



一、引言
多任务学习(MTL)旨在让模型经过一个训练过程中,让模型具备处理多种任务的能力。简单来说,MTL能够在不同任务之间共享信息,有效提高模型的泛化能力和数据效率。多任务学习的关键主要体现在参数共享、联合损失函数、权重调整等方面。
当前将大模型作为骨干模型,进行多任务学习,是高效利用大模型能力一种方法。但是现有的MTL策略在LLMs微调过程中,「会存在两个问题:1)计算资源要求高;2)无法保证多任务的同时收敛」。为此,今天给大家分享的这篇文章,为了解决这两个问题,「提出了一种新型MTL方法:CoBa」,即在训练过程CoBa可以动态地调整任务权重,促进各任务收敛平衡,降低了计算资源要求;结果表明:该方法可以让LLMs的性能最高提升13%。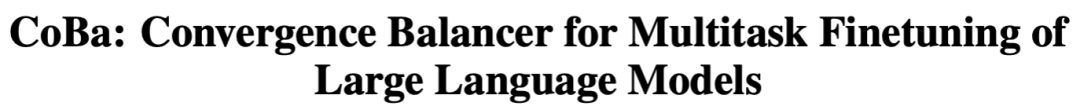 论文:https://arxiv.org/pdf/2410.06741
论文:https://arxiv.org/pdf/2410.06741
代码:https://github.com/codefuse-ai/MFTCoder
本文源于蚂蚁集团AI native团队自研项目,现已被 「EMNLP2024」 接受为Oral Presentation。
二、背景介绍
近年来,大语言模型(LLMs)因其强大的性能成为研究热点。LLMs通过预训练积累大量通用知识,并在微调阶段针对具体任务进一步优化。但由于每个任务需要单独微调,部署变得复杂,且模型规模大,资源消耗高。
为了解决这些问题,多任务学习(MTL)应运而生。MTL通过一个模型支持多个任务,显著节省计算和存储资源,同时还能提升任务的整体性能和泛化能力。LLMs大规模的参数空间使其具有很强的适应性,能够在支持多任务的同时实现较好的效果,比如OpenAI的GPT-3.5和GPT-4就展示了这种能力。
