




 本文详细介绍了Zookeeper的内部运行机制,包括ZNode、ACL、Session和Watch机制,以及Zookeeper集群架构和顺序一致性。Zookeeper通过ZXID确保消息顺序,使用2PC协议保证数据一致性,并在故障恢复时进行数据同步。此外,文章还讨论了临时节点与Session的关系,以及如何理解和利用Zookeeper的顺序一致性。
本文详细介绍了Zookeeper的内部运行机制,包括ZNode、ACL、Session和Watch机制,以及Zookeeper集群架构和顺序一致性。Zookeeper通过ZXID确保消息顺序,使用2PC协议保证数据一致性,并在故障恢复时进行数据同步。此外,文章还讨论了临时节点与Session的关系,以及如何理解和利用Zookeeper的顺序一致性。
目录
前言
Zookeeper 官方说明文档:ZooKeeper Programmer's Guide
Zookeeper内部运行机制
Zookeeper的底层存储原理,有点类似于Linux中的文件系统。Zookeeper中的文件系统中的每个文件都是节点(Znode)。根据文件之间的层级关系,Zookeeper内部就会形成如下图这样一个文件树。
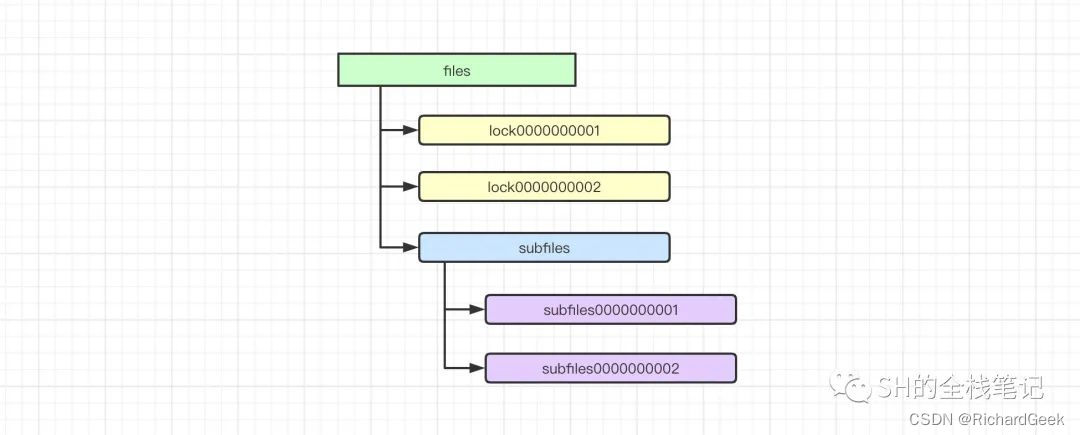
在Linux中,文件(节点)其实是分类型的,例如分为文件、目录。在Zookeeper中同理,Znode同样的有类型。在Zookeeper中,所有的节点类型如下:
-
持久节点(Persistent)
-
持久顺序节点(Persistent Sequential)
-
临时节点(Ephemeral)
-
临时顺序节点(Ephemeral Sequential)
持久节点,就和我们自己在电脑上新建一个文件一样,除非你主动删除,否则一直存在。
持久顺序节点除了继承了持久节点的特性之外,还会为其下创建的子节点保证其先后顺序,并且会自动地为节点加上10位自增序列号作为节点名,以此来保证节点名的唯一性。这一点上图中的subfiles已经给出了示例。
临时节点,其生命周期和client的连接是否活跃相关,如果client一旦断开连接,该节点(可以理解为文件)就都会被删除,并且临时节点无法创建子节点;
注:这里的断开连接其实不是我们直觉上理解的断开连接,Zookeeper有其Session机制,当某个client的Session过期之后,会将对应的client创建的节点全部删除。
Zookeeper的节点创建方式举例
