



文章介绍5种AI Agent结构化工作流模式:串行链式处理、智能路由、并行处理、编排器-工作器架构和评估器-优化器循环。这些模式通过分解任务、合理分配资源、并行处理、智能编排和反馈优化,解决了简单提示词方式带来的输出不可控、质量不稳定问题。掌握这些工作流能实现对AI系统的完全控制,稳定获得高质量结果。
很多人认为使用AI Agent就是直接扔个提示词过去,然后等结果。做实验这样是没问题的,但要是想在生产环境稳定输出高质量结果,这套玩法就不行了。
核心问题是这种随意的提示方式根本扩展不了。你会发现输出结果乱七八糟,质量完全不可控,还浪费计算资源。
真正有效的做法是设计结构化的Agent工作流。
那些做得好的团队从来不指望一个提示词解决所有问题。他们会把复杂任务拆解成步骤,根据不同输入选择合适的模型,然后持续验证输出质量,直到结果达标。
本文会详细介绍5种常用的的Agent工作流模式,每种都有完整的实现代码和使用场景分析。看完你就知道每种模式解决什么问题,什么时候用,以及为什么能产生更好的效果。
模式一:串行链式处理
链式处理的核心思路是把一个LLM调用的输出直接作为下一个调用的输入。比起把所有逻辑塞进一个巨大的提示词,拆分成小步骤要靠谱得多。
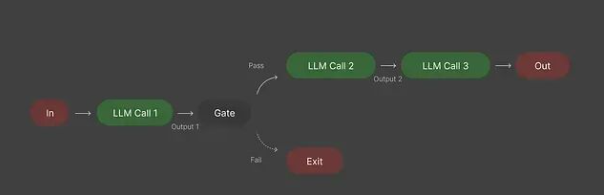
道理很简单:步骤越小,出错的概率越低。链式处理等于给模型提供了明确的推理路径,而不是让它自己瞎猜。
如果不用链式处理,你可能会经常会遇到输出冗长混乱、前后逻辑不一致、错误率偏高的问题。有了链式处理,每一步都可以单独检查,整个流程的可控性会大幅提升。
from typing import List
from helpers import run_llm
def serial_chain_workflow(input_query: str, prompt_chain : List[str]) -> List[str]:
"""运行一系列LLM调用来处理`input_query`,
使用`prompt_chain`中指定的提示词列表。
"""
response_chain = []
response = input_query
for i, prompt in enumerate(prompt_chain):
print(f"Step {i+1}")
response = run_llm(f"{prompt}\nInput:\n{response}", model='meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo')
response_chain.append(response)
print(f"{response}\n")
return response_chain
# 示例
question = "Sally earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?"
prompt_chain = ["""Given the math problem, ONLY extract any relevant numerical information and how it can be used.""",
"""Given the numberical information extracted, ONLY express the steps you would take to solve the problem.""",
"""Given the steps, express the final answer to the problem."""]
responses = serial_chain_workflow(question, prompt_chain)
模式二:智能路由
路由系统的作用是决定不同类型的输入应该交给哪个模型处理。
现实情况是,不是每个查询都需要动用你最强大、最昂贵的模型。简单任务用轻量级模型就够了,复杂任务才需要重型武器。路由机制确保资源分配的合理性。
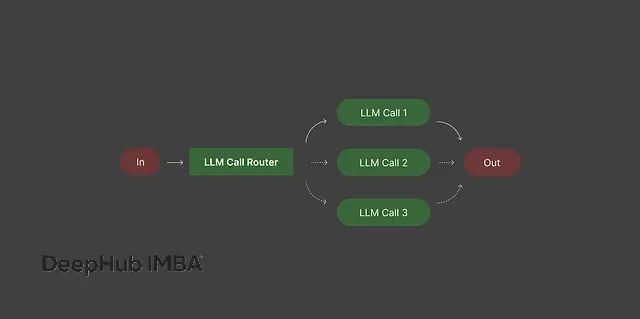
没有路由的话,要么在简单任务上浪费资源,要么用不合适的模型处理复杂问题导致效果很差。
实现路由需要先定义输入的分类标准,比如简单查询、复杂推理、受限领域等,然后为每个类别指定最适合的模型或处理流程。这样做的好处是成本更低、响应更快、质量更稳定,因为每种任务都有专门的工具来处理。
from pydantic import BaseModel, Field
from typing import Literal, Dict
from helpers import run_llm, JSON_llm
def router_workflow(input_query: str, routes: Dict[str, str]) -> str:
"""给定一个`input_query`和包含每个选项和详细信息的`routes`字典。
为任务选择最佳模型并返回模型的响应。
"""
ROUTER_PROMPT = """Given a user prompt/query: {user_query}, select the best option out of the following routes:
{routes}. Answer only in JSON format."""