为了在LLMs上实现高效的MTL,需要满足两个关键要求:「减少额外计算成本」,以及 「确保所有任务可以同时收敛」,并优化至共享的最优点。虽然在小模型上有效,但在处理LLMs时计算成本高且整合复杂。例如,GradNorm、FAMO和MetaWeighting等方法的计算成本随着任务数量显著上升(如下表所示),此外,像Muppet和ExT5这样的多任务模型未能有效解决任务收敛不均衡,模型的整体效果未能达到最佳。

 为此,本文作者提出了一种新型多任务学习方法CoBa(COnvergence BAlancer),「专注于以最低计算开销实现各任务的收敛平衡」,并适应于大语言模型(LLMs)的训练。
为此,本文作者提出了一种新型多任务学习方法CoBa(COnvergence BAlancer),「专注于以最低计算开销实现各任务的收敛平衡」,并适应于大语言模型(LLMs)的训练。
三、CoBa介绍
CoBa的核心策略是基于验证数据中的收敛趋势,动态调整每个任务的训练损失权重。

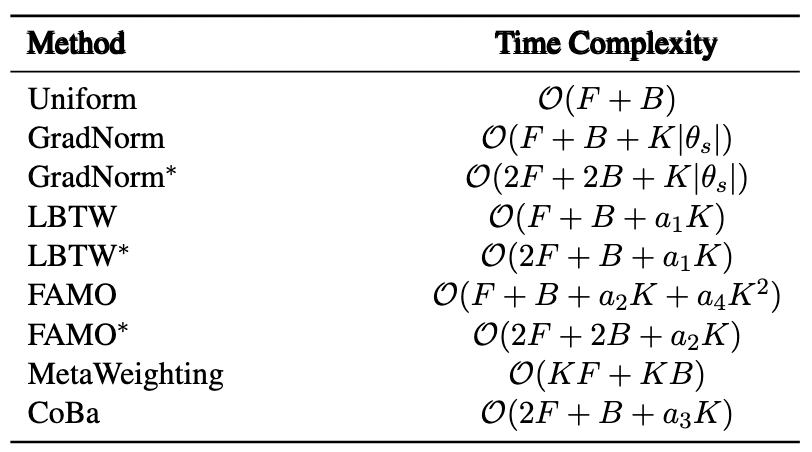
「下图1:CoBa在真实训练场景下的任务权重计算过程」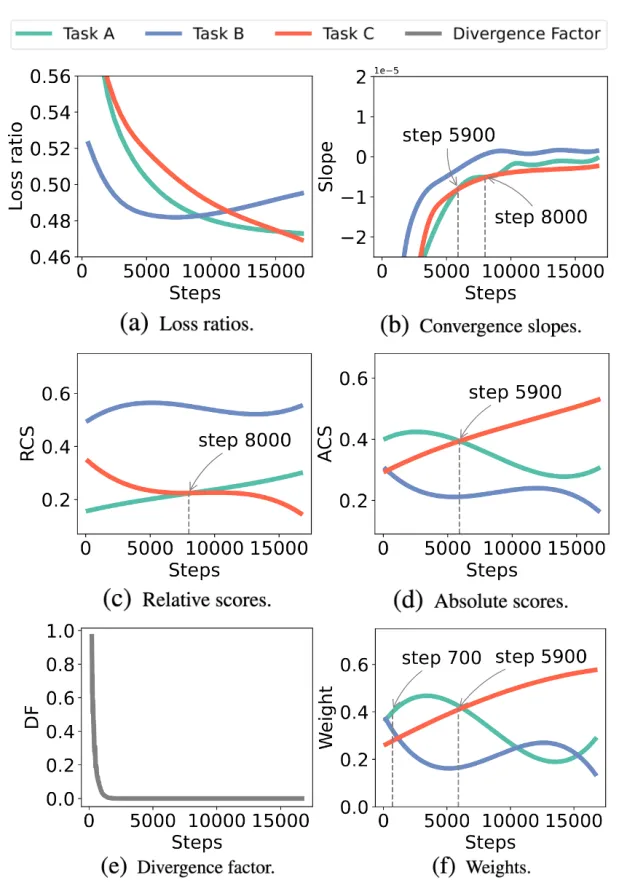

「准则一:平衡收敛速度」:当所有任务的验证损失在下降时,减小收敛较快任务的权重,增大收敛较慢任务的权重。
「准则二:避免任务发散」:对接近发散(可能过拟合)的任务减小权重,对仍然稳定收敛的任务增大权重。
为实现这两项准则,CoBa引入了相对收敛分数(RCS)和绝对收敛分数(ACS),其中RCS旨在评估任务之间的相对收敛速度,ACS旨在衡量每个任务当前的收敛速率与其历史速率的对比。同时作者还引入一个发散因子(DF),确保在所有任务都在收敛时,RCS对权重的影响占主导地位,而当某一特定任务开始发散时,ACS将起主导地位。
