



近日北航在论文《LLaVA-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding》介绍了新型多模态大语言模型LLaVA-ST,专门用于处理细粒度的时空理解任务,通过引入语言对齐的位置嵌入(LAPE)和时空打包器(STP),以及一个包含430 万样本的训练数据集ST-Align,首次实现了对时空事件的联合定位和理解。LLaVA-ST 在 11 个基准测试中展现了卓越的性能,特别是在处理涉及时间、空间和时空交错的细粒度理解任务上。
一、LLaVA-ST
核心看点:
-
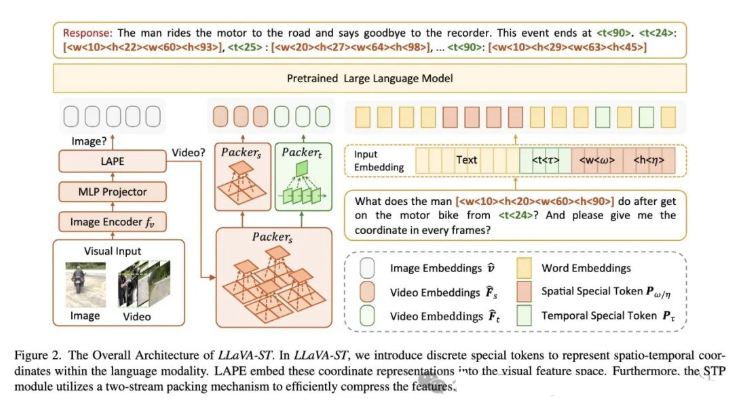
LLaVA-ST 模型架构: 整个模型架构还是以LLM 为底座,对于输入的图像、视频先通过vision encoder 提取特征,然后通过一个MLP 映射到文本空间。接着,使用LAPE 把文本坐标特征叠加到视觉特征里,然后打平扔到LLM 中进行处理。对于视频内容,还会使用STP 进一步压缩得到时间、空间2 个维度的特征,同样也是打平扔到LLM 中进行处理。
-
语言对齐的位置嵌入: LAPE 核心思想是将表示坐标的特殊 token(如 <t<τ>>, <w<ω>>, <h<η>>)直接嵌入到视觉特征空间中作为视觉特征位置编码,从而绕过复杂的跨模态坐标对齐问题。首先,将时间、宽度和高度维度划分为多个区间,并为每个区间分配一个特殊token,然后这些特殊token 扩展到LLM 输入Embedding 和输出Head 中,并把 token Embedding(pw, pη, pτ)和输出Head 权重参数(pω, ˆpη, ˆpτ)1:1 融合作为视觉位置编码,最后通过线性插值将视觉位置编码降采样到与视觉特征相匹配的大小,并与视觉特征相加,完成位置嵌入。微调训练过程中,位置编码中的这2 部分会被随机初始化并与视觉特征的坐标对齐。
-
时空打包器: STP 通过分离时间和空间压缩过程,并采用点到区域的注意力机制,在保留更多时空关系的同时,更有效地压缩视频特征,并保留细粒度信息。STP 分为两个步骤:首先,通过空间维度的降采样减少空间分辨率,得到 F;然后,分别沿着空间和时间维度对F 进行压缩,得到Fs 和Ft。在每个步骤中,都采用了一种点到区域的注意力机制,即将每个降采样(平均池化)后的点特征作为 query,将对应的原始区域特征作为 key 和 value 进行注意力计算,从而将细粒度信息融入到压缩后的特征中。
-
渐进式训练策略: 采用分阶段训练策略,逐步学习内容对齐、坐标对齐和多任务能力,提高训练稳定性和最终性能。训练分为三个阶段,1)内容对齐: 使用视频字幕数据初步对齐视觉和语言内容,此时只训练 STP 模块,固定LLM 参数。2)坐标对齐: 使用需要细粒度视觉理解的任务(如 REC、DGC、TVG、DVC 等)训练模型对齐时空坐标,同时训练STP 和LLM(以LoRA 方式)。3)多任务指令微调: 引入多种高质量标注数据集,包括 VQA、REC、TVG 以及新引入的 STVG、ELC、SVG 等,进一步提升模型的多任务能力和细粒度时空理解能力。训练方式跟阶段二类似,但LLM 部分会使用新的LoRA 参数。
-
ST-Align 数据集: ST-Align 数据集包含约 430 万个训练样本,涵盖15 种不同的细粒度多模态理解任务,包括通用视觉理解任务、空间细粒度理解任务、时间细粒度理解任务、时空交错细粒度理解任务,特别地,针对时空交错理解任务,利用 GPT-4-turbo 对VidSTG 数据集进行了修订和增强,并对每种任务额外用2000 条样本进行评估。
二、总结
模型整体架构还是同LLaVA 一脉相承,但是通过引入LAPE 很好地处理了文本坐标与视觉坐标的对齐问题,接着又通过STP 解决时空建模计算复杂度的问题,思路很清晰。
引用:
- LLaVA-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding:https://arxiv.org/pdf/2501.08282v1
三、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









