




 本文介绍了KNN(K-nearest-neighbor)算法的基本原理和在R语言中的实现过程。通过数据预处理、标准化,利用rescale()函数处理不同范围的数据,然后在乳腺癌数据集上应用KNN算法,达到了超过95%的预测准确率。文章还探讨了模型精度与成本之间的权衡,并强调了数据质量对算法的重要性。
本文介绍了KNN(K-nearest-neighbor)算法的基本原理和在R语言中的实现过程。通过数据预处理、标准化,利用rescale()函数处理不同范围的数据,然后在乳腺癌数据集上应用KNN算法,达到了超过95%的预测准确率。文章还探讨了模型精度与成本之间的权衡,并强调了数据质量对算法的重要性。
本次需要使用到《机械学习与R语言》中的数据包‘wisc_bc_data.csv’。可以到网上自行搜索下载or到我github里下载:到第二版第三章,点进wisc_bc_data.csv -> 再点击 raw -> 右键另存为
本文代码多来源于《MACHINE LEARNING WITH R》- Brett Lantz
1.临近分类法(KNN)
KNN 算法是一个原理极其简单的算法,但是却在机械学习中广泛应用。所谓的算法,无非是一些通过实际从业者or研究人员思考出来以解决实际问题的方法,当这些方法被数学证明同时又被实践认同后,便会成为我们的流行的算法。算法并不是越复杂越好(即使很多时候它们内在的计算较为复杂or对于细节的取舍需求经验),实际上(在我看来)大道至简才是最好的算法和应用。 今天要聊到的KNN算法便是一个大道至简而应用较广的算法。
KNN(k-nearest-neighbor)只服务于数值型变量(也能服务character类型,但是需要做出相应调整),基本理念是,样本距离哪一类近,那么就会被归为哪一类。(我稍微解释一下吧...如果还不清楚建议google)如下图(来源网络):
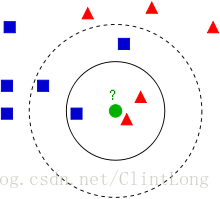
我们已经有了正方形和三角形很多样本,他们分布于空间之中,那么中间的圆如果要分类,那到底属于三角形还是正方形呢?KNN算法,如果把K取1,那么我们就只考虑和它最近的数据是哪一个类型(显然三角形近),这样子圆形最后会被算法判断为三角形。这个取值显然并不合理,这样子的分类会被极端值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1156
1156



 到【灌水乐园】发言
到【灌水乐园】发言