收敛斜率
不同任务的收敛速度可以通过观察验证损失曲线的斜率来直观地衡量。在图1(a)展示的某种情况中,绿色曲线任务B在5900步前的收敛速度都快于红色曲线任务C。如图1(b)所示,这一现象体现在了任务B的曲线斜率更陡,从而表示着任务B的收敛斜率绝对值高于任务C。作者在选定的迭代范围内拟合一个由定义的线性模型,其中的就是该段迭代内的收敛斜率的估计。为应对初始收敛斜率的不准确性,作者方法引入了warm-up参数。warm-up期间各任务权重被统一设置为以确保平衡的起点。warm-up期结束后,将根据滑动窗口内的收敛斜率更新权重。
相对收敛分数(RCS)
RCS的目标是根据任务的收敛速度动态分配权重,即对收敛较快的任务分配较小的权重,对收敛较慢的任务分配较大的权重:

在实际训练场景中,如图1(a)所示,可以观察到任务B(蓝色曲线)的收敛速度最慢,其RCS值是最高的(图1©)。此外,任务C(红色曲线)在第8000步前的收敛速度慢于任务A(绿色曲线),任务C的RCS高于任务A。
绝对收敛分数(ACS)
仅凭RCS无法同时满足前文提到的两个多任务学习的需求,因为任务B虽然已经开始发散,但仍然获得了最高的RCS(如图1(a)和1©所示)这可能使整体模型性能下降。因此ACS是必要的,通过为即将发散任务分配较小的权重,而对仍在收敛的任务赋予更大的权重,降低此类风险。ACS对数学表达式为:
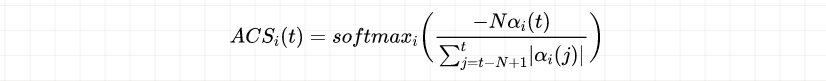
