



今儿和大家聊聊Transformer涉及到的 3 大核心创新点。
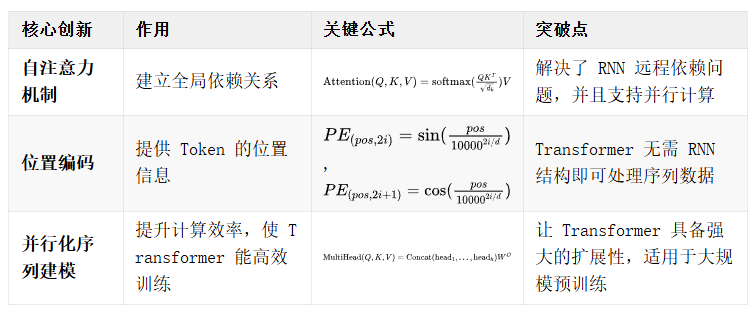
Transformer 的三大核心创新:自注意力机制、位置编码、并行化序列建模。
彻底改变了自然语言处理(NLP)和深度学习领域~
一、自注意力机制
自注意力机制是一种让每个词(Token)在计算表示时能够关注序列中其他所有词的方法。与传统 RNN 只能依赖前序信息不同,自注意力能够在计算时同时关注整个序列,从而更好地捕捉长距离依赖关系。
突破创新点
-
突破了 RNN 的局限性:RNN 结构使得远距离信息难以传递(梯度消失问题),而自注意力机制可以直接建立全局联系,避免了长依赖问题。
-
计算复杂度相较于 CNN 更低:CNN 在建模长依赖时需要增加更多层数,而自注意力机制一次计算即可捕获整个输入序列的全局信息。
-
提升并行性:RNN 由于时间步(Time step)依赖,难以并行化计算,而自注意力机制可并行计算所有 Token 之间的关系。
核心公式

推理

二、位置编码
Transformer 没有像 RNN 那样的递归结构,因此需要额外的机制来编码序列中 Token 之间的位置信息。位置编码(Positional Encoding)通过加入特定的数学函数,使模型能够区分不同位置的 Token。
突破创新点
-
弥补 Transformer 缺少位置信息的缺陷:由于 Transformer 仅依赖于自注意力机制,而不像 RNN 通过时间步递归建模,因此必须显式引入位置信息。
-
可学习 vs. 固定编码:Transformer 论文使用的是固定的三角函数编码(Sine and Cosine),但后续研究也提出了可学习的位置编码方法。
-
允许任意长度的序列:三角函数编码方式使得 Transformer 具备处理长文本的能力,因为它能够对不同长度的输入编码具有泛化能力。
核心公式

推理

三、并行化序列建模
RNN 由于其递归特性,计算每个 Token 的表示都依赖于前一个 Token,导致难以并行化。Transformer 通过自注意力机制,使得所有 Token 之间的依赖关系可以同时计算,从而实现高效的并行计算。
突破创新点