创建持久节点:
create /node_name SH的全栈笔记创建持久顺序节点:
create -s /node_name SH的全栈笔记创建临时节点:
create -e /test SH的全栈笔记创建临时顺序节点:
create -e -s /node_name SH的全栈笔记ZNode
这个应该算是Zookeeper中的基础,数据存储的最小单元。在Zookeeper中,类似文件系统的存储结构,被Zookeeper抽象成了树,树中的每一个节点(Node)被叫做ZNode。ZNode中维护了一个数据结构,用于记录ZNode中数据更改的版本号以及ACL(Access Control List)的变更。
有了这些数据的版本号以及其更新的Timestamp,Zookeeper就可以验证客户端请求的缓存是否合法,并协调更新。而且,当Zookeeper的客户端执行更新或者删除操作时,都必须要带上要修改的对应数据的版本号。如果Zookeeper检测到对应的版本号不存在,则不会执行这次更新。如果合法,在ZNode中数据更新之后,其对应的版本号也会一起更新。
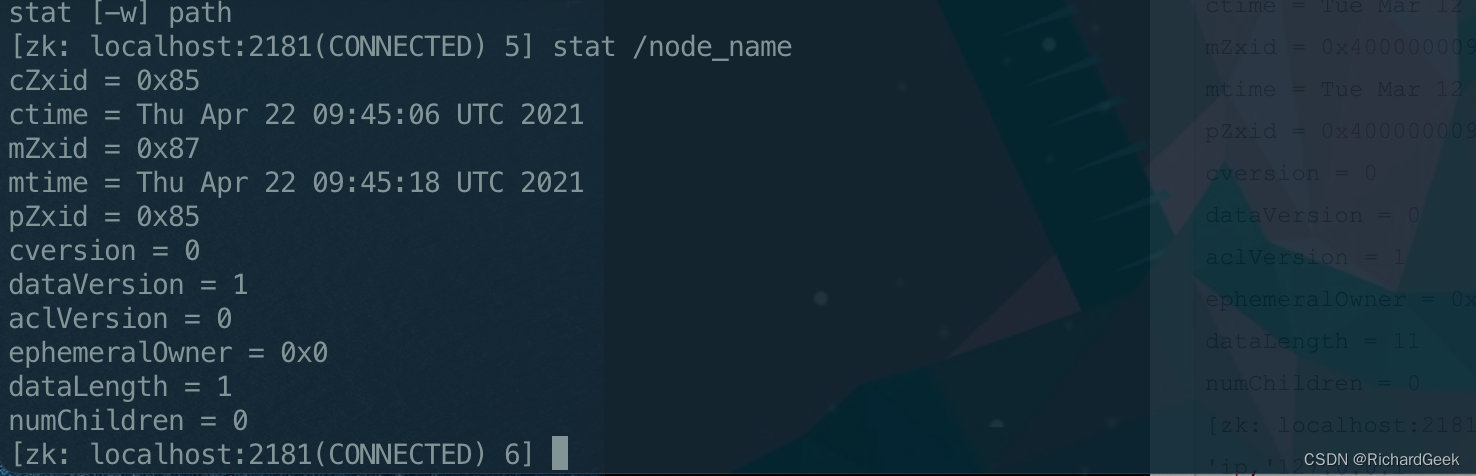
接下来我们来详细看一下这个维护版本号相关数据的数据结构,它叫Stat Structure,其字段有:
| 字段 | 释义 |
|---|---|
| czxid | 创建该节点的zxid |
| mzxid | 最后一次修改该节点的zxid |
| pzxid | 最后一次修改该节点的子节点的zxid |
| ctime | 从当前epoch开始到该节点被创建,所间隔的毫秒 |
| mtime | 从当前epoch开始到该节点最后一次被编辑,所间隔的毫秒 |
| version | 当前节点的改动次数(也就是版本号) |
| cversion | 当前节点的子节点的改动次数 |
| aversion | 当前节点的ACL改动次数 |
| ephemeralOwner | 当前临时节点owner的SessionID(如果不是临时节点则为空) |
| dataLength | 当前节点的数据的长度 |
| numChildren | 当前节点的子节点数量 |
举个例子,通过stat命令,我们可以查看某个ZNode中Stat Structure具体的值。
ACL