# 从路由字典创建模式
class Schema(BaseModel):
route: Literal[tuple(routes.keys())]
reason: str = Field(
description="Short one-liner explanation why this route was selected for the task in the prompt/query."
)
# 调用LLM选择路由
selected_route = JSON_llm(
ROUTER_PROMPT.format(user_query=input_query, routes=routes), Schema
)
print(
f"Selected route:{selected_route['route']}\nReason: {selected_route['reason']}\n"
)
# 在选定的路由上使用LLM。
# 也可以为每个路由使用不同的提示词。
response = run_llm(user_prompt=input_query, model=selected_route["route"])
print(f"Response: {response}\n")
return response
prompt_list = [
"Produce python snippet to check to see if a number is prime or not.",
"Plan and provide a short itenary for a 2 week vacation in Europe.",
"Write a short story about a dragon and a knight.",
]
model_routes = {
"Qwen/Qwen2.5-Coder-32B-Instruct": "Best model choice for code generation tasks.",
"Gryphe/MythoMax-L2-13b": "Best model choice for story-telling, role-playing and fantasy tasks.",
"Qwen/QwQ-32B-Preview": "Best model for reasoning, planning and multi-step tasks",
}
for i, prompt in enumerate(prompt_list):
print(f"Task {i+1}: {prompt}\n")
print(20 * "==")
router_workflow(prompt, model_routes)
模式三:并行处理
大部分人习惯让LLM一个任务一个任务地处理。但如果任务之间相互独立,完全可以并行执行然后合并结果,这样既节省时间又能提升输出质量。
并行处理的思路是把大任务分解成可以同时进行的小任务,等所有部分都完成后再把结果整合起来。
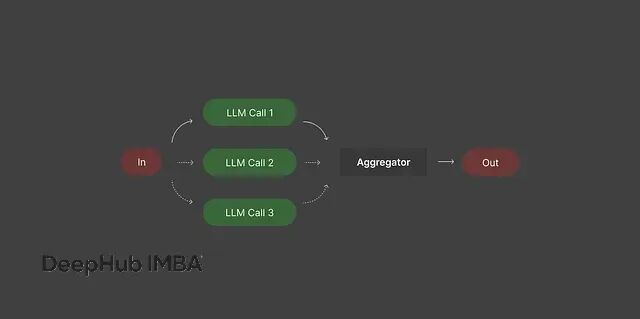
比如做代码审查的时候,可以让一个模型专门检查安全问题,另一个关注性能优化,第三个负责代码可读性,最后把所有反馈合并成完整的审查报告。文档分析也是类似的思路:把长报告按章节拆分,每个部分单独总结,再合并成整体摘要。文本分析任务中,情感分析、实体提取、偏见检测可以完全并行进行。
不用并行处理的话,不仅速度慢,还容易让单个模型负担过重,导致输出混乱或者前后不一致。并行方式让每个模型专注于自己擅长的部分,最终结果会更准确,也更容易维护。
import asyncio
from typing import List
from helpers import run_llm, run_llm_parallel
async def parallel_workflow(prompt : str, proposer_models : List[str], aggregator_model : str, aggregator_prompt: str):
"""运行并行LLM调用链来处理`input_query`,
使用`models`中指定的模型列表。
返回最终聚合器模型的输出。
"""
# 从建议器模型收集中间响应
proposed_responses = await asyncio.gather(*[run_llm_parallel(prompt, model) for model in proposer_models])
# 使用聚合器模型聚合响应
final_output = run_llm(user_prompt=prompt,
model=aggregator_model,
system_prompt=aggregator_prompt + "\n" + "\n".join(f"{i+1}. {str(element)}" for i, element in enumerate(proposed_responses)
))
return final_output, proposed_responses
reference_models = [
"microsoft/WizardLM-2-8x22B",
"Qwen/Qwen2.5-72B-Instruct-Turbo",
"google/gemma-2-27b-it",
"meta-llama/Llama-3.3-70B-Instruct-Turbo",
]
user_prompt = """Jenna and her mother picked some apples from their apple farm.
