







一、Python网络信息提取的方法技术介绍
1.1 requests库
1.1.1 requests库的安装与更新
当安装完python软件之后,一些网络信息的爬取需要安装各种相应的库。下面介绍requests库的安装:
1)点击键盘上的windows+R键,输入cmd,进入管理员窗口
2)输入pip intall requests命令,开始进行安装
3)安装完成后会提示successfully installed…
4)如果安装完成时出现warning警告,需要进行更新
5)输入python -m pip install --upgrade pip命令进行更新
1.1.2 request库的主要方法
requests.request() 构造一个请求,支撑以下各方法的基础方法
requests.get() 获取HTML网页的主要方法,对应于HTTP的GET
requests.head() 获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.patch() 向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.delete() 向HTML页面提交删除请求,对应于HTTP的DELETE
1.1.3 request库的两个重要对象
通过调用Request库中的方法,获取返回的对象。其中包括两个对象:request对象和response对象。request对象就是我们要请求的url链接,response对象是返回的内容。
response对象比Request对象更复杂,response对象包括以下属性:
属性 说明
r.status_code HTTP请求的返回状态,200表示连接成功,404表示失败
r.text HTTP响应内容的字符串形式,即,url对应的页面内容
r.encoding 从HTTPheader中猜测的响应内容编码方式
r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)
r.content HTTP响应内容的二进制形式
Requests库可能出现的异常如下:
异常 说明
requests.ConnectionError 网络连接错误异常,如DNS查询失败、拒绝连接等
requests.HTTPError HTTP 错误异常
requests.URLRequired URL 缺失异常
requests.TooManyRedirects 超过最大重定向次数,产生重定向异常
requests.ConnectTimeout 连接远程服务器超时异常
requests.Timeout 请求URL超时,产生超时异常
1.2 robots.txt协议
robots.txt是一个协议,而不是一个命令。它是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一些死链接。方便搜索引擎抓取网站内容;设置网站地图连接,方便引导蜘蛛爬取页面。
1.3 beautifulsoup库
Beautiful Soup库是解析、遍历、维护“标签树”的功能库。BeautifulSoup对应一个HTML/XML文档的全部内容。简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
主要的解析器如下:
1.4 Re表达式
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
Re正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;只要有匹配不成功的字符则匹配失败。
正则表达式可以包含普通字符和特殊字符,普通字符(比如数字或者字母)可以直接对目标字符串进行匹配,在本文中我们主要讨论利用特殊字符来模糊匹配某一些字符串的方法,比如’|‘或者’(’,使用这些特殊字符,正则表达式可以表示某一类的普通字符,或者是改变其周围的正则表达式的含义。
正则匹配的语法有以下几种:
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.split 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
re.fullmatch 全部匹配
1.5 Scrapy框架
Scrapy 是一个开源和协作的框架,其最初是为了网络抓取 所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据或者通用的网络爬虫。
主要命令:
创建项目:scrapy startproject xxx
进入项目:cd xxx #进入某个文件夹下
创建爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)
生成文件:scrapy crawl xxx -o xxx.json (生成某种类型的文件)
运行爬虫:scrapy crawl XXX
列出所有爬虫:scrapy list
获得配置信息:scrapy settings [options]
Scrapy五大核心组件介绍如下
1)引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
2)管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
3)调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
4)下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
5)爬虫文件(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
二、一个Python爬取网络信息的程序设计
2.1程序设计任务
编写程序实习对汽车之家的8月“轿车排行”实行网络数据爬取,输出前8名的排行的相关数据。
2.2设计流程

2.3设计代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return “”
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, “html.parser”)
for tr in soup.find(‘tbody’).children:
if isinstance(tr, bs4.element.Tag):
tds = tr(‘td’)
ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string,tds[4].string,tds[5].string])
def printUnivList(ulist, num):
tplt = “{:10}\t{:10}\t{:10}\t{:10}\t{:10}\t{:10}”
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],u[3],u[4],u[5],chr(12288)))
def main():
uinfo = []
url =‘http://www.crimoab.com/autorank_201408/’
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 9) # 20 univs
main()
三、设计实例的结果分析
实例结果如下:
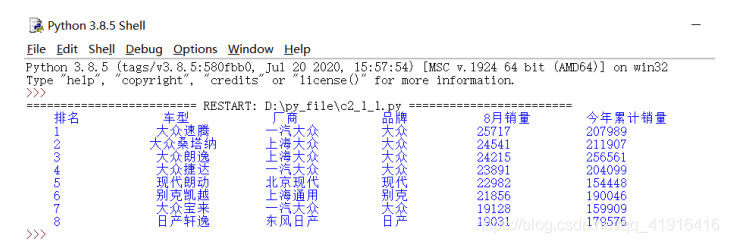
结果分析:
程序的设计要求是获取轿车排行前八名的相关数据,实质上就是获取网页中表格数据信息。由爬取的信息来看,大众速腾的8月销量最高,日产轩逸的8月销量相对较低;从品牌来看,大众的轿车销量相对来说比其他品牌的销量要高。从累计销量来看,大众汽车的累计销量都超过了20万,其他品牌的累计销量与大众品牌汽车比较相对较低。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