ACS的计算方式与RCS不同,先沿着迭代维度进行归一化,随后才在任务维度上进行softmax操作,且在归一化过程中仅考虑任务自身的历史表现。此外,ACS式子中的反向归一化能让持续收敛的任务获得一个比开始发散任务更高的值。最后在任务间应用softmax分配ACS权重,实现增强收敛任务和抑制发散任务效果。
如图1(a),1(b)和1(d)所示,任务B由于最早开始发散而获得最小的ACS。此外,由于任务A和任务C在5900步前后的收敛斜率相对大小发生变化,其ACS的相对大小也发生了转变。
发散因子(DF)和最终权重
在训练初期,任务通常表现为收敛模式,此时RCS应在权重分配占主导。随着训练进行,部分任务可能发散,此时ACS应优先影响权重分配。为实现从RCS主导到ACS主导的无缝过渡,我们引入发散因子(DF)来监控发散趋势。则最终的权重向量可以表示为:

在softmax函数中,我们将分子乘以当前步数,以防止随着增加而急剧下降,温度参数确保了softmax输出分量的区分度。
CoBa与现有方法的差别
当前的收敛平衡方法主要通过减缓快任务和加速慢任务来实现,作者提出的RCS同样有效地实现了这一目标。然而,当某些任务开始发散时,这种方式会产生反作用,影响收敛平衡。为此,CoBa引入了ACS和DF,有助于抑制某些任务过早的发散趋势,从而确保多任务训练的整体稳定性。
四、实验结果分析
作者在 「四个不同数据集」 上评估了CoBa的表现:代码补全(CC)数据集、代码相关任务(CRT)数据集、XTREME-UP数据集以及多领域问答数据集;除此之外,作者将 「CoBa与八个最先进的基准模型(SOTA)进行对比」:单任务学习(STL),Uniform,GradNorm,LBTW和FAMO。值得注意的是,后三种方法最初是基于训练损失设计的。为了提高泛化能力,作者已将这些方法调整为关注验证损失,分别记作LBTW、GradNorm和FAMO。
