




 本文介绍了如何使用Python的BeautifulSoup库爬取天天基金网的基金净值数据。通过查看网页源代码,定位到目标数据所在的HTML结构,然后编写代码进行抓取。需要注意的是,由于静态网页中相同class名可能导致抓取到不需要的数据,需要额外处理。最后,文章展示了爬取结果并提及了输出CSV文件时可能出现的编码问题。
本文介绍了如何使用Python的BeautifulSoup库爬取天天基金网的基金净值数据。通过查看网页源代码,定位到目标数据所在的HTML结构,然后编写代码进行抓取。需要注意的是,由于静态网页中相同class名可能导致抓取到不需要的数据,需要额外处理。最后,文章展示了爬取结果并提及了输出CSV文件时可能出现的编码问题。
BeautifulSoup的使用
Python用来爬取网页数据是比较方便的,对于html格式的静态数据,使用python来获取数据效率很高。在PYTHON中,用的最多的爬取数据module就是beautifulsoup,下面就来详细介绍beautifulsoup的使用。
1.确认需要获取的数据对象
首先我们需要确认获取对象,这里我使用天天基金网的基金净值为例子:

黄色高亮是这次希望抓下来的数据,6.27的基金净值以及对应的基金symbol。
2.查看网页源(CTRL + U)
我们也可以右击然后点击inspect(ctrl+shift+i),由于现在很多网页时动态数据填写,往往inspect里面能看到的数据实际上是js填进去的,使用View page source可以看出来是静态网页还是动态网页(这里只介绍爬静态网页数据)。我们首先随意复制一个基金净值然后在代码源里搜索,如下图:
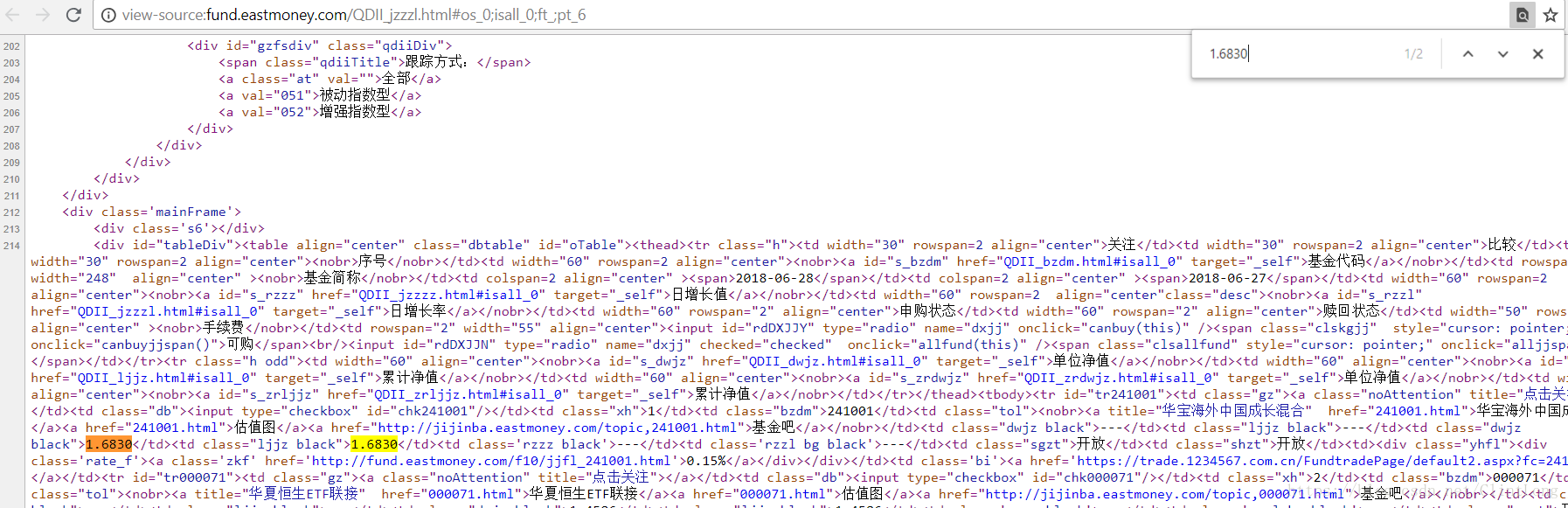
这个做法是为了锁定我们需要的数据在哪一块(如果稍微掌握一些h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









