



 Hadoop是一个用于处理结构化和半结构化数据的集群系统,包含分布式文件系统HDFS和MapReduce。HDFS通过数据块和副本提高容错性,但不适合低延迟访问和小文件存储。MapReduce则适用于大规模数据的离线批处理。YARN作为资源调度器,管理应用程序的资源分配,包括ResourceManager、NodeManager和ApplicationMaster。YARN通过Container进行任务的CPU、内存等资源管理。
Hadoop是一个用于处理结构化和半结构化数据的集群系统,包含分布式文件系统HDFS和MapReduce。HDFS通过数据块和副本提高容错性,但不适合低延迟访问和小文件存储。MapReduce则适用于大规模数据的离线批处理。YARN作为资源调度器,管理应用程序的资源分配,包括ResourceManager、NodeManager和ApplicationMaster。YARN通过Container进行任务的CPU、内存等资源管理。
Hadoop
处理结构化、半结构化数据应运而生的集群,包括HDFS
HDFS
分布式文件系统
hdfs将每一个文件的数据分成多个数据块,每个块默认128MB,将数据分开存储
将数据复制存储在不同的节点上(Q:那不是需要消耗更多的空间了吗?),以防止某个节点崩掉的时候其数据丢失
NameNode(NN):
- 负责客户端的响应
- 元数据(文件名称、副本数量、block存放的datanode的地址)的管理
DataNode(DN):
- 存储block块
- 定期向NN发送心跳信息,包括本身和所有block的信息,以及自身的健康状况(不健康NN就不让他放数据了)
机器集群,一个部署NN,其他每个部署一个DN
应用程序可以指定HDFS的block拷贝块的数量,叫做replication factoe(副本因子、副本系数)
HDFS不支持多并发写
HDFS优缺点
优点
- 高容错
- 批处理
- 适合大数据处理
- 可构建在廉价机器上
缺点
- 延迟高,不适合做低延迟的数据访问(文件比较大的话,分很多块,找得慢)
- 不适合小文件存储(namenode存储元数据的大小是固定的,文件太小太多的话,namenode就会占很多内存)
Mapreduce
分map和reduce
特点
- 用于大量数据的分布式处理
- 适合离线的批处理
- 时效性和延迟性很高
map是将数据映射在不同节点上,在不同数据节点上分别计算,最后reduce汇总
YARN
硬件资源调度,分配资源用的,可以将框架都放在一个集群中,靠yarn去分配
由以下部分组成
- 资源管理器(resource manager)
资源管理器任务:一个集群active的RM只有一个,负责整个集群的资源调度和管理
- 处理客户端的请求(启动/杀死)
启动/监控AM(一个任务对应一个AM)
监控NM
系统的资源分配和调度
- 节点管理器(node manager):处理并监控节点资源使用情况
NM的职责:整个集群由n个NM,负责单个节点的资源管理和调度,以及task的使用情况
- 定期向RM发送心跳信息(汇报本节点的资源使用请求和Container的运行状况)
- 接受、处理RM的对container的启停命令
- 应用管理器(application master)
AM:一个应用对应一个AM,负责应用程序的管理
- 数据切分
- 为应用程序向RM申请资源(最终跑在container中),并分配给内部任务
- 与NM通信,以启停task,task是运行在container中的
- task的监控和容错
- 容器(container):物质资源的集合
container:对任务CPU、memory、环境变量等的描述
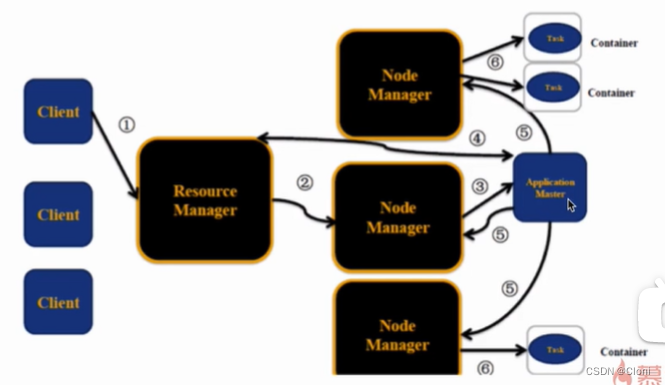
YARN调度过程
- client向yarn提交作业
- RM为任务分配第一个container(运行AM)
- RM与对应的NM通信,要求NM在这个container上启动任务程序的AM
- AM首先向RM注册,然后会为各个任务申请资源,并监控运行情况
- AM采用轮询的方式采用RPC协议向RM申请和领取资源
- AM申请到资源后,便向NM通信,要求NM启动任务
- NM启动我们任务对应的task
当要创建mapreduce任务时,应用管理器从节点管理器向容器发出资源请求,节点管理器获得资源后传给资源管理器,这样,yarn就可以处理作业请求并管理集群
其他
大数据技术栈
重点关注flink、spark、hive、hbase、zookeeper

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









