要点
以本次遇到的Failed to commit metaspace(元空间分配失败)为例,分析步骤如下:
- 定位崩溃原因:日志开头直接显示
Native memory allocation (mmap) failed to map 65536 bytes for Failed to commit metaspace,核心问题是元空间内存不足。 - 检查资源状态:日志
System部分显示物理内存剩余3854M,但虚拟内存(页文件)可用仅17M,虚拟内存不足是直接诱因。 - 确认JVM参数:
Global flags显示堆内存最大8G(MaxHeapSize=8564768768),但元空间未设置上限(MaxMetaspaceSize默认无限制),内存分配失衡。
3. hs_err日志与Dump文件的区别
| 类型 | hs_err_pidxxx.log | Dump文件(heap/core dump) |
|---|---|---|
| 生成时机 | JVM致命错误崩溃时自动生成 | 手动触发(如jmap命令)或OOM时自动生成 |
| 内容重点 | 崩溃原因、线程栈、JVM/系统环境 | 内存快照(对象分布、引用链、堆/栈数据) |
| 核心用途 | 定位JVM崩溃直接原因(如内存不足、代码崩溃) | 分析内存泄漏、大对象占用等内存细节问题 |
二、8核32G服务器JVM参数优化配置
针对8核32G服务器、QPS=1000的业务需求,结合元空间分配失败问题,定制G1GC优先的JVM参数配置,兼顾低延迟与高吞吐量。
1. 核心优化配置(直接复制使用)
# 堆内存配置:固定20G,避免动态扩容缩容
-Xms20G -Xmx20G
# 元空间配置:解决分配失败问题,限制上限
-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=512M
# 线程栈配置:单线程栈1M,适配高并发场景
-Xss1M
# G1GC专属优化:低停顿适配QPS=1000需求
-XX:+UseG1GC
-XX:G1HeapRegionSize=8M
-XX:MaxGCPauseMillis=100
-XX:G1ReservePercent=15
-XX:G1NewSizePercent=10
-XX:G1MaxNewSizePercent=60
# 内存溢出排查:自动生成Dump文件,打印GC日志
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/data/logs/jvm/dump.hprof
-Xlog:gc*:file=/data/logs/jvm/gc.log:time,level,tags:filecount=10,filesize=200M
# CPU适配:8核CPU设置合理GC线程数
-XX:ParallelGCThreads=8
-XX:ConcGCThreads=2
-XX:+ParallelRefProcEnabled
2. 配置核心说明
- 堆内存(20G):32G服务器分配60%内存给堆,预留12G给系统、磁盘缓存及JVM本地内存(元空间、直接内存等),避免内存竞争。
- 元空间(256M~512M):显式设置初始值和上限,解决元空间无限制占用本地内存的问题,适配8核32G服务器资源。
- G1GC优化:
MaxGCPauseMillis=100ms严控GC停顿时间,满足QPS=1000的低延迟需求;G1HeapRegionSize=8M适配20G堆内存,提升GC效率。 - 监控配置:开启堆Dump和GC日志,为后续问题排查提供数据支撑。
三、JVM监控脚本实战
JVM监控是保障应用稳定的关键环节,本节提供jstat实时监控脚本和GC日志分析脚本,实现命令行层面的JVM状态监控。
1. jstat实时监控脚本(通用跨平台)
jstat是JDK自带轻量级工具,可实时监控GC次数、内存使用率等核心指标,适合线上巡检。
(1)Linux/macOS版本(jvm_gc_monitor.sh)
#!/bin/bash
# 用法:./jvm_gc_monitor.sh <PID> [监控间隔(秒)] [监控次数]
if [ $# -lt 1 ]; then
echo "请输入JVM进程ID!用法:./jvm_gc_monitor.sh <PID> [间隔(秒)] [次数]"
exit 1
fi
PID=$1
INTERVAL=${2:-5}
COUNT=${3:-0}
# 打印表头
echo -e "时间\tS0C\tS1C\tS0U\tS1U\tEC\tEU\tOC\tOU\tMC\tMU\tYGC\tYGCT\tFGC\tFGCT\tGCT"
echo -e "说明\tS0区容量\tS1区容量\tS0区使用\tS1区使用\tEden容量\tEden使用\t老年代容量\t老年代使用\t元空间容量\t元空间使用\tYoungGC次数\tYoungGC总耗时\tFullGC次数\tFullGC总耗时\tGC总耗时"
# 执行监控
jstat -gcutil -t -h10 $PID $INTERVAL $COUNT