Jenna picked half as many apples as her mom. If her mom got 20 apples, how many apples did they both pick?"""
aggregator_model = "deepseek-ai/DeepSeek-V3"
aggregator_system_prompt = """You have been provided with a set of responses from various open-source models to the latest user query.
Your task is to synthesize these responses into a single, high-quality response. It is crucial to critically evaluate the information
provided in these responses, recognizing that some of it may be biased or incorrect. Your response should not simply replicate the
given answers but should offer a refined, accurate, and comprehensive reply to the instruction. Ensure your response is well-structured,
coherent, and adheres to the highest standards of accuracy and reliability.
Responses from models:"""
async def main():
answer, intermediate_reponses = await parallel_workflow(prompt = user_prompt,
proposer_models = reference_models,
aggregator_model = aggregator_model,
aggregator_prompt = aggregator_system_prompt)
for i, response in enumerate(intermediate_reponses):
print(f"Intermetidate Response {i+1}:\n\n{response}\n")
print(f"Final Answer: {answer}\n")
模式四:编排器-工作器架构
这种模式的特点是用一个编排器模型来规划整个任务,然后把具体的子任务分配给不同的工作器模型执行。
编排器的职责是分析任务需求,决定执行顺序,你不需要事先设计好完整的工作流程。工作器模型各自处理分配到的任务,编排器负责把所有输出整合成最终结果。
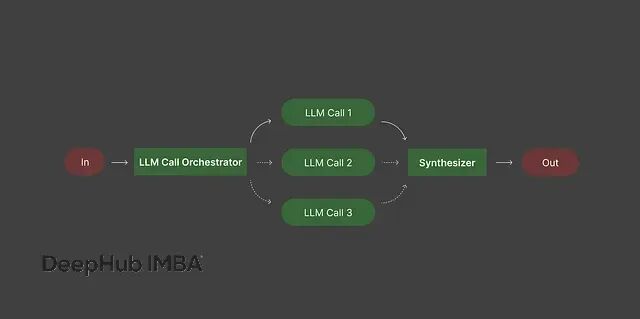
这种架构在很多场景下都很实用。写博客文章的时候,编排器可以把任务拆分成标题设计、内容大纲、具体章节写作,然后让专门的工作器处理每个部分,最后组装成完整文章。开发程序时,编排器负责分解成环境配置、核心功能实现、测试用例编写等子任务,不同的工作器生成对应的代码片段。数据分析报告也是类似思路:编排器识别出需要数据概览、关键指标计算、趋势分析等部分,工作器分别生成内容,编排器最后整合成完整报告。
这种方式的好处是减少了人工规划的工作量,同时保证复杂任务的有序进行。编排器处理任务管理,每个工作器专注于自己的专业领域,整个流程既有条理又有效率。
import asyncio
import json
from pydantic import BaseModel, Field
from typing import Literal, List
from helpers import run_llm_parallel, JSON_llm
ORCHESTRATOR_PROMPT = """
分析这个任务并将其分解为2-3种不同的方法:
任务: {task}
提供分析:
解释你对任务的理解以及哪些变化会有价值。
关注每种方法如何服务于任务的不同方面。
除了分析之外,提供2-3种处理任务的方法,每种都有简要描述:
正式风格: 技术性和精确地写作,专注于详细规范
对话风格: 以友好和引人入胜的方式写作,与读者建立联系
混合风格: 讲述包含技术细节的故事,将情感元素与规范相结合
仅返回JSON输出。
"""
WORKER_PROMPT = """
基于以下内容生成内容:
任务: {original_task}
风格: {task_type}
指导原则: {task_description}
仅返回你的响应:
[你的内容在这里,保持指定的风格并完全满足要求。]
"""