ACL(Access Control List)用于控制ZNode的相关权限,其权限控制和Linux中的类似。Linux中权限种类分为了三种,分别是读、写、执行,分别对应的字母是r、w、x。其权限粒度也分为三种,分别是拥有者权限、群组权限、其他组权限,举个例子:
drwxr-xr-x 3 USERNAME GROUP 1.0K 3 15 18:19 dir_name什么叫粒度?粒度是对权限所作用的对象的分类,把上面三种粒度换个说法描述就是对用户(Owner)、用户所属的组(Group)、其他组(Other)的权限划分,这应该算是一种权限控制的标准了,典型的三段式。
Zookeeper中虽然也是三段式,但是两者对粒度的划分存在区别。Zookeeper中的三段式为Scheme、ID、Permissions,含义分别为权限机制、允许访问的用户和具体的权限。
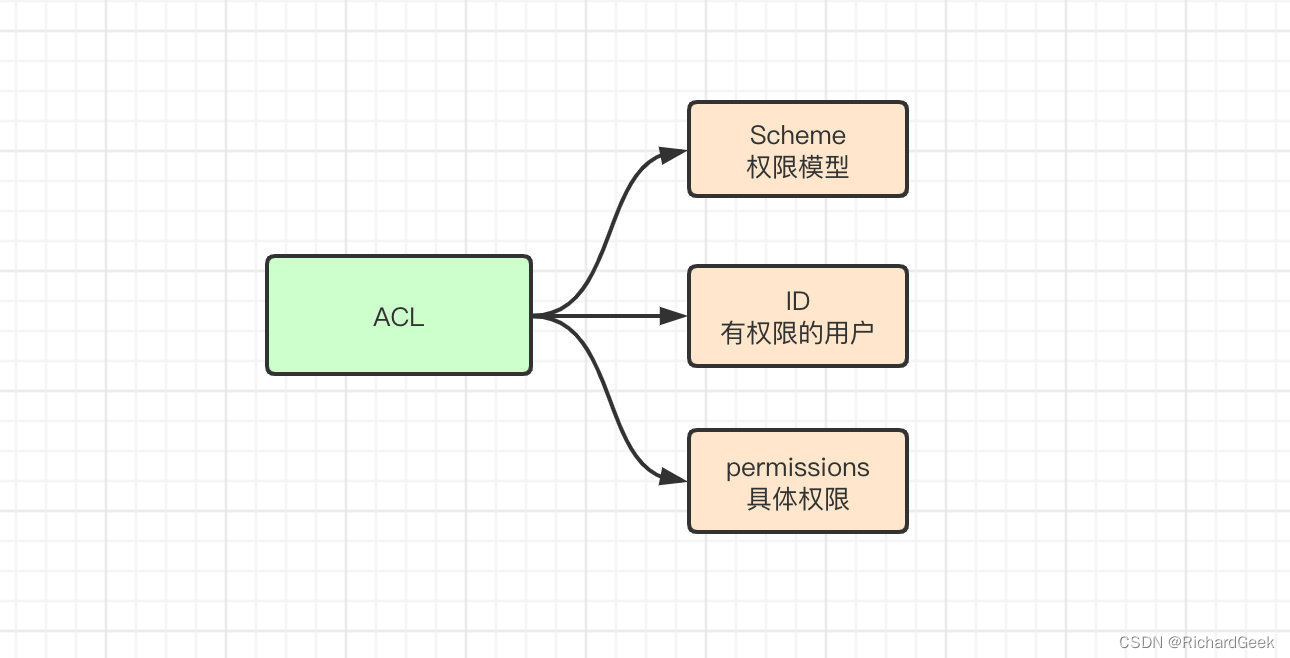
Scheme代表了一种权限模式,有以下5种类型:
- world 在此中Scheme下,
ID只能是anyone,代表所有人都可以访问 - auth 代表已经通过了认证的用户
- digest 使用用户名+密码来做校验。
- ip 只允许某些特定的IP访问ZNode
- X509 通过客户端的证书进行认证
同时权限种类也有五种:
- CREATE 创建节点
- READ 获取节点或列出其子节点
- WRITE 能设置节点的数据
- DELETE 能够删除子节点
- ADMIN 能够设置权限
同Linux中一样,这个权限也有缩写,举个例子:
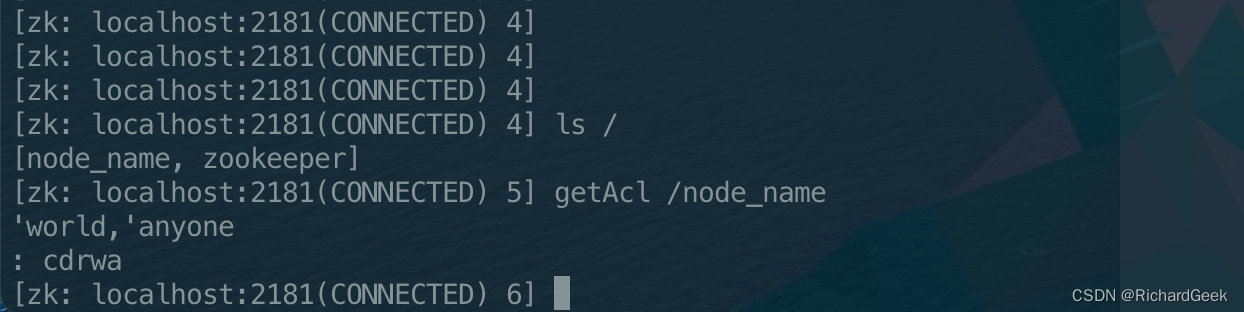
getAcl方法用户查看对应的ZNode的权限,如图,我们可以输出的结果呈三段式。分别是:
- scheme 使用了world
- id 值为
anyone,代表所有用户都有权限 - permissions 其具体的权限为cdrwa,分别是CREATE、DELETE、READ、WRITE和ADMIN的缩写
Session机制
我们知道,Zookeeper中有4种类型的节点,分别是持久节点、持久顺序节点、临时节点和临时顺序节点。
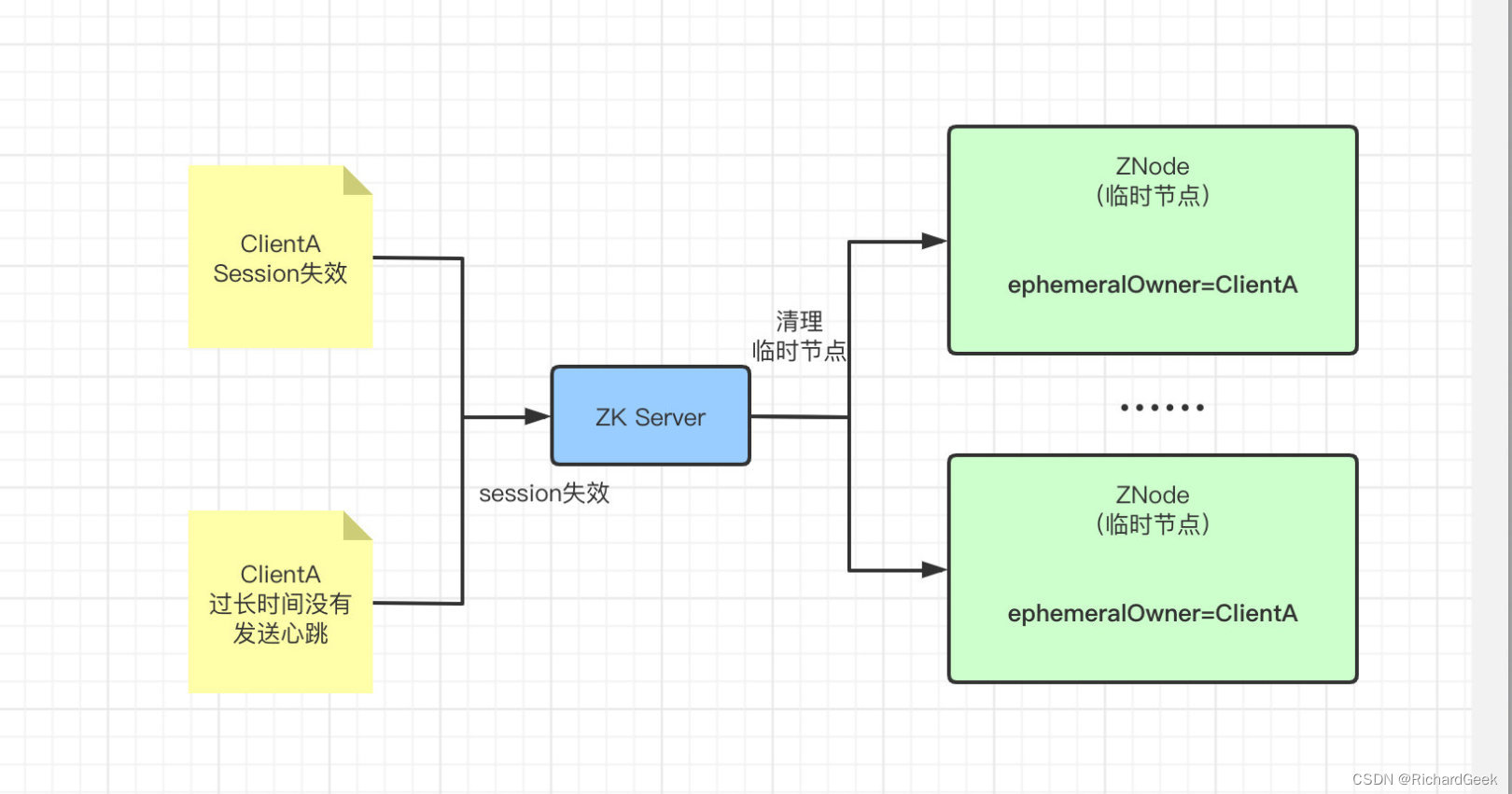
客户端如果创建了临时节点,并在之后断开了连接,那么所有的临时节点就都会被删除。实际上断开连接的说话不是很精确,应该是说客户端建立连接时的Session过期之后,其创建的所有临时节点就会被全部删除。
那么Zookeeper是怎么知道哪些临时节点是由当前客户端创建的呢?
