




 CodeFuse-VLM是一个开源的多模态多任务微调框架,支持多种视觉和语言模型。CodeFuse-VLM-14B基于Qwen-VL和Qwen-14B,性能超越LLAVA-1.5和Qwen-VL,尤其在MMBenchmark上展示了出色的表现。该框架通过预训练和指令微调解决多任务问题,提升了开发效率。
CodeFuse-VLM是一个开源的多模态多任务微调框架,支持多种视觉和语言模型。CodeFuse-VLM-14B基于Qwen-VL和Qwen-14B,性能超越LLAVA-1.5和Qwen-VL,尤其在MMBenchmark上展示了出色的表现。该框架通过预训练和指令微调解决多任务问题,提升了开发效率。

CodeFuse-MFT-VLM 项目地址:
https://github.com/codefuse-ai/CodeFuse-MFT-VLM
CodeFuse-VLM-14B 模型地址:
CodeFuse-VLM-14B
CodeFuse-VLM框架简介
随着huggingface开源社区的不断更新,会有更多的vision encoder 和 LLM 底座发布,这些vision encoder 和 LLM底座都有各自的强项,例如 code-llama 适合生成代码类任务,但是不适合生成中文类的任务,因此用户常常需要根据vision encoder和LLM的特长来搭建自己的多模态大语言模型。针对多模态大语言模型种类繁多的落地场景,我们搭建了CodeFuse-VLM 框架,支持多种视觉模型和语言大模型,使得MFT-VLM可以适应不同种类的任务。
CodeFuse-VLM 支持多种视觉达模型:CLIP,CLIP-336px,Chinese Clip,Chinese Clip-336px,Qwen Clip;多种语言达模型:Vicuna-7B,Vicunam-13B,LLAMA-2-7B,Qwen-7B,Qwen-14B。用户可以根据自己的需求,通过配置文件的方式搭配VL-MFTCoder中不同的Vision Encoder 和 LLM,使用同一套框架去适配的不同的模型,大大提高了开发效率
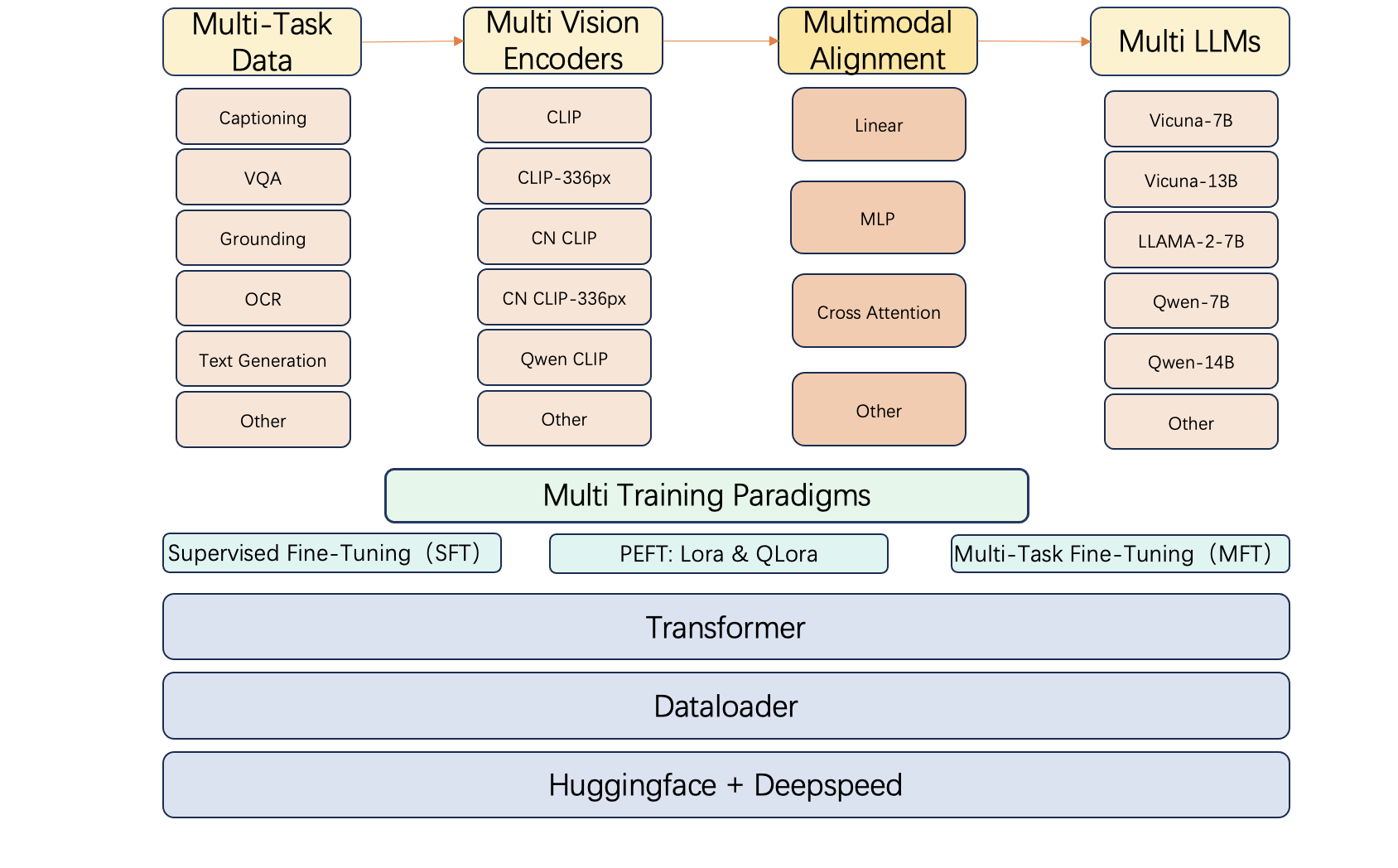
我们在2024年1月开源了多模态多任务微调框架——CodeFuse-VLM。在CodeFuse多任务微调的基础上,CodeFuse-VLM可以实现在多个模态,多个任务上同时并行地进行微调。通过结合多种损失函数,我们有效地解决了多任务学习中常见的任务间数据量不平衡、难易不一和收敛速度不一致等挑战。此外,CodeFuse-VLM框架具备高效训练特征,支持高效的PEFT微调,能有效提升微调训练速度并降低对资源的需求。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1518
1518




 到【灌水乐园】发言
到【灌水乐园】发言







