




 CodeFuse发布ToolLearning-Eval,首个中文工具学习评测基准,针对大模型在工具选择、调用及执行结果总结中的能力。评测数据包括清洗的开源数据、翻译后的英文数据和自建的训练集,旨在推动工具学习领域模型的发展和评估。
CodeFuse发布ToolLearning-Eval,首个中文工具学习评测基准,针对大模型在工具选择、调用及执行结果总结中的能力。评测数据包括清洗的开源数据、翻译后的英文数据和自建的训练集,旨在推动工具学习领域模型的发展和评估。

1. 背景
随着ChatGPT等通用大模型的出现,它们可以生成令人惊叹的自然语言,使得机器能够更好地理解和回应人类的需求,但在特定领域的任务上仅靠通用问答是无法满足日常工作需要。随着OpenAI推出了Function Call功能,工具学习能力越来越作为开源模型的标配,目前业界较有影响力的是ToolBench的英文数据集。但是中文数据集的稀缺,使得我们很难判断各个模型在中文型工具上Function Call的能力差异。
为弥补这一不足,CodeFuse发布了首个面向ToolLearning领域的中文评测基准ToolLearning-Eval,以帮助开发者跟踪ToolLearning领域大模型的进展,并了解各个ToolLearning领域大模型的优势与不足。ToolLearning-Eval按照Function Call流程进行划分,包含工具选择、工具调用、工具执行结果总结这三个过程,方便通用模型可以对各个过程进行评测分析。
目前,我们已发布了第一期的评测榜单,首批评测大模型包含CodeFuse、Qwen、Baichuan、Internlm、CodeLLaMa等开源大语言模型;我们欢迎相关从业者一起来共建ToolLearning Eval项目,持续丰富ToolLearning领域评测题目或大模型,我们也会定期更新评测集和评测榜单。
ModelScope 地址:devopseval-exam
2. 评测数据
2.1. 数据来源
ToolLearning-Eval最终生成的样本格式都为Function Call标准格式,采用此类格式的原因是与业界数据统一,不但能够提高样本收集效率,也方便进行其它自动化评测。经过统计,该项目的数据来源可以分为3类:
- 开源数据:对开源的ToolBench原始英文数据进行清洗;
- 英译中:选取高质量的ToolBench数据,并翻译为中文;
- 大模型生成:采用Self-Instruct方法构建了中文 Function Call 训练数据&评测集;
我们希望越来越多的团队能参与到中文的functioncall数据构建,共同优化模型调用工具的能力。我们也会不断地强化这部分开源的数据集。
2.2. 数据类别
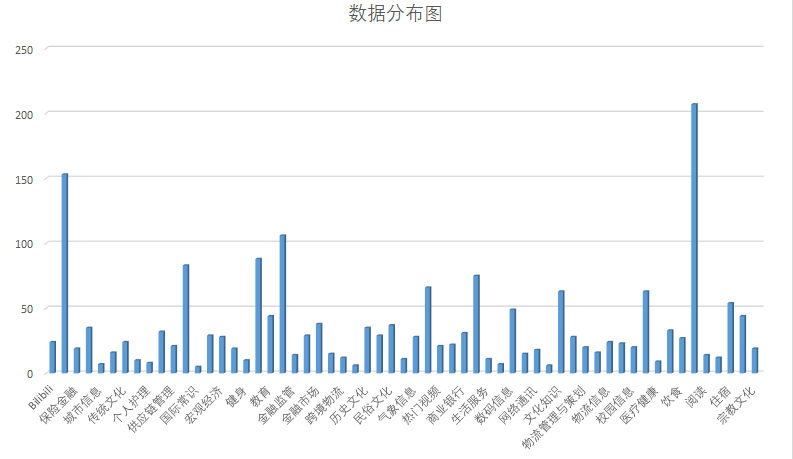
ToolLearning-Eval里面包含了两份评测集,fcdata-zh-luban和fcdata-zh-codefuse。里面总共包含 239 种工具类别,涵盖了59个领域,包含了1509 条评测数据。ToolLearning-Eval的具体数据分布可见下图
2.3. 数据样例
在数据上我们完全兼容了 OpenAI Function Calling,具体格式如下:
Function Call的数据格式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