答案是Stat Structure中的ephemeralOwner(临时节点的Owner)字段
上面说过,如果当前是临时顺序节点,那么ephemeralOwner则存储了创建该节点的Owner的SessionID,有了SessionID,自然就能和对应的客户端匹配上,当Session失效之后,才能将该客户端创建的所有临时节点全部删除。
对应的服务在创建连接的时候,必须要提供一个带有所有服务器、端口的字符串,单个之间逗号相隔,举个例子。
127.0.0.1:3000:2181,127.0.0.1:2888,127.0.0.1:3888Zookeeper的客户端收到这个字符串之后,会从中随机选一个服务、端口来建立连接。如果连接在之后断开,客户端会从字符串中选择下一个服务器,继续尝试连接,直到连接成功。
除了这种最基本的IP+端口,在Zookeeper的3.2.0之后的版本中还支持连接串中带上路径,举个例子。
127.0.0.1:3000:2181,127.0.0.1:2888,127.0.0.1:3888/app/a 这样一来,/app/a就会被当成当前服务的根目录,在其下创建的所有的节点路经都会带上前缀/app/a。举个例子,我创建了一个节点/node_name,那其完整的路径就会为/app/a/node_name。这个特性特别适用于多租户的环境,对于每个租户来说,都认为自己是最顶层的根目录/。
当Zookeeper的客户端和服务器都建立了连接之后,客户端会拿到一个64位的SessionID和密码。这个密码是干什么用的呢?我们知道Zookeeper可以部署多个实例,如果客户端断开了连接又和另外的Zookeeper服务器建立了连接,那么在建立连接使就会带上这个密码。该密码是Zookeeper的一种安全措施,所有的Zookeeper节点都可以对其进行验证。这样一来,即使连接到了其他Zookeeper节点,Session同样有效。
Session过期有两种情况,分别是:
- 过了指定的失效时间
- 指定时间内客户端没有发送心跳
对于第一种情况,过期时间会在Zookeeper客户端建立连接的时候传给服务器,这个过期时间的范围目前只能在2倍tickTime和20倍tickTime之间。
ticktime是Zookeeper服务器的配置项,用于指定客户端向服务器发送心跳的间隔,其默认值为tickTime=2000,单位为毫秒。