task = """为新的环保水瓶写一个产品描述。
目标受众是有环保意识的千禧一代,关键产品特性是:无塑料、保温、终身保修
"""
class Task(BaseModel):
type: Literal["formal", "conversational", "hybrid"]
description: str
class TaskList(BaseModel):
analysis: str
tasks: List[Task] = Field(..., default_factory=list)
async def orchestrator_workflow(task : str, orchestrator_prompt : str, worker_prompt : str):
"""使用编排器模型将任务分解为子任务,然后使用工作器模型生成并返回响应。"""
# 使用编排器模型将任务分解为子任务
orchestrator_response = JSON_llm(orchestrator_prompt.format(task=task), schema=TaskList)
# 解析编排器响应
analysis = orchestrator_response["analysis"]
tasks= orchestrator_response["tasks"]
print("\n=== ORCHESTRATOR OUTPUT ===")
print(f"\nANALYSIS:\n{analysis}")
print(f"\nTASKS:\n{json.dumps(tasks, indent=2)}")
worker_model = ["meta-llama/Llama-3.3-70B-Instruct-Turbo"]*len(tasks)
# 从工作器模型收集中间响应
return tasks , await asyncio.gather(*[run_llm_parallel(user_prompt=worker_prompt.format(original_task=task, task_type=task_info['type'], task_description=task_info['description']), model=model) for task_info, model in zip(tasks,worker_model)])
async def main():
task = """为新的环保水瓶写一个产品描述。
目标受众是有环保意识的千禧一代,关键产品特性是:无塑料、保温、终身保修
"""
tasks, worker_resp = await orchestrator_workflow(task, orchestrator_prompt=ORCHESTRATOR_PROMPT, worker_prompt=WORKER_PROMPT)
for task_info, response in zip(tasks, worker_resp):
print(f"\n=== WORKER RESULT ({task_info['type']}) ===\n{response}\n")
asyncio.run(main())
模式五:评估器-优化器循环
这种模式的核心是通过反馈循环来持续改进输出质量。
具体机制是一个模型负责生成内容,另一个评估器模型按照预设的标准检查输出质量。如果没达标,生成器根据反馈进行修改,评估器再次检查,这个过程一直重复到输出满足要求为止。
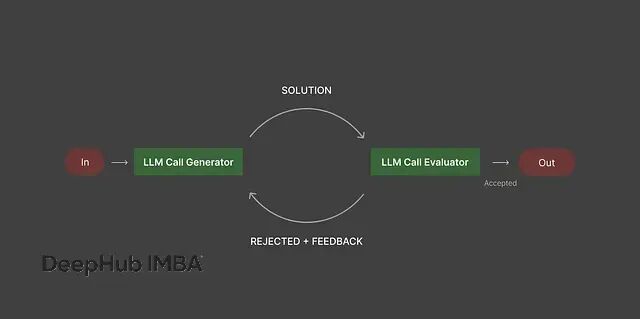
在代码生成场景中,生成器写出代码后,评估器会检查语法正确性、算法效率、代码风格等方面,发现问题就要求重写。营销文案也是类似流程:生成器起草内容,评估器检查字数限制、语言风格、信息准确性,不合格就继续改。数据报告的制作过程中,生成器产出分析结果,评估器验证数据完整性和结论的逻辑性。
如果没有这套评估优化机制,输出质量会很不稳定,需要大量人工检查和修正。有了评估器-优化器循环,可以自动保证结果符合预期标准,减少重复的手工干预。
from pydantic import BaseModel
from typing import Literal
from helpers import run_llm, JSON_llm
task = """
实现一个栈,包含:
1. push(x)
2. pop()
3. getMin()
所有操作都应该是O(1)。
"""
GENERATOR_PROMPT = """
你的目标是基于<用户输入>完成任务。如果有来自你之前生成的反馈,
你应该反思它们来改进你的解决方案
以下列格式简洁地输出你的答案:
思路:
[你对任务和反馈的理解以及你计划如何改进]
响应:
[你的代码实现在这里]
"""
def generate(task: str, generator_prompt: str, context: str = "") -> tuple[str, str]:
"""基于反馈生成和改进解决方案。"""
full_prompt = f"{generator_prompt}\n{context}\n任务: {task}" if context else f"{generator_prompt}\n任务: {task}"
response = run_llm(full_prompt, model="Qwen/Qwen2.5-Coder-32B-Instruct")
print("\n## Generation start")
print(f"Output:\n{response}\n")
return response
EVALUATOR_PROMPT = """
评估以下代码实现的:
1. 代码正确性
2. 时间复杂度
3. 风格和最佳实践
你应该只进行评估,不要尝试解决任务。
只有当所有标准都得到满足且你没有进一步改进建议时,才输出"PASS"。
如果有需要改进的地方,请提供详细反馈。你应该指出需要改进什么以及为什么。
只输出JSON。
"""
def evaluate(task : str, evaluator_prompt : str, generated_content: str, schema) -> tuple[str, str]:
"""评估解决方案是否满足要求。"""
full_prompt = f"{evaluator_prompt}\n原始任务: {task}\n要评估的内容: {generated_content}"
# 构建评估模式
class Evaluation(BaseModel):
evaluation: Literal["PASS", "NEEDS_IMPROVEMENT", "FAIL"]
feedback: str
response = JSON_llm(full_prompt, Evaluation)
evaluation = response["evaluation"]
feedback = response["feedback"]
print("## Evaluation start")
print(f"Status: {evaluation}")
print(f"Feedback: {feedback}")
return evaluation, feedback
def loop_workflow(task: str, evaluator_prompt: str, generator_prompt: str) -> tuple[str, list[dict]]:
"""持续生成和评估,直到评估器通过最后生成的响应。"""
# 存储生成器的先前响应
memory = []
# 生成初始响应
response = generate(task, generator_prompt)
memory.append(response)
# 当生成的响应没有通过时,继续生成和评估
while True:
evaluation, feedback = evaluate(task, evaluator_prompt, response)
# 终止条件
if evaluation == "PASS":
return response
# 将当前响应和反馈添加到上下文中并生成新响应
context = "\n".join([
"Previous attempts:",
*[f"- {m}" for m in memory],
f"\nFeedback: {feedback}"
])
response = generate(task, generator_prompt, context)
memory.append(response)
loop_workflow(task, EVALUATOR_PROMPT, GENERATOR_PROMPT)
总结
这些结构化工作流彻底改变了LLM的使用方式。
不再是随便抛个提示词然后碰运气,而是有章法地分解任务、合理分配模型资源、并行处理独立子任务、智能编排复杂流程,再通过评估循环保证输出质量。
每种模式都有明确的适用场景,组合使用能让你更高效地处理各种复杂任务。可以先从一个模式开始熟悉,掌握之后再逐步引入其他模式。
当你把路由、编排、并行处理、评估优化这些机制组合起来使用时,就彻底告别了那种混乱、不可预测的提示方式,转而获得稳定、高质量、可用于生产环境的输出结果。长期来看,这种方法不仅节省时间,更重要的是给你对AI系统的完全控制权,让每次输出都在预期范围内,从根本上解决了临时提示方式带来的各种问题。
掌握这些工作流模式,你就能充分发挥AI的潜力,稳定地获得高质量结果。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】

















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