核心公式

推理
-
输入矩阵化处理:由于 Transformer 采用矩阵操作,每个 Token 的计算可以同时进行。
-
多头注意力并行计算:多个注意力头可以独立计算不同的信息模式,然后合并。
-
加速训练:相比 RNN 需要逐步计算隐藏状态,Transformer 可一次性计算整个序列,使得 GPU 并行计算更高效。
四、总结
这三大核心创新彻底改变了深度学习的范式,推动了大规模语言模型(如 GPT、BERT)的发展。
五、完整案例
咱们这里给出一个基于 PyTorch 的核心代码示例,它实现了 Transformer 中的关键组件:位置编码、自注意力(以及多头自注意力),组装成一个简单的 Transformer Block。
同时,代码中绘制了 4 个示意图,直观展示了自注意力、位置编码、多头注意力以及并行化序列处理的原理。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import matplotlib.pyplot as plt
# 位置编码模块:利用正弦和余弦函数生成位置向量
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model) # (max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (max_len, 1)
# 按照公式计算正弦和余弦的归一化因子
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维使用 sin
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维使用 cos
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
# x: (batch_size, seq_len, d_model)
seq_len = x.size(1)
# 将位置编码加到输入嵌入上
x = x + self.pe[:, :seq_len, :]
return x
# 自注意力机制模块:基于 Query、Key、Value 计算注意力
class SelfAttention(nn.Module):
def __init__(self, d_model, d_k):
super(SelfAttention, self).__init__()
self.d_k = d_k
self.query = nn.Linear(d_model, d_k)
self.key = nn.Linear(d_model, d_k)
self.value = nn.Linear(d_model, d_k)
def forward(self, x):
# x: (batch_size, seq_len, d_model)
Q = self.query(x) # (batch_size, seq_len, d_k)
K = self.key(x) # (batch_size, seq_len, d_k)
V = self.value(x) # (batch_size, seq_len, d_k)
# 计算注意力得分(缩放点积)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k) # (batch_size, seq_len, seq_len)
attn = F.softmax(scores, dim=-1)
# 加权求和得到输出
output = torch.matmul(attn, V) # (batch_size, seq_len, d_k)
return output, attn
# 多头注意力模块:并行计算多个自注意力头,最后拼接输出
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.linear_q = nn.Linear(d_model, d_model)
self.linear_k = nn.Linear(d_model, d_model)
self.linear_v = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
# 线性映射得到 Q, K, V
Q = self.linear_q(x) # (batch_size, seq_len, d_model)
K = self.linear_k(x)
V = self.linear_v(x)
# 分头:将 d_model 分割为 num_heads 个子空间
Q = Q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1,
2) # (batch_size, num_heads, seq_len, d_k)
K = K.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# 计算注意力得分
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k) # (batch_size, num_heads, seq_len, seq_len)
attn = F.softmax(scores, dim=-1)
# 计算每个头的注意力输出
x_attn = torch.matmul(attn, V) # (batch_size, num_heads, seq_len, d_k)
# 拼接各个头
x_attn = x_attn.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
output = self.out_proj(x_attn)
return output, attn
# 简单的 Transformer Block:集成位置编码、多头自注意力和前馈网络
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads, max_len=100):
super(TransformerBlock, self).__init__()
self.pos_encoding = PositionalEncoding(d_model, max_len)
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_model * 4),
nn.ReLU(),
nn.Linear(d_model * 4, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x):
# 添加位置编码
x = self.pos_encoding(x)
# 多头自注意力及残差连接
attn_output, attn_weights = self.mha(x)
x = self.norm1(x + attn_output)
# 前馈网络及残差连接
ffn_output = self.ffn(x)
x = self.norm2(x + ffn_output)
return x, attn_weights
# 主程序:测试 Transformer Block 并绘制示意图
if __name__ == "__main__":
# 参数设置
batch_size = 2
seq_len = 10
d_model = 32
num_heads = 4
# 随机输入(模拟词向量序列)
x = torch.randn(batch_size, seq_len, d_model)
# 创建 Transformer Block
transformer = TransformerBlock(d_model, num_heads, max_len=50)