而这套Session的过期逻辑由Zookeeper的服务器维护,一旦Session过期,服务器会立即删除由Client创建的所有临时节点,然后通知所有正在监听这些节点的客户端相关变更。
对于第二种情况,Zookeeper中的心跳是通过PING请求来实现的,每隔一段时间,客户端都会发送PING请求到服务器,这就是心跳的本质。心跳使服务器感知到客户端还活着,同样的让客户端也感知到和服务器的连接仍然是有效的,这个间隔就是tickTime,默认为2秒。
Watch机制
了解完ZNode和Session,我们终于可以来继续下一个关键功能Watch了,在上面的内容中也不止一次的提到监听(Watch)这个词。首先用一句话来概括其作用。
给某个节点注册监听器,该节点一旦发生变更(例如更新或者删除),监听者就会收到一个Watch Event
和ZNode中有多种类型一样,Watch也有多种类型,分别是一次性Watch和永久性Watch。
- 一次性Watch 在被触发之后,该Watch就会移除
- 永久性Watch 在被触发之后,仍然保留,可以继续监听ZNode上的变更,是Zookeeper 3.6.0版本新增的功能
一次性的Watch可以在调用getData()、getChildren()和exists()等方法时在参数中进行设置,永久性的Watch则需要调用addWatch()来实现。
并且一次性的Watch会存在问题,因为在Watch触发的事件到达客户端、再到客户端设立新的Watch,是有一个时间间隔的。而如果在这个时间间隔中发生的变更,客户端则无法感知。
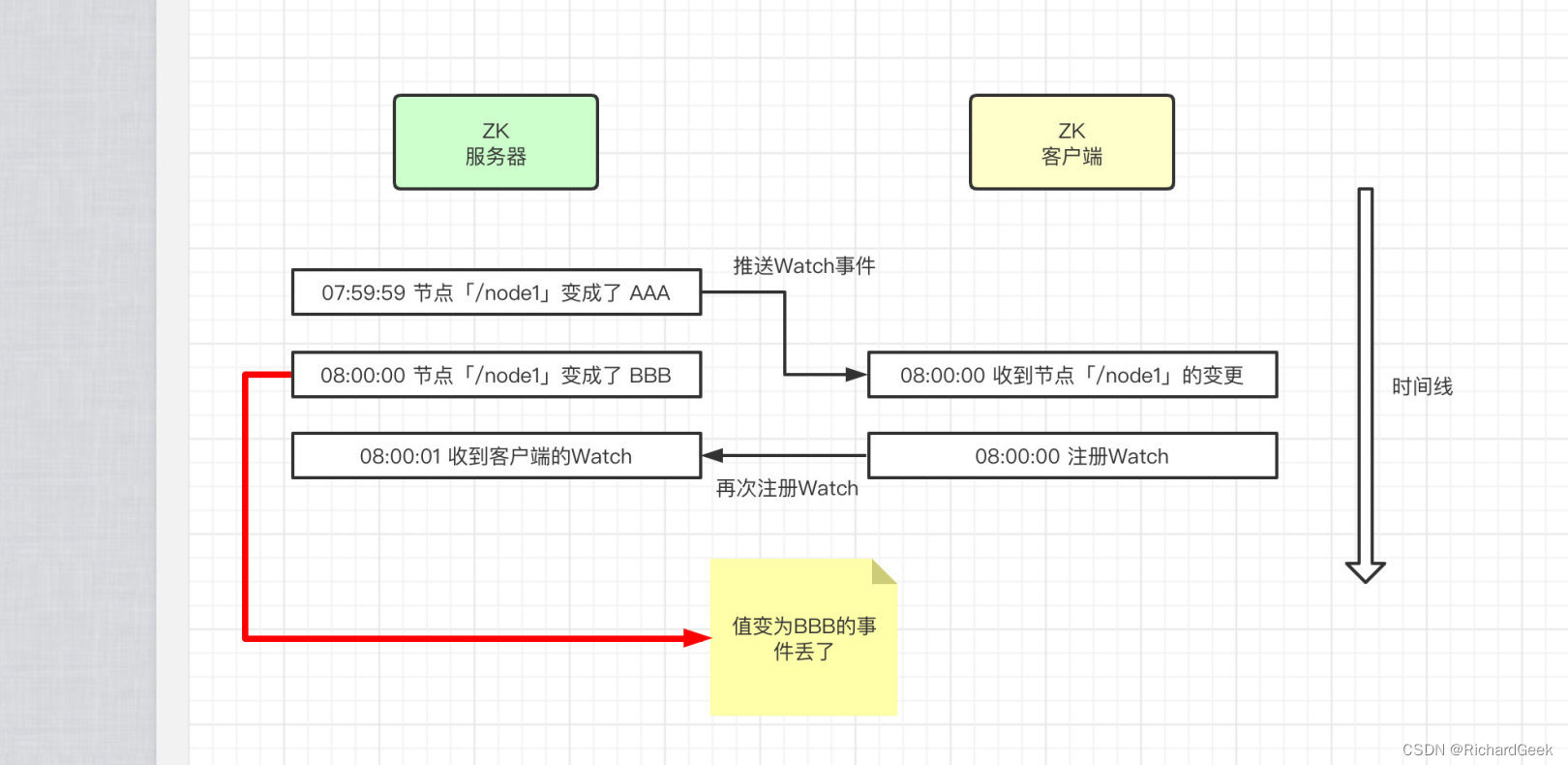
Zookeeper集群架构
ZAB协议
把前面的都铺垫好之后就可以来从整体架构的角度再深入了解Zookeeper。Zookeeper为了保证其高可用,采用的基于主从的读写分离架构。
我们知道在类似的Redis主从架构中,节点之间是采用的Gossip协议来进行通信的,那么在Zookeeper中通信协议是什么?
答案是ZAB(Zookeeper Atomic Broadcast)协议。
ZAB协议是一种支持崩溃恢复的的原子广播协议,用于在Zookeeper之间传递消息,使所有的节点都保持同步。ZAB同时具有高性能、高可用的、容易上手、利于维护的特点,同时支持自动的故障恢复。
ZAB协议将Zookeeper集群中的节点划分成了三个角色,分别是Leader、Follower和Observer,如下图:
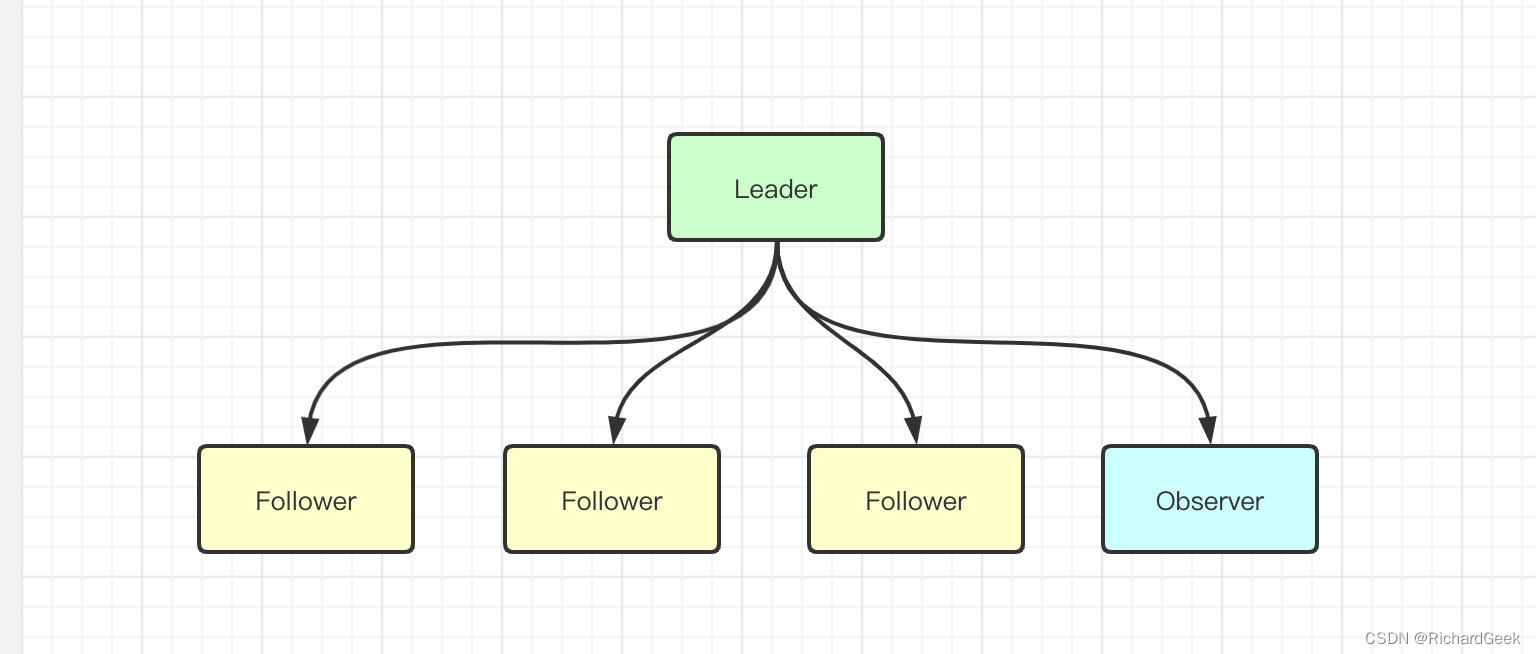
通常的主从架构中存在两种角色,分别是Leader、Follower(或者是Master、Slave),但Zookeeper中多了一个Observer。
那问题来了,Observer和Follower的区别是啥呢?
本质上来说两者的功能是一样的, 都为Zookeeper提供了横向扩展的能力,使其能够扛住更多的并发。但区别在于Leader的选举过程中,Observer不参与投票选举。
顺序一致性【非常重要的一个知识点!!!!!!】
上文提到了Zookeeper集群中是读写分离的,只有Leader节点能处理写请求,如果Follower节点接收到了写请求,会将该请求转发给Leader节点处理,Follower节点自身是不会处理写请求的。
Leader节点接收到消息之后,会按照请求的严格顺序一一的进行处理。这是Zookeeper的一大特点,它会保证消息的顺序一致性。
举个例子,如果消息A比消息B先到,那么在所有的Zookeeper节点中,消息A都会先于消息B到达,Zookeeper会保证消息的全局顺序。
理解zookeeper的顺序一致性
ZooKeeper Programmer’s Guide提到:
Sometimes developers mistakenly assume one other guarantee that ZooKeeper does not in fact make. This is:
Simultaneously Conistent Cross-Client Views
ZooKeeper does not guarantee that at every instance in time, two different clients will have identical views of ZooKeeper data. Due to factors like network delays, one client may perform an update before another client gets notified of the change. Consider the scenario of two clients, A and B. If client A sets the value of a znode /a from 0 to 1, then tells client B to read /a, client B may read the old value of 0, depending on which server it is connected to. If it is important that Client A and Client B read the same value, Client B should should call the sync() method from the ZooKeeper API method before it performs its read.
So, ZooKeeper by itself doesn’t guarantee that changes occur synchronously across all servers, but ZooKeeper primitives can be used to construct higher level functions that provide useful client synchronization.
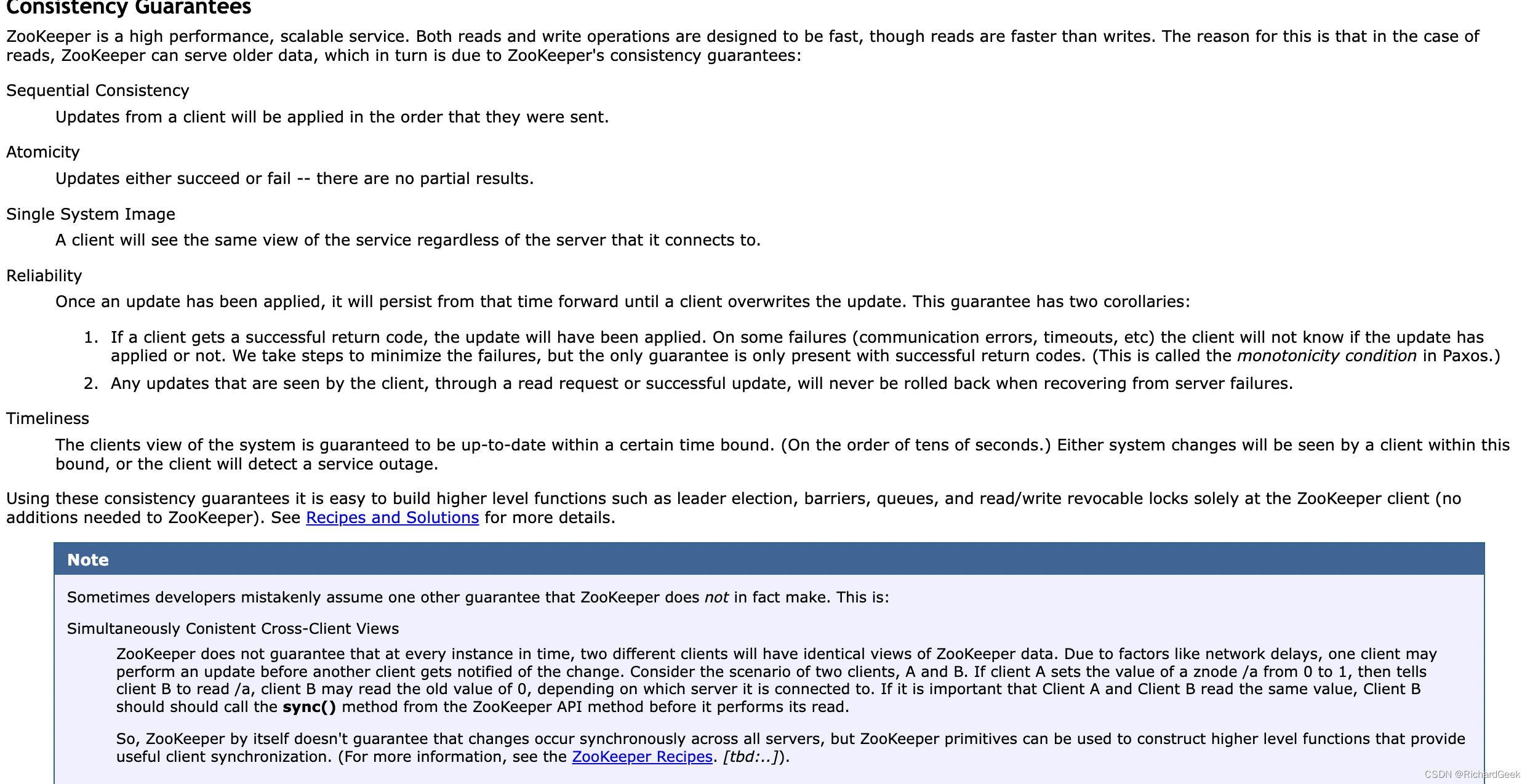
就是说zookeeper并不保证每次客户端从其一个server读到的值是最新的,它只保证这个server中的值是顺序更新的,如果其他server节点想要读取最新的值,必须在get之前调用sync()(zoo_async)
zxid
那Zookeeper是如何保证消息的顺序?答案是通过
zxid。
可以简单的把zxid理解成Zookeeper中消息的唯一ID,节点之间会通过发送Proposal(事务提议)来进行通信、数据同步,proposal中就会带上zxid和具体的数据(Message)。而zxid由两部分组成:
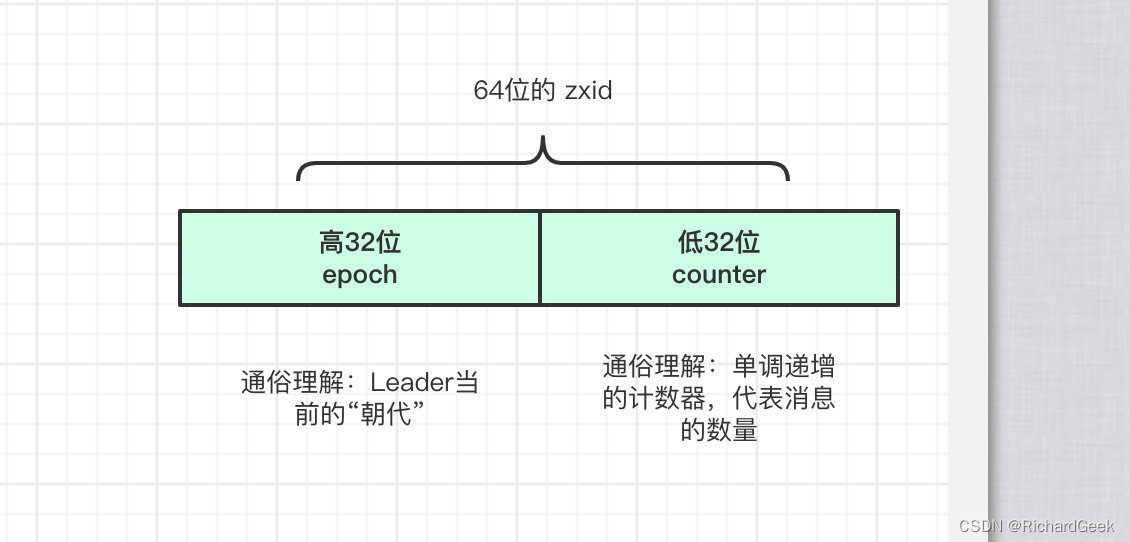
- epoch 可以理解成朝代,或者说Leader迭代的版本,每个Leader的epoch都不一样
- counter 计数器,来一条消息就会自增
这也是唯一zxid生成算法的底层实现,由于每个Leader所使用的epoch都是唯一的,而不同的消息在相同的epoch中,counter的值是不同的,这样一来所有的proposal在Zookeeper集群中都有唯一的zxid。
恢复模式
正常运行的Zookeeper集群会处于广播模式。相反,如果超过半数的节点宕机,就会进入恢复模式。
什么是恢复模式?