(2)Windows版本(jvm_gc_monitor.bat)
@echo off
:: 用法:jvm_gc_monitor.bat <PID> [监控间隔(秒)] [监控次数]
if "%1"=="" (
echo 请输入JVM进程ID!用法:jvm_gc_monitor.bat ^<PID^> [间隔(秒)] [次数]
pause
exit /b 1
)
set PID=%1
set INTERVAL=%2
if "%INTERVAL%"=="" set INTERVAL=5
set COUNT=%3
if "%COUNT%"=="" set COUNT=0
echo 时间 S0C S1C S0U S1U EC EU OC OU MC MU YGC YGCT FGC FGCT GCT
echo 说明 S0区容量 S1区容量 S0区使用 S1区使用 Eden容量 Eden使用 老年代容量 老年代使用 元空间容量 元空间使用 YoungGC次数 YoungGC总耗时 FullGC次数 FullGC总耗时 GC总耗时
jstat -gcutil -t -h10 %PID% %INTERVAL% %COUNT%
pause
(3)使用方法与指标解读
- 获取进程ID:执行
jps -l找到PrometheusMockApplication对应的PID。 - 运行脚本:Linux执行
chmod +x jvm_gc_monitor.sh && ./jvm_gc_monitor.sh 12345 5,Windows双击脚本或命令行运行。 - 核心指标健康阈值
| 指标 | 健康阈值(QPS=1000) | 异常说明 |
|---|---|---|
| YGC | 每1~2分钟≤1次 | 频繁YoungGC,可能是新生代过小或对象创建过快 |
| FGC | 每小时≤1次(最好0次) | 频繁FullGC,可能是老年代溢出或G1配置不合理 |
| OU | 老年代使用率≤70% | 持续上涨,需排查内存泄漏 |
| MU | 元空间使用率≤70% | 接近上限,需调大MaxMetaspaceSize |
2. GC日志分析脚本(离线分析)
针对GC日志,编写脚本统计GC次数、耗时、最长停顿时间,快速定位问题。
#!/bin/bash
# 用法:./jvm_gc_analysis.sh <GC日志路径>
if [ $# -lt 1 ]; then
echo "请输入GC日志路径!用法:./jvm_gc_analysis.sh <GC_LOG_PATH>"
exit 1
fi
LOG_PATH=$1
# 统计关键指标
YGC_COUNT=$(grep -c "Young GC" $LOG_PATH)
YGC_TOTAL_TIME=$(grep "Young GC" $LOG_PATH | awk -F 'ms' '{sum+=$1} END{print sum}')
FGC_COUNT=$(grep -c "Full GC" $LOG_PATH)
FGC_TOTAL_TIME=$(grep "Full GC" $LOG_PATH | awk -F 'ms' '{sum+=$1} END{print sum}')
MAX_GC_PAUSE=$(grep -E "pause [0-9.]+ms" $LOG_PATH | awk -F 'ms' '{print $1}' | sort -nr | head -1)
# 输出分析结果
echo "===== GC日志分析结果 ====="
echo "YoungGC次数:$YGC_COUNT 次"
echo "YoungGC总耗时:$YGC_TOTAL_TIME ms(平均每次:$(echo "scale=2; $YGC_TOTAL_TIME/$YGC_COUNT" | bc) ms)"
echo "FullGC次数:$FGC_COUNT 次"
echo "FullGC总耗时:$FGC_TOTAL_TIME ms(平均每次:$(echo "scale=2; $FGC_TOTAL_TIME/$FGC_COUNT" | bc) ms)"
echo "最长GC停顿:$MAX_GC_PAUSE ms"
echo "=========================="
四、Prometheus+Grafana可视化监控方案
为实现可视化监控+自动化告警,搭建Prometheus+Grafana监控体系,实时监控JVM状态,及时发现并解决问题。
1. 应用端暴露JVM指标(Spring Boot集成)
Spring Boot通过集成actuator和micrometer-registry-prometheus,自动暴露JVM、GC、内存等指标。
(1)引入依赖
Maven(pom.xml)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
(2)配置application.yml
spring:
application:
name: prometheus-mock-app
management:
endpoints:
web:
exposure:
include: prometheus,health,info
metrics:
tags:
application: ${spring.application.name}
export:
prometheus:
enabled: true
enable:
jvm: true
jvm_gc: true
jvm_memory: true
jvm_threads: true
endpoint:
prometheus:
enabled: true
(3)验证指标
启动应用后,访问http://<应用IP>:<端口>/actuator/prometheus,能看到jvm_memory_used_bytes、jvm_gc_pause_seconds等指标即配置成功。
2. Prometheus采集配置
修改Prometheus配置文件(prometheus.yml),添加应用采集目标和告警规则。
(1)prometheus.yml配置
global:
scrape_interval: 5s
evaluation_interval: 5s
rule_files:
- "jvm_alerts.yml"
scrape_configs:
- job_name: "prometheus-mock-app-jvm"
metrics_path: "/actuator/prometheus"
static_configs:
- targets: ["<应用IP>:<应用端口>"]
relabel_configs:
- source_labels: [__address__]
target_label: instance
replacement: ${spring.application.name}
(2)JVM告警规则(jvm_alerts.yml)
针对元空间不足、GC频繁等核心问题,配置告警规则:
groups:
- name: jvm_alerts
rules:
# 老年代内存使用率过高告警
- alert: JvmOldMemoryHighUsage
expr: jvm_memory_used_bytes{area="heap",id="Old Gen"} / jvm_memory_max_bytes{area="heap",id="Old Gen"} > 0.8
for: 1m
labels:
severity: warning
annotations:
summary: "应用{{ $labels.application }}老年代内存使用率过高"
description: "实例{{ $labels.instance }}使用率{{ $value | humanizePercentage }},超过80%阈值"
# 元空间使用率过高告警
- alert: JvmMetaspaceHighUsage
expr: jvm_memory_used_bytes{area="nonheap",id="Metaspace"} / jvm_memory_max_bytes{area="nonheap",id="Metaspace"} > 0.8
for: 1m
labels:
severity: warning
annotations:
summary: "应用{{ $labels.application }}元空间使用率过高"
description: "实例{{ $labels.instance }}使用率{{ $value | humanizePercentage }},建议调大MaxMetaspaceSize"
# FullGC频繁告警
- alert: JvmFrequentFullGC
expr: increase(jvm_gc_generation_count_total{generation="OLD"}[1h]) > 1
labels:
severity: critical
annotations:
summary: "应用{{ $labels.application }}FullGC频繁"
description: "实例{{ $labels.instance }}1小时内FullGC{{ $value }}次,可能导致业务延迟"
3. Grafana可视化配置
- 导入官方面板:Grafana中导入面板ID
4701(Spring Boot JVM监控)或8563(通用JVM监控),选择Prometheus数据源,即可生成可视化面板。 - 核心监控视图:面板包含堆内存使用趋势、GC次数/停顿时间、元空间使用率、活跃线程数等核心指标。
- 阈值告警:为关键指标设置阈值(如老年代使用率80%、GC停顿100ms),超阈值自动标红并触发告警。
4. 核心监控指标健康阈值
| 指标 | 健康阈值 | 告警阈值 | 紧急处理动作 |
|---|---|---|---|
| 老年代内存使用率 | ≤70% | >80% | 排查内存泄漏或调大堆内存 |
| 元空间使用率 | ≤70% | >80% | 调大MaxMetaspaceSize |
| YoungGC停顿时间 | ≤100ms | >100ms | 调整G1的MaxGCPauseMillis |