out, attn_weights = transformer(x)
print("Transformer Block 输出 shape:", out.shape)
# 绘制示意图(4幅图绘制在一张图中)
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 图1:自注意力机制示意图
axes[0, 0].set_title("Self-Attention Mechanism Diagram")
axes[0, 0].text(0.1, 0.8, "Input Sequence X", fontsize=12, bbox=dict(facecolor='lightblue', alpha=0.5))
axes[0, 0].arrow(0.3, 0.8, 0.3, 0, head_width=0.05, head_length=0.05)
axes[0, 0].text(0.65, 0.8, "Q, K, V", fontsize=12, bbox=dict(facecolor='lightgreen', alpha=0.5))
axes[0, 0].arrow(0.85, 0.8, 0.1, 0, head_width=0.05, head_length=0.05)
axes[0, 0].text(1.0, 0.8, "Attention", fontsize=12, bbox=dict(facecolor='salmon', alpha=0.5))
axes[0, 0].set_xlim(0, 1.2)
axes[0, 0].set_ylim(0, 1)
axes[0, 0].axis('off')
# 图2:位置编码示意图(绘制正弦和余弦曲线)
axes[0, 1].set_title("Positional Encoding Diagram")
positions = torch.arange(0, 50, dtype=torch.float) # shape: (50,)
d_model_half = d_model // 2# Here d_model_half = 16
# 扩展 positions 和 div_term 的维度使得广播正确
div_term = torch.exp(torch.arange(0, d_model_half, dtype=torch.float) * (-math.log(10000.0) / d_model))
# positions: (50,) -> (50, 1) ; div_term: (16,) -> (1, 16)
positions_expanded = positions.unsqueeze(1) # (50, 1)
div_term_expanded = div_term.unsqueeze(0) # (1, 16)
pe_sin = torch.sin(positions_expanded * div_term_expanded) # (50, 16)
pe_cos = torch.cos(positions_expanded * div_term_expanded) # (50, 16)
# 为了直观展示,选择第1个维度的编码进行绘制
axes[0, 1].plot(positions.numpy(), pe_sin[:, 0].numpy(), label="sin")
axes[0, 1].plot(positions.numpy(), pe_cos[:, 0].numpy(), label="cos")
axes[0, 1].legend()
# 图3:多头注意力示意图
axes[1, 0].set_title("Multi-Head Attention Diagram")
axes[1, 0].text(0.1, 0.8, "Input X", fontsize=12, bbox=dict(facecolor='lightblue', alpha=0.5))
for i in range(num_heads):
y = 0.6 - i * 0.1
axes[1, 0].text(0.3, y, f"Head {i + 1}", fontsize=12, bbox=dict(facecolor='lightgreen', alpha=0.5))
axes[1, 0].arrow(0.45, y, 0.15, 0, head_width=0.03, head_length=0.03)
axes[1, 0].text(0.7, 0.4, "Concat & Linear", fontsize=12, bbox=dict(facecolor='salmon', alpha=0.5))
axes[1, 0].set_xlim(0, 1)
axes[1, 0].set_ylim(0, 1)
axes[1, 0].axis('off')
# 图4:并行化序列建模示意图
axes[1, 1].set_title("Parallelized Sequence Modeling Diagram")
for i in range(seq_len):
axes[1, 1].text(0.1, 0.9 - i * 0.08, f"Token {i + 1}", fontsize=10, bbox=dict(facecolor='lightblue', alpha=0.5))
axes[1, 1].arrow(0.5, 0.9, 0, -0.7, head_width=0.03, head_length=0.03)
axes[1, 1].text(0.55, 0.5, "Parallel Processing", fontsize=12, bbox=dict(facecolor='lightgreen', alpha=0.5))
axes[1, 1].set_xlim(0, 1)
axes[1, 1].set_ylim(0, 1)
axes[1, 1].axis('off')
plt.tight_layout()
plt.show()
-
位置编码(PositionalEncoding): 利用正弦和余弦函数生成每个位置的向量,该向量与输入嵌入相同维度,直接相加以引入位置信息。这解决了 Transformer 无递归结构而缺乏位置信息的问题。
-
自注意力与多头注意力(SelfAttention & MultiHeadAttention): 自注意力模块通过线性变换得到 Query、Key、Value,并通过缩放点积计算注意力权重。多头注意力模块将输入分成多个子空间(头),各头独立计算注意力,然后拼接并线性变换得到最终输出。这部分展示了如何并行计算不同注意力头,从而提高模型表达能力和计算效率。
-
Transformer Block: 结合了位置编码、多头自注意力和前馈网络,并在每一步使用残差连接和层归一化,使得模型更稳定、更易于训练。
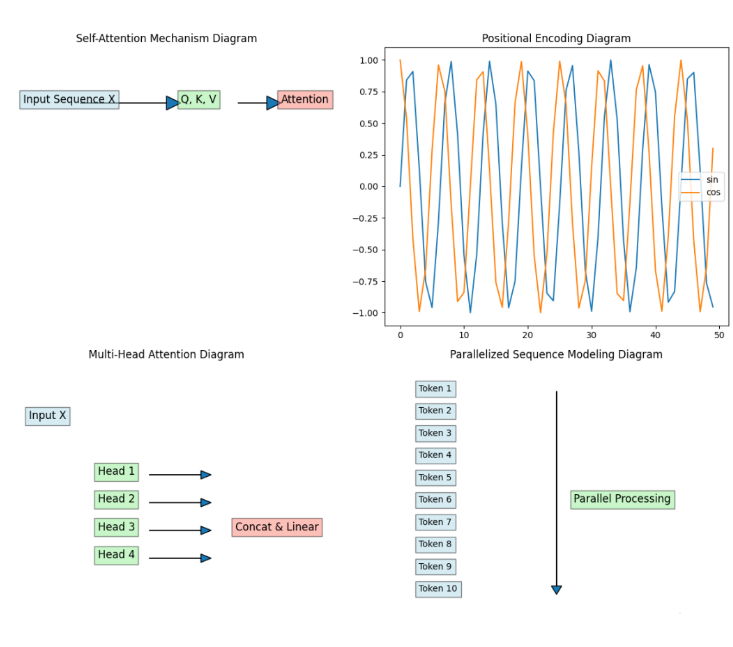
- 图1,用箭头和文本展示了从输入序列到 Q, K, V,再到 Attention 的流程;
- 图2,画出了位置编码中正弦与余弦函数随位置变化的曲线;
- 图3,展示了多头注意力的各个头如何从输入 X 分支开来并最终拼接;
- 图4,用多个 Token 并行的排列和箭头示意,说明 Transformer 能同时处理整个序列,打破了 RNN 逐步计算的限制。
六、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】



















 1471
1471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









