



如果一款电商 AI 助手,却算不清跨境税费、看不懂最新促销政策、选不出潜力爆品……这样的 AI,你敢用在生意里吗?
这正是当前多数 AI Agent 面临的困境:在实验室里“样样都会”,一到真实商业场景就“频频失误”。
而电商,恰好是检验智能体综合能力的理想试炼场。用户需求千差万别,市场规则瞬息万变,背后还嵌套着政策、财务、运营、营销等多维专业知识。一个真正能用的电商 Agent,必须同时懂合规、会算账、能运营、有洞察。
为填补这一空白,通义实验室联合 SKYLENAGE 提出了全新的 EcomBench 基准,用于全面衡量智能体在电商环境下的实际能力。
EcomBench 最大的特色在于扎根真实世界数据。它构建于全球主流电商平台(如亚马逊)上真实的用户提问和业务请求之上,涵盖政策咨询、成本估算、商品选择、经营决策等多种类型。这意味着,每一道评测任务都源自现实场景,真实反映用户的实际需求。
当然,真实数据并非照搬即用。研究团队搭建了严谨的“人类参与”数据引擎,对原始数据进行了精炼和把关。
- 首先,借助大模型从海量用户提问中筛选出有明确答案、具代表性的问题,剔除主观开放或无解的请求;
- 接着,由经验丰富的电商专家手动润色改写,确保问题表述清晰、背景完整、目标明确;
- 最后,每个问题至少由三位专家独立标注答案并交叉验证,剔除答案不一致的题目,保障答案的准确可靠。
这样层层把关的人机结合流程,使 EcomBench 的问题既保持真实语境,又具有清晰严谨的评测标准。
值得一提的是,为保持基准的时效性与真实性,EcomBench 采用季度更新机制。每三个月,题库都会迭代一次,及时纳入最新的政策法规、市场动态和业务热点。
这种滚动更新不仅能反映行业前沿,还能有效防止模型靠“背题”或记忆训练数据刷分,确保评测始终聚焦于真实解决问题的能力,而非数据记忆。
EcomBench 的设计强调评测的全面性,共收录七大类典型电商任务,几乎囊括从业者日常可能遇到的所有问题:
- 政策合规咨询(PolicyConsulting):涉及平台规则、资质提交、税务登记等合规性问题。这类任务关注电商运营中的合规需求,比如询问平台规定、注册资质流程或税务要求等。
- 成本与定价分析(Cost and Pricing):涵盖订单利润分析、报价制定、市场行情下调价策略。此类任务需要 Agent 帮忙算账,如估算盈利、制定报价,或者根据市场变化调整定价方案。
- 履约执行(FulfillmentExecution):包括发货安排、退换货流程、物流线路优化。比如让智能体规划最优配送方案或指导退货操作。
- 营销策略(MarketingStrategy):涉及促销活动策划、广告优化、拉新涨粉计划。要求Agent具有市场洞察力,能设计推广方案、优化广告投放等。
- 智能选品(Intelligent Product Selection):聚焦利用趋势信号和基础数据洞察,识别具有较好销售潜力的产品或品类,并进行需求预测与选品决策。
- 商机发现(OpportunityDiscovery):侧重根据行业动态与数据发现新兴市场趋势、产品蓝海或其他商业机会。
- 库存管理(InventoryControl):处理安全库存设定、补货规划、清仓决策等库存相关任务,目标是在保障库存可用性的同时降低积压和过库存风险。
这七大任务横跨政策、财务、运营、营销四大维度,确保模型无法靠“偏科”拿高分,真正做到对 Agent 能力的全面体检。
EcomBench 不仅任务多元,还为每道题设定了三档难度等级:
- 一级难度(约占20%):考查基本电商常识和简单工具使用。例如,“某类商品是否需要CCC认证?”
- 二级难度(约占30%):需多步推理。例如,先查平台政策,再计算税费,最后给出合规建议。
- 三级难度(约占50%):最具挑战性,要求跨领域整合、深度检索与长链推理。
为确保三级题“货真价实”地难,研究团队采用了一种巧妙的筛选方法:让一个已配备高级电商工具(如价格查询、趋势分析)尝试解题。只有那些连这个“装备精良”的模型都需要多步操作才能解决的问题,才被划入三级。
这种基于“工具能力层级”的筛选,有效保证了高难度任务的含金量,足以挑战当前最先进的 Agent。
通过难度分级,EcomBench 能清晰刻画模型的能力边界——是基础概念不过关?还是复杂链式推理会“卡壳”?一测便知。

