




作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
1.【代码】Machine Learning on Sequential Data Using a Recurrent Weighted Average
简介:
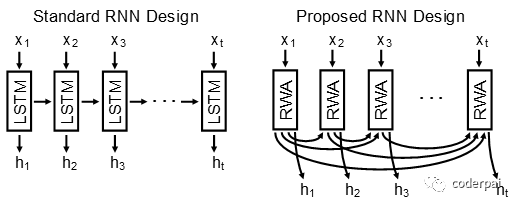
This repository holds the code to a new kind of RNN model for processing sequential data. The model computes a recurrent weighted average (RWA) over every previous processing step. With this approach, the model can form direct connections anywhere along a sequence. This stands in contrast to traditional RNN architectures that only use the previous processing step. A detailed description of the RWA model has been published in a manuscript at https://arxiv.org/pdf/1703.01253.pdf.
原文链接:https://github.com/jostmey/rwa
2.【博客】How to use pre-trained word vectors from Facebook’s fastText
简介:

fastText is a library for efficient learning of word representations and sentence classification.
In plain English, using fastText you can make your own word embeddings using Skipgram, word2vec or CBOW (Continuous Bag of Words) and use it for text classification.
3.【代码】lda2vec-tf
简介:
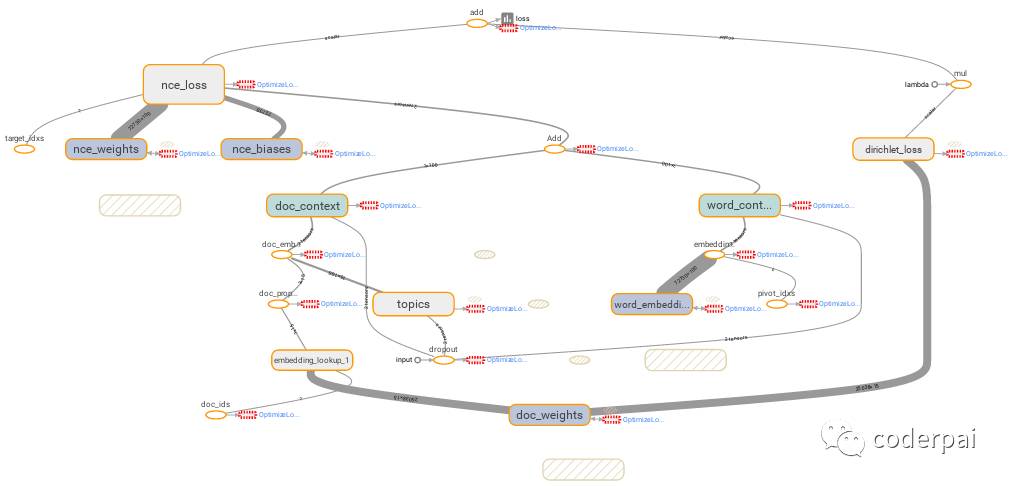
TensorFlow implementation of Christopher Moody’s lda2vec, a hybrid of Latent Dirichlet Allocation & word2vec
The lda2vec model simultaneously learns embeddings (continuous dense vector representations) for:
words (based on word and document context),
topics (in the same latent word space), and
documents (as sparse distributions over topics).
原文链接:https://github.com/meereeum/lda2vec-tf
4.【博客】One by One [ 1 x 1 ] Convolution - counter-intuitively useful
简介:
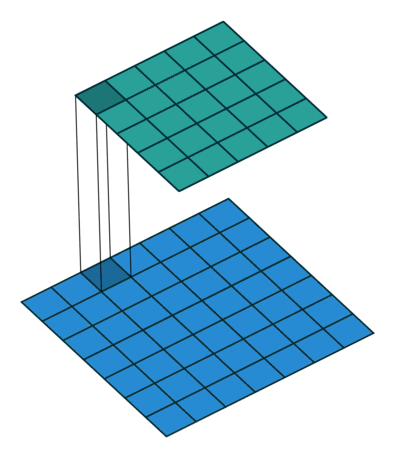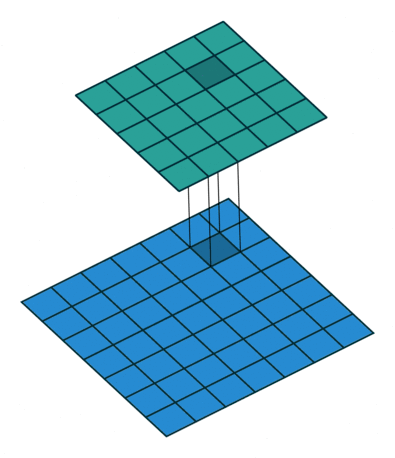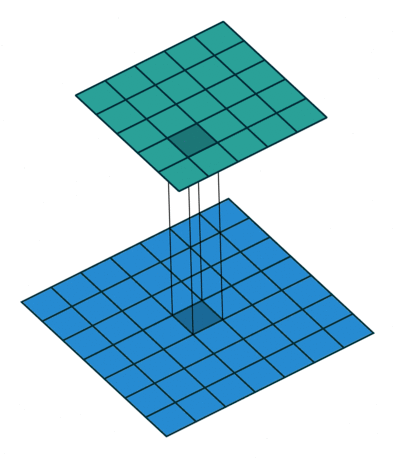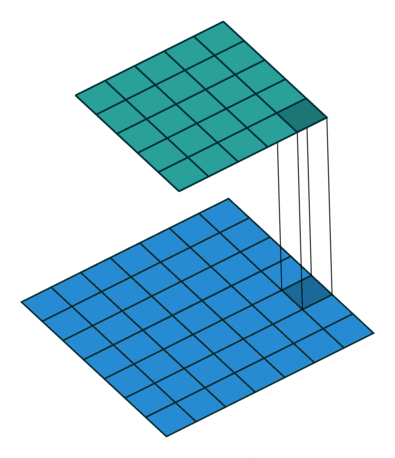
Most simplistic explanation would be that 1x1 convolution leads to dimension reductionality. For example, an image of 200 x 200 with 50 features on convolution with 20 filters of 1x1 would result in size of 200 x 200 x 20. But then again, is this is the best way to do dimensionality reduction in the convoluational neural network? What about the efficacy vs efficiency?
原文链接:http://iamaaditya.github.io/2016/03/one-by-one-convolution/
5.【Jupyter 教程】Reproducible Data Analysis in Jupyter
简介:
Jupyter notebooks provide a useful environment for interactive exploration of data. A common question I get, though, is how you can progress from this nonlinear, interactive, trial-and-error style of exploration to a more linear and reproducible analysis based on organized, packaged, and tested code. This series of videos presents a case study in how I personally approach reproducible data analysis within the Jupyter notebook.
原文链接:http://jakevdp.github.io/blog/2017/03/03/reproducible-data-analysis-in-jupyter/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