「下表2为:Phi-1.5-1.3B模型在CC数据集上的实验结果」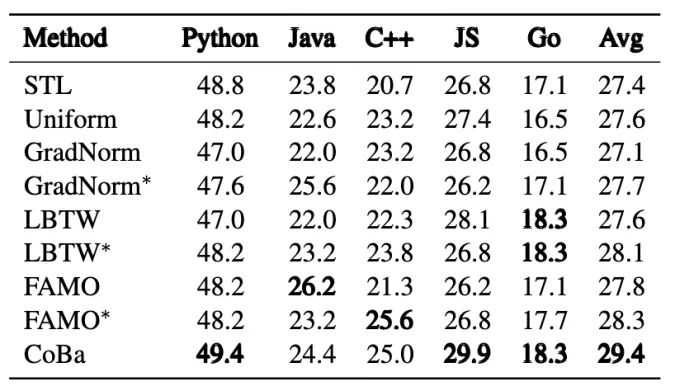 「下表3,为CodeLlama-13B-Python模型在CC数据集上的实验结果」
「下表3,为CodeLlama-13B-Python模型在CC数据集上的实验结果」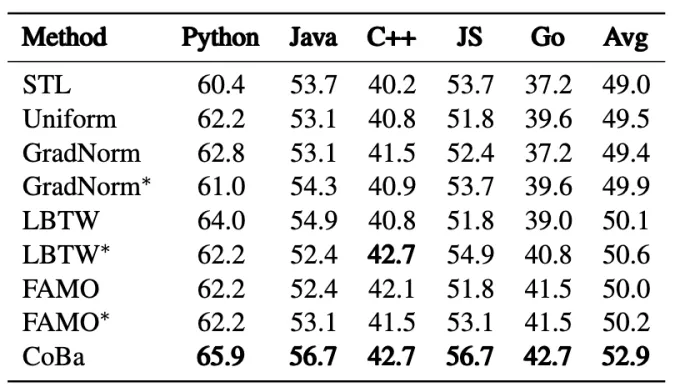 「下图4:Phi-1.5-1.3B模型的CC实验中5种语言的归一化验证损失收敛情况对比」
「下图4:Phi-1.5-1.3B模型的CC实验中5种语言的归一化验证损失收敛情况对比」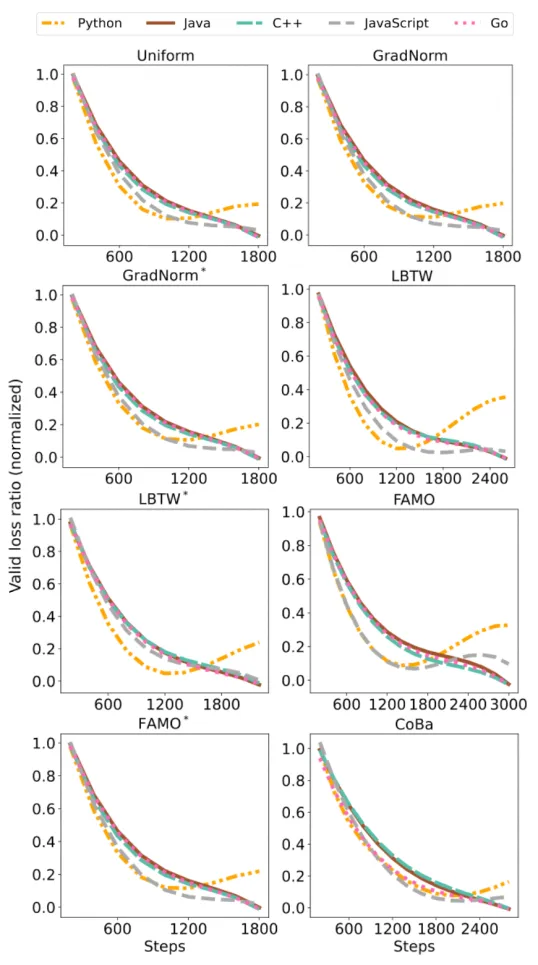 表2和图4展示了所有方法在CC数据集上的表现。「CoBa在五种编程语言的Pass@1指标上表现优于基线方法,平均得分至少提高4%」 。此外,将FAMO、LBTW和GradNorm适配于验证损失(即、和)能有效提升性能,这一提升强调了根据验证损失来平衡收敛速度从而增强泛化能力的重要性。虽然的表现接近CoBa,但在Python补全任务中存在潜在的发散趋势(图4),影响了整体效果。相较之下,CoBa通过利用ACS和DF,有效地缓解了该问题。尽管GradNorm旨在以相同速度学习所有任务,但由于其采用相同且较小的学习率更新权重和模型参数,因此其性能仍落后于CoBa、FAMO和LBTW等方法。此策略在LLMs训练场景下表现不佳,导致GradNorm调整的权重几乎与初始的均匀权重相同,未能有效响应学习进展。