在Zookeeper集群中,存在两种模式,分别是:
- 恢复模式
- 广播模式
当Zookeeper集群故障时会进入恢复模式,也叫做Leader Activation,顾名思义就是要在此阶段选举出Leader。节点之间会生成zxid和Proposal,然后相互投票。投票是要有原则的,主要有两条:
- 选举出来的Leader的zxid一定要是所有的Follower中最大的
- 并且已有超过半数的Follower返回了ACK,表示认可选举出来的Leader
如果在选举的过程中发生异常,Zookeeper会直接进行新一轮的选举。如果一切顺利,Leader就会被成功选举出来,但是此时集群还不能正常对外提供服务,因为新的Leader和Follower之间还没有进行关键的数据同步。
此后,Leader会等待其余的Follower来连接,然后通过Proposal向所有的Follower发送其缺失的数据。
至于怎么知道缺失哪些数据,Proposal本身是要记录日志,通过Proposal中的zxid的低32位的Counter中的值,就可以做一个Diff。
当然这里有个优化,如果缺失的数据太多,那么一条一条的发送Proposal效率太低。所以如果Leader发现缺失的数据过多就会将当前的数据打个快照,直接打包发送给Follower。
新选举出来的Leader的Epoch,会在原来的值上+1,并且将Counter重置为0。
到这你是不是以为就完了?实际上到这还是无法正常提供服务
数据同步完成之后,Leader会发送一个NEW_LEADER的Proposal给Follower,当且仅当该Proposal被过半的Follower返回Ack之后,Leader才会Commit该NEW_LEADER Proposal,集群才能正常的进行工作。
至此,恢复模式结束,集群进入广播模式。
广播模式
在广播模式下,Leader接收到消息之后,会向其他所有Follower发送Proposal(事务提议),Follower接收到Proposal之后会返回ACK给Leader。当Leader收到了quorums个ACK之后,当前Proposal就会提交,被应用到节点的内存中去。
quorum个是多少呢?
Zookeeper官方建议每2个Zookeeper节点中,至少有一个需要返回ACK才行,假设有N个Zookeeper节点,那计算公式应该是n/2 + 1。
这样可能不是很直观,用大白话来说就是,超过半数的Follower返回了ACK,该Proposal就能够提交,并且应用至内存中的ZNode。
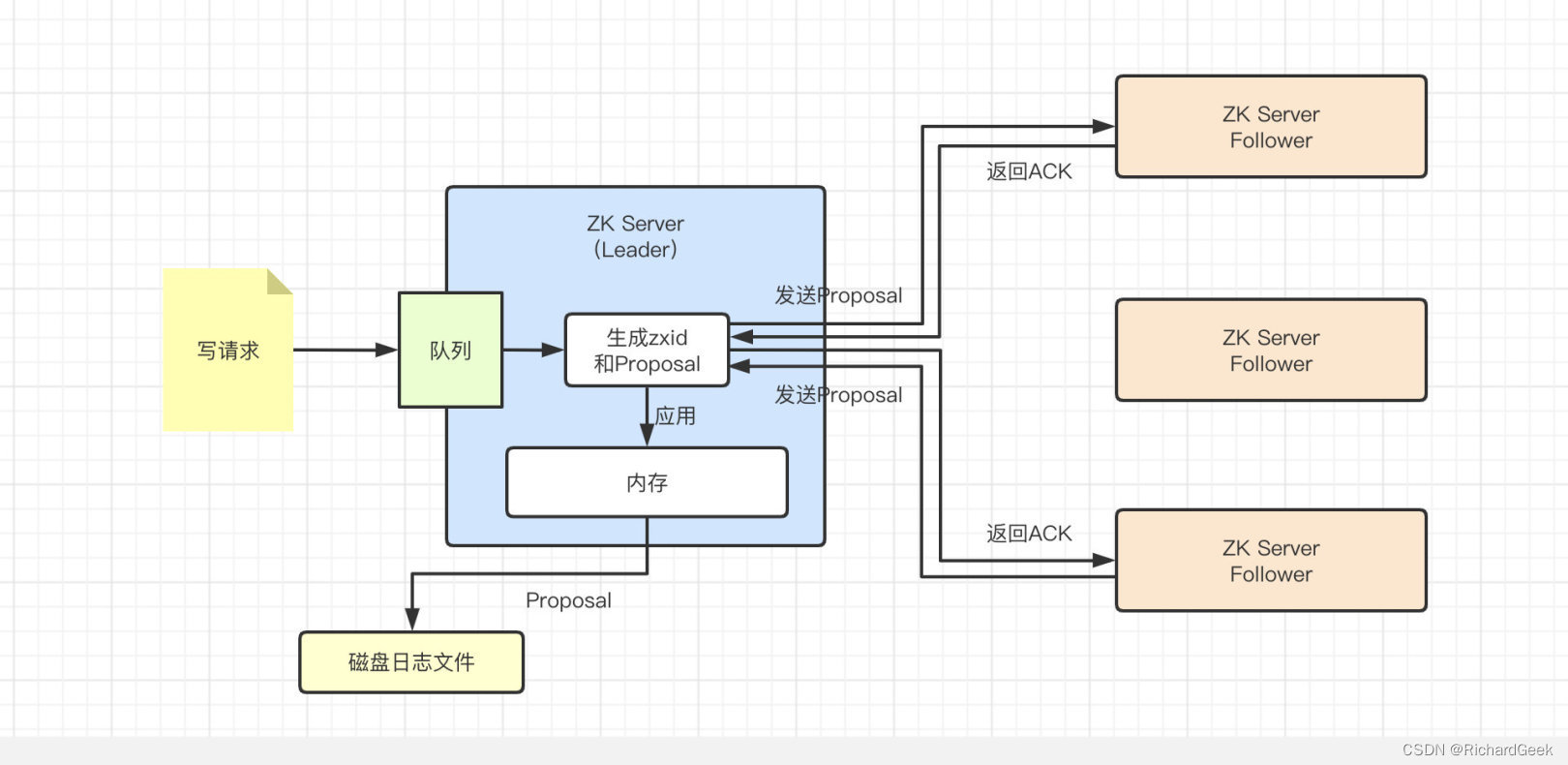
Zookeeper使用2PC来保证节点之间的数据一致性(如上图),但是由于Leader需要跟所有的Follower交互,这样一来通信的开销会变得较大,Zookeeper的性能就会下降。所以为了提升Zookeeper的性能,才从所有的Follower节点返回ACK变成了过半的Follower返回ACK即可。

















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