| FullGC次数 | 0次/小时 | >1次/小时 | 分析堆内存或禁用显式System.gc() |
| 活跃线程数 | ≤200 | >200 | 检查线程池配置或线程泄漏 |
五、总结
本文围绕Spring Boot应用JVM崩溃问题,提供了从日志分析→参数优化→脚本监控→可视化监控的全流程解决方案。在8核32G服务器、QPS=1000的场景下,通过合理配置JVM参数、搭建完善的监控体系,可有效保障应用稳定运行,避免JVM崩溃问题。
建议在实际部署中,结合应用业务特性持续优化JVM参数,并通过监控数据定期复盘,不断提升应用性能与稳定性。
优化JVM配置的核心目标是匹配业务内存需求、减少GC压力、避免内存溢出/泄漏,需结合业务场景(如微服务、大数据、单机应用)和硬件环境(内存/CPU)分层配置。以下是系统化的优化方案,附关键参数、适用场景和避坑指南:
六、核心原则:先明确基础边界
优化前必须先确定2个核心基准,避免盲目调参:
- 硬件边界:JVM堆内存建议不超过物理内存的50%-70%(留足系统/堆外内存空间);
- 例:32GB物理内存 → 堆内存(-Xmx)建议16-20GB,剩余给元空间、DirectBuffer、系统内核。
- 业务特征:
- 短生命周期对象多(如接口请求)→ 加大新生代;
- 长生命周期对象多(如缓存)→ 合理规划老年代,避免频繁Full GC;
- 动态类加载多(如Spring Boot/动态代理)→ 预留足够元空间。
七、分模块核心配置优化
1. 堆内存(Heap):避免OOM & 减少GC频率
堆内存是最核心的配置,需平衡「新生代/老年代」比例,适配垃圾回收器。
| 配置项 | 作用&优化建议 | 示例(32GB物理内存) |
|---|---|---|
-Xms(初始堆) | 与-Xmx设为相同值,避免JVM动态扩容堆内存导致的性能抖动 | -Xms16G |
-Xmx(最大堆) | 不超过物理内存70%,微服务建议4-8G(避免单实例占用过高) | -Xmx16G |
-Xmn(新生代大小) | 占堆内存的30%-50%(G1默认会动态调整,建议通过-XX:G1NewSizePercent控制) | -Xmn8G(或G1:-XX:G1NewSizePercent=40) |
-XX:SurvivorRatio | 新生代中Eden/Survivor比例,默认8:1(Eden:Survivor0:Survivor1 = 8:1:1),无需频繁调整 | -XX:SurvivorRatio=8 |
-XX:PretenureSizeThreshold | 大对象直接进入老年代的阈值,避免大对象占满新生代触发频繁Minor GC | -XX:PretenureSizeThreshold=10485760(10MB) |
避坑点:
- 不要盲目调大堆内存(如32GB物理内存设
-Xmx30G)→ 会耗尽系统内存,导致本地内存(元空间/DirectBuffer)分配失败(如你之前遇到的Metaspace问题); - 微服务场景堆内存建议≤8G → 缩短GC停顿时间(G1在堆内存>16G时,停顿控制难度上升)。
2. 元空间(Metaspace):避免类加载OOM
元空间存储类元数据(替代永久代),是本地内存,需显式限制大小,避免无限制占用系统内存。
| 配置项 | 作用&优化建议 | 示例 |
|---|---|---|
-XX:MetaspaceSize | 元空间初始阈值,达到该值触发Full GC(默认21MB,建议调高减少Full GC频率) | -XX:MetaspaceSize=64M |
-XX:MaxMetaspaceSize | 元空间最大上限,必须显式设置(默认无限制,易耗尽本地内存) | -XX:MaxMetaspaceSize=256M |
-XX:CompressedClassSpaceSize | 压缩类空间大小(仅64位JVM),默认1G,动态类少的场景可调低 | -XX:CompressedClassSpaceSize=512M |
适配场景:
- 动态代理多(如MyBatis、Spring AOP)→ 元空间设128-256M;
- 插件化/热部署应用(如Tomcat多应用)→ 元空间设512M-1G,避免类加载泄漏。
3. 堆外内存(Off-Heap):避免本地内存溢出
堆外内存包括DirectBuffer、JNI内存、JVM内部结构(如线程栈),需限制大小:
| 配置项 | 作用&优化建议 | 示例 |
|---|---|---|
-XX:MaxDirectMemorySize | 限制DirectBuffer最大大小(默认等于堆内存最大值,建议显式限制) | -XX:MaxDirectMemorySize=4G |
-Xss(线程栈大小) | 每个线程的栈空间,默认1M,线程数多的场景可调低(如256K) | -Xss256K |
-XX:HeapBaseMinAddress | 压缩指针模式下,将堆内存移至32GB以上地址空间,释放低地址给本地内存(仅物理内存≥32GB时用) | -XX:HeapBaseMinAddress=0x1000000000 |
关键场景:
- 高并发网络应用(如Netty)→ 限制DirectBuffer大小,避免堆外内存耗尽;
- 线程数多(如1000+线程)→ 调低
-Xss(如256K),减少栈内存总占用。
4. 垃圾回收器:匹配业务延迟/吞吐量需求
选择合适的GC算法,减少GC停顿和内存碎片,是避免内存问题的关键:
| GC类型 | 适用场景 | 核心配置(以JDK11+为例) | 优化目标 |
|---|---|---|---|
| G1GC(默认) | 微服务、中等堆内存(4-16G) | -XX:+UseG1GC -XX:MaxGCPauseMillis=200 | 控制GC停顿≤200ms |
| ZGC | 大堆内存(16G+)、低延迟 | -XX:+UseZGC -XX:ZCollectionInterval=300 | 停顿<10ms,适配大内存场景 |
| Shenandoah | 低延迟、跨平台 | -XX:+UseShenandoahGC -XX:ShenandoahGCHeuristics=compact | 极致低停顿 |
| ParallelGC | 批处理、高吞吐量 | -XX:+UseParallelGC -XX:ParallelGCThreads=8 | 最大化吞吐量,允许长停顿 |
核心优化参数(G1GC为例):
-XX:G1HeapRegionSize:G1堆分区大小(默认根据堆内存自动调整,建议设4M/8M);-XX:InitiatingHeapOccupancyPercent=45:触发G1混合回收的堆占用阈值(默认45%,调低可提前回收老年代);-XX:G1ReservePercent=10:预留堆空间(默认10%),避免晋升失败导致OOM。
八、通用优化配置模板(分场景)
1. 微服务场景(8核16G服务器)
# 基础堆内存
-Xms8G -Xmx8G
# 新生代(G1动态调整)
-XX:+UseG1GC -XX:G1NewSizePercent=30 -XX:G1MaxNewSizePercent=50
# 元空间
-XX:MetaspaceSize=64M -XX:MaxMetaspaceSize=256M
# GC停顿目标
-XX:MaxGCPauseMillis=200
# 堆外内存
-XX:MaxDirectMemorySize=2G -Xss256K
# 内存监控(排查问题用)
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/tmp/gc.log
2. 大内存场景(16核64G服务器,如大数据/缓存应用)
-Xms32G -Xmx32G
-XX:+UseZGC
-XX:ZCollectionInterval=300
-XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=512M
-XX:MaxDirectMemorySize=8G
-XX:HeapBaseMinAddress=0x1000000000 # 堆移至32GB以上
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof
3. 轻量应用(4核8G服务器,如小型接口服务)
-Xms2G -Xmx4G
-XX:+UseG1GC
-XX:MetaspaceSize=32M -XX:MaxMetaspaceSize=128M
-Xss256K
-XX:MaxDirectMemorySize=1G
九、配套措施:避免内存问题的非配置优化
- 监控预警:
- 采集GC指标(停顿时间、频率)、堆内存/元空间使用率,超过阈值(如堆占用80%)及时告警;
- 开启内存溢出自动dump(
-XX:+HeapDumpOnOutOfMemoryError),便于事后分析。
- 代码层面:
- 避免创建大对象、无限集合(如HashMap缓存不清理);
- 关闭无用的动态代理/类加载(如Spring Boot按需加载组件);
- 及时释放DirectBuffer(通过
Cleaner或手动释放)。
- 系统层面:
- 扩容系统虚拟内存(PageFile/Swap),避免本地内存分配失败;
- 限制JVM进程的内存上限(如cgroup),避免占用过多系统资源。
十、避坑指南:常见错误配置
- 只调大堆内存,不限制元空间/堆外内存 → 导致本地内存OOM(如你之前遇到的Metaspace问题);
- 堆内存超过32GB仍启用压缩指针(未设
HeapBaseMinAddress)→ 压缩指针失效,内存占用增加; - 盲目追求低GC停顿,设置
MaxGCPauseMillis过小(如50ms)→ 导致GC频率飙升,吞吐量下降; - 不开启GC日志 → 内存问题发生后无数据可分析。
总结:JVM配置优化没有“银弹”,需先通过监控明确内存瓶颈(如堆溢出/元空间不足/GC频繁),再针对性调参,同时结合代码和系统层面优化,才能从根本上避免内存问题。


















 402
402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