表2和图4展示了所有方法在CC数据集上的表现。「CoBa在五种编程语言的Pass@1指标上表现优于基线方法,平均得分至少提高4%」 。此外,将FAMO、LBTW和GradNorm适配于验证损失(即、和)能有效提升性能,这一提升强调了根据验证损失来平衡收敛速度从而增强泛化能力的重要性。虽然的表现接近CoBa,但在Python补全任务中存在潜在的发散趋势(图4),影响了整体效果。相较之下,CoBa通过利用ACS和DF,有效地缓解了该问题。尽管GradNorm旨在以相同速度学习所有任务,但由于其采用相同且较小的学习率更新权重和模型参数,因此其性能仍落后于CoBa、FAMO和LBTW等方法。此策略在LLMs训练场景下表现不佳,导致GradNorm调整的权重几乎与初始的均匀权重相同,未能有效响应学习进展。
「下表4为,CRT数据集上Code Completion任务的实验结果」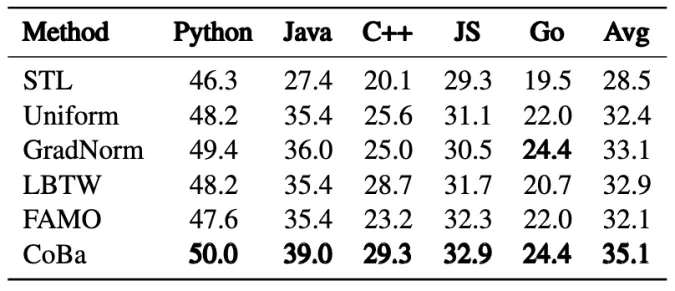 「下表5为CRT数据集上Unit Test生成任务的实验结果」
「下表5为CRT数据集上Unit Test生成任务的实验结果」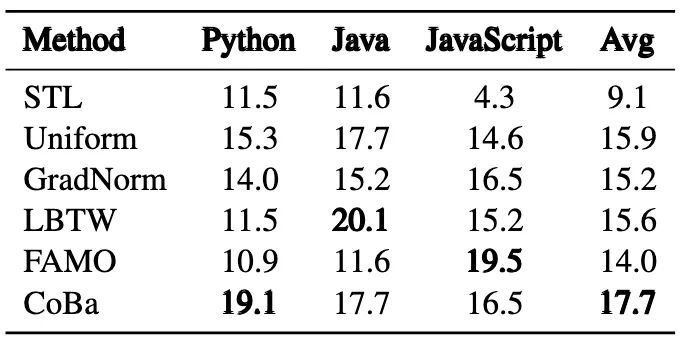 「下表6为,CRT数据集上Code Translation任务的实验结果」
「下表6为,CRT数据集上Code Translation任务的实验结果」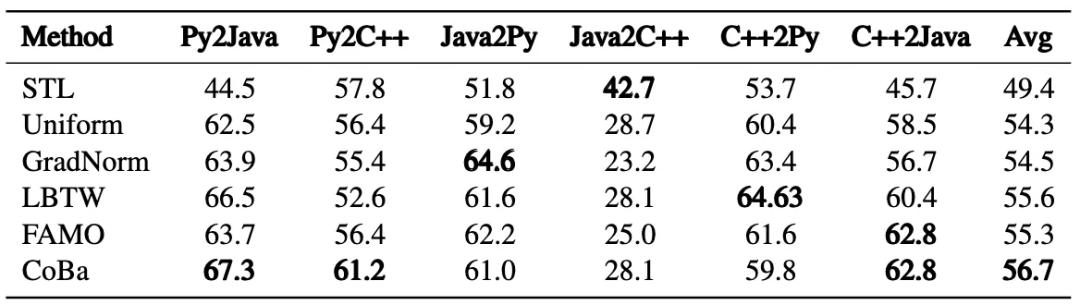 「下表7:CRT数据集上Code Comment任务的实验结果」
「下表7:CRT数据集上Code Comment任务的实验结果」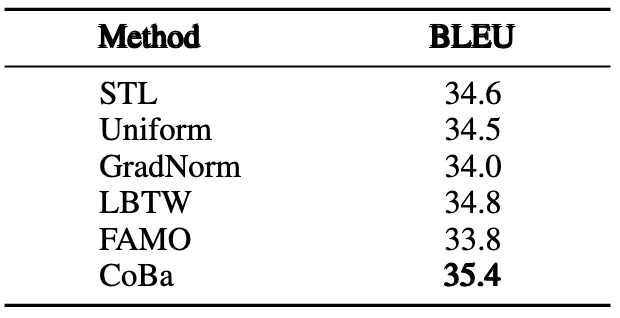 「下表8:CRT数据集上Text2Code任务的实验结果」
「下表8:CRT数据集上Text2Code任务的实验结果」 「下图5为CRT实验中5种任务的归一化验证损失收敛情况对比」