EcomBench 的题目,往往就是电商从业者每天面对的真实难题。例如,一道典型三级题要求计算跨境电商综合税费:
“
一家中国卖家向美国出售某电子产品,需考虑标准关税(如25%)、对中国产品的额外加征关税、商品货值及免税额度等因素,最终计算应缴总税费。
这样的问题对于Agent来说,并非简单地查一个税率即可,需要先理解贸易政策,再逐步计算各项费用,最终汇总出准确的税费。这考验了模型对国际贸易规则的掌握程度,以及多步骤数学计算的可靠性。
再比如,产品合规类问题:
“
根据 DOE Level VI 能效标准,某电子设备在空载状态下的最大允许功耗是多少瓦?
回答这类问题,模型不仅要知道相关法规标准的技术细节(如DOE Level VI能效标准的具体要求),还得根据设备参数进行单位换算或简单推导,最后给出一个精确值。这需要专业知识与数理推理的结合,难度可想而知。
由此可见,EcomBench 的任务远非简单知识检索,而是对 Agent 信息整合、逻辑推理、规则应用与决策连贯性的综合考验。正如研究报告所强调的,EcomBench 通过这样的多维度任务设计,全面评估 Agent 在真实电商环境中综合运用工具、深度推理和专业判断的能力。对当前的 AI 模型来说,这些任务无疑构成了一套高难度的“模拟实战”考卷,能够暴露出模型在复杂场景下的短板与局限。

面对如此严苛的 EcomBench,对当下先进的 Agent 来说有多大挑战?研究团队对十余个主流 Agent 进行了评测。结果显示,这些模型在 EcomBench 上没有一个能轻松通关,反而表现出显著的参差。
- 最高整体准确率仅约65%;
- 大多数模型得分在 40%–55% 之间;
- 没有任何一个模型能在所有任务类别中全面领先。
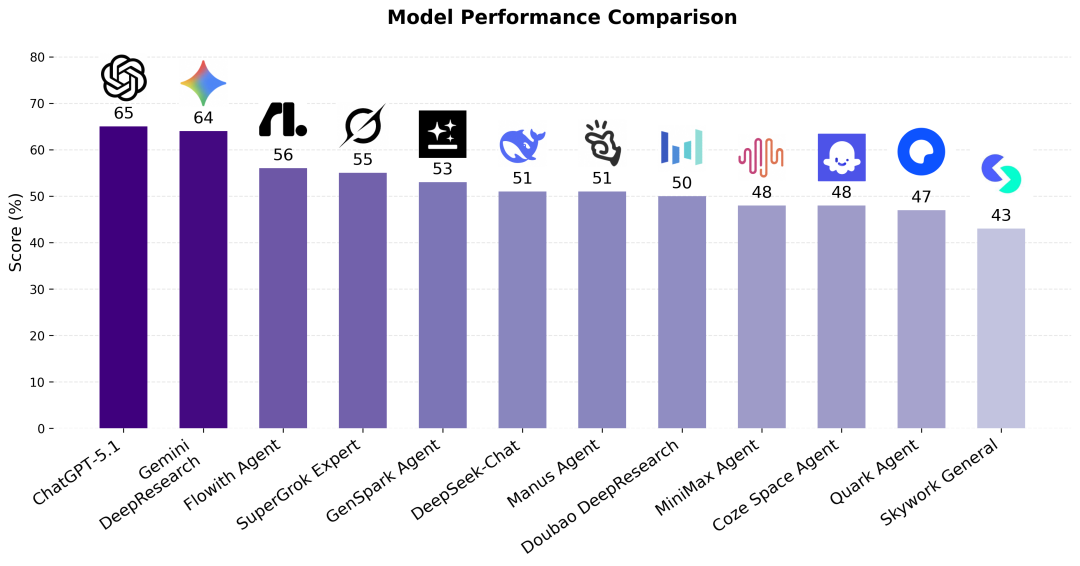
图1:多个现有模型在 EcomBench 基准上的总体表现对比(横轴为正确率百分比)。可以看到,即使最先进的模型,其准确率也仅在65%多,尚有巨大提升空间。
有的模型擅长政策问答,却在成本计算上频频出错;有的能做选品推荐,却对合规要求一知半解。这种“偏科”现象说明,当前 Agent 距离真正可靠的“全能电商助手”,仍有巨大差距。
EcomBench 的价值,正是量化这些差距,为后续模型优化提供明确方向。
未来,题库将持续纳入趋势预测、战略决策等高级任务,不断提升挑战门槛。我们也希望 EcomBench 能像 ImageNet 之于计算机视觉一样,成为推动电商 Agent 技术突破的“催化剂”。
在它的鞭策下,新一代电商 Agent 将变得更聪明、稳健、可信赖——真正从“会说话”走向“会做事”。
****当 AI 遇到电商,****你最希望 AI 帮你解决哪类电商难题?是算税费、做选品,还是搞营销?欢迎评论区留言~
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