「下图5为CRT实验中5种任务的归一化验证损失收敛情况对比」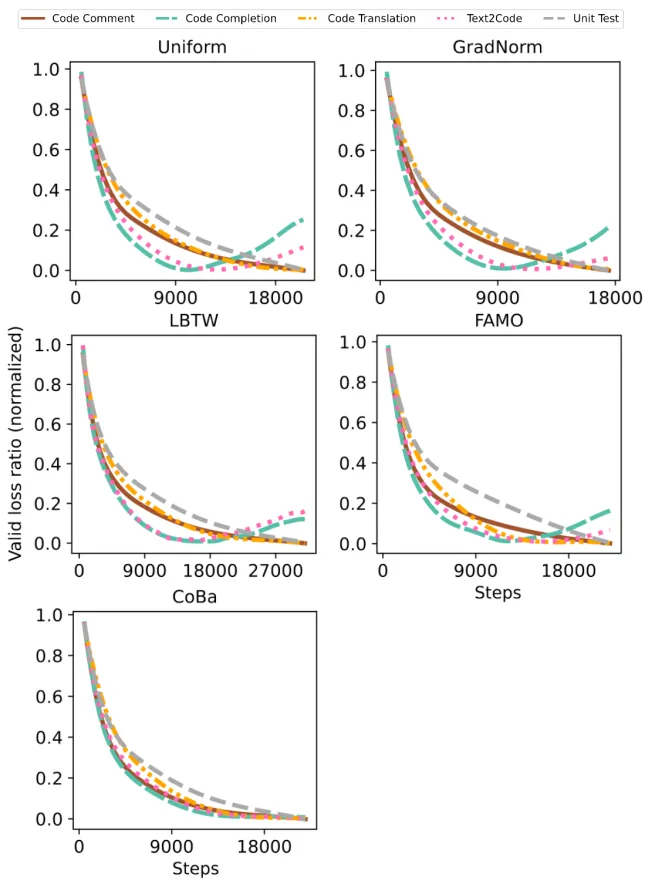 作者进一步探讨了所有方法在CRT数据集上的表现,这里的任务是按具体的代码需求划分的。实验结果表明,CoBa在几乎全部任务中均超越了所有SOTA方法,唯独在Text2Code任务中表现稍逊。特 「别是在代码补全和单元测试生成任务中,CoBa表现突出,分别实现了至少6%和13%的相对平均Pass@1提升。」 此外,图5显示CoBa不仅避免了在代码补全和Text2Code任务较早发散,还加快了其他任务的收敛,验证了了CoBa在实现收敛平衡和增强多任务学习能力方面的有效性。相反,GradNorm、LBTW和FAMO,在不同任务中的表现较不稳定,未能有效防止代码补全和Text2Code任务提前发散,凸显出了这些方法潜在的局限性。
作者进一步探讨了所有方法在CRT数据集上的表现,这里的任务是按具体的代码需求划分的。实验结果表明,CoBa在几乎全部任务中均超越了所有SOTA方法,唯独在Text2Code任务中表现稍逊。特 「别是在代码补全和单元测试生成任务中,CoBa表现突出,分别实现了至少6%和13%的相对平均Pass@1提升。」 此外,图5显示CoBa不仅避免了在代码补全和Text2Code任务较早发散,还加快了其他任务的收敛,验证了了CoBa在实现收敛平衡和增强多任务学习能力方面的有效性。相反,GradNorm、LBTW和FAMO,在不同任务中的表现较不稳定,未能有效防止代码补全和Text2Code任务提前发散,凸显出了这些方法潜在的局限性。
「下图6为XTREME-UP数据集的3任务设定实验结果」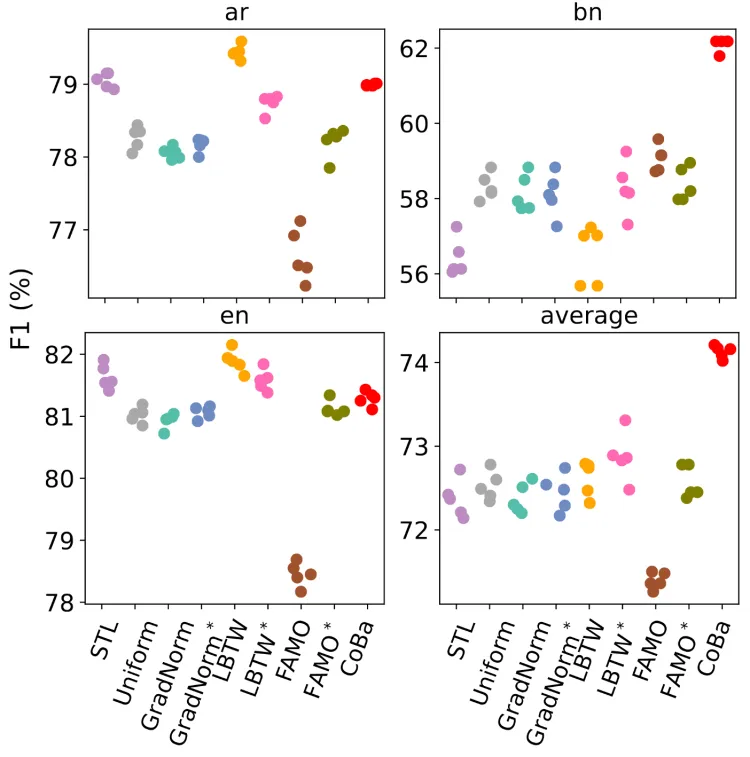 「下图7为XTREME-UP数据集的6任务设定实验结果」
「下图7为XTREME-UP数据集的6任务设定实验结果」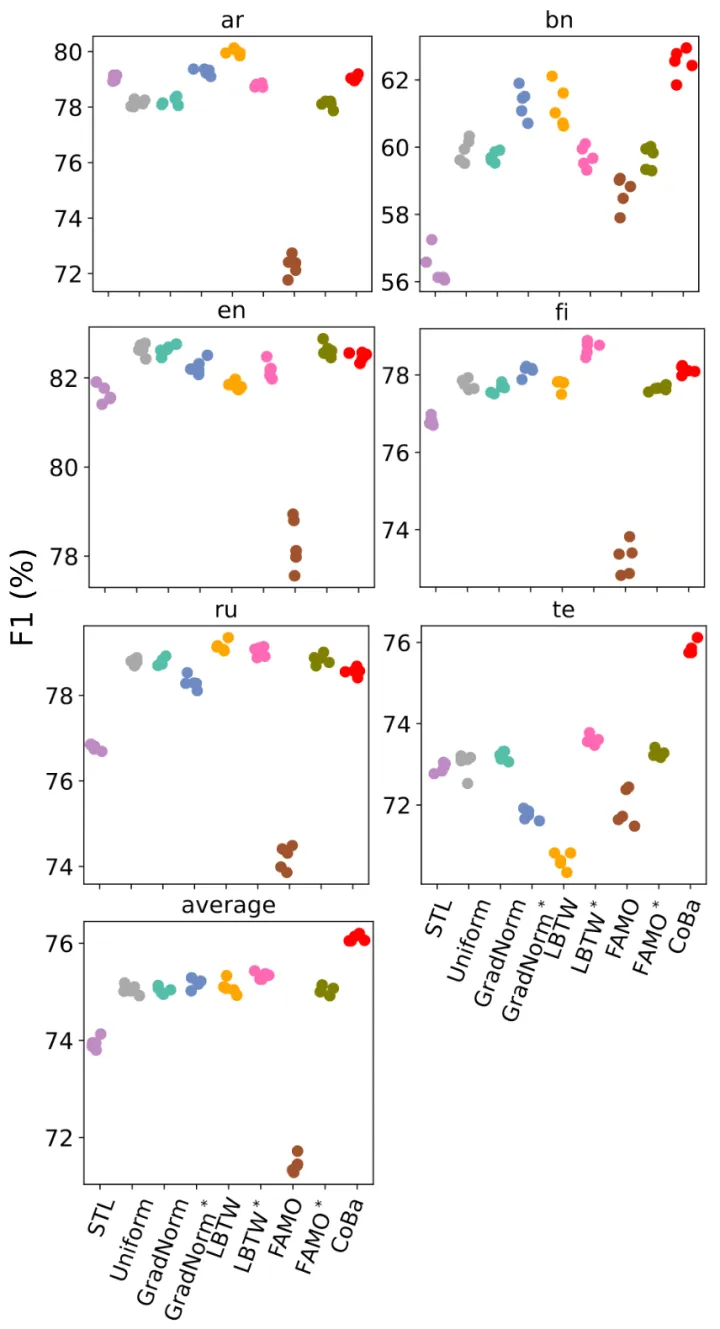 「下图8为XTREME-UP数据集的9任务设定实验结果」
「下图8为XTREME-UP数据集的9任务设定实验结果」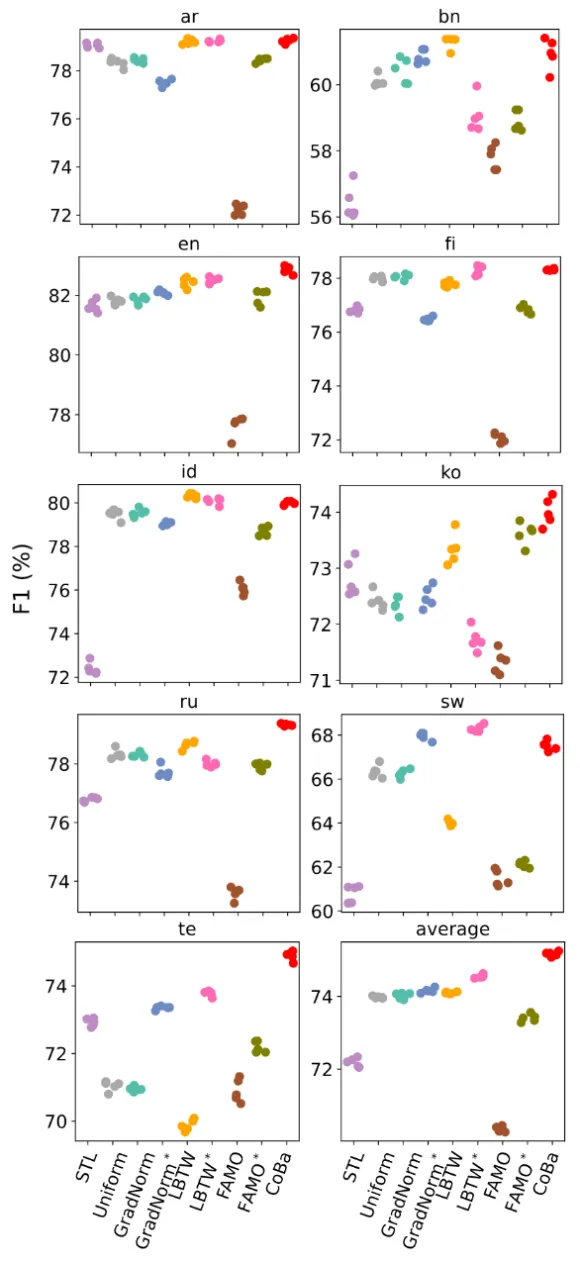 作者进行了三组实验,任务数量分别为3,6和9,混合高低资源语言。每组进行五次试验,以评估CoBa对于不同任务数量的适应能力,以及其对低资源语言的泛化能力。实验结果显示,「CoBa在所有条件下的平均分数均明显优于所有基线方法,且在任务数量变化时保持鲁棒性」。在低资源的孟加拉语(bn)和泰卢固语(te)任务中,CoBa的分数比STL提高了3%至5%,高资源语言中,CoBa的表现与STL持平或更好,这表明平衡收敛能够促进相关任务间的协同增益。
作者进行了三组实验,任务数量分别为3,6和9,混合高低资源语言。每组进行五次试验,以评估CoBa对于不同任务数量的适应能力,以及其对低资源语言的泛化能力。实验结果显示,「CoBa在所有条件下的平均分数均明显优于所有基线方法,且在任务数量变化时保持鲁棒性」。在低资源的孟加拉语(bn)和泰卢固语(te)任务中,CoBa的分数比STL提高了3%至5%,高资源语言中,CoBa的表现与STL持平或更好,这表明平衡收敛能够促进相关任务间的协同增益。
五、总结
作者提出了一种新颖的多任务学习方法CoBa,旨在为大语言模型(LLMs)实现同时满足多任务收敛平衡和低计算复杂度的微调训练。作者采用四个真实世界的数据集进行了大量实验,验证了CoBa的有效性和高效性。
六、最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









