 ClickHouse全新JSON数据类型解析
ClickHouse全新JSON数据类型解析






本文字数:8969;估计阅读时间:23 分钟
作者:Pavel Kruglov
本文在公众号【ClickHouseInc】首发

简介
JSON 已成为现代数据系统中处理半结构化和非结构化数据的首选格式。无论是在日志记录和可观测性 (observability) 应用场景、实时数据流、移动应用存储,还是机器学习管道中,JSON 以其灵活的结构,成为分布式系统中捕获和传输数据的标准格式。
在 ClickHouse,我们早已认识到无缝支持 JSON 的重要性。尽管 JSON 的结构看似简单,但要在大规模环境中高效使用它,却面临着独特的挑战。接下来,我们将简要介绍这些挑战。
挑战 1:真正的列存储
ClickHouse 是市场上最快的分析型数据库之一。要实现这样的性能水平,必须采用正确的数据组织方式。ClickHouse 作为真正的列存储数据库,将表格数据以列的形式存储在磁盘上。这样可以实现最佳的压缩效果,并通过硬件加速,快速执行向量化的列操作,如过滤和聚合。
为了让 JSON 数据也能达到同样的性能,我们需要为 JSON 实现真正的列存储方式,使 JSON 路径像数值类型等其他列类型一样,能够被高效压缩和处理(例如,向量化的过滤和聚合)。
因此,我们不想像下图所示的那样,将 JSON 文档直接存储到字符串列中,并在后续解析:

我们希望将每个唯一 JSON 路径的值以真正的列存储方式保存:

挑战 2:无需类型统一的动态数据处理
当我们能够以真正的列存储方式存储 JSON 路径后,下一个挑战是 JSON 允许相同的路径具有不同的数据类型。在 ClickHouse 中,这些不同的数据类型可能存在不兼容性,且在使用前无法预知。此外,我们需要找到一种方法来保留所有不同的数据类型,而不是将它们统一为最小共同类型。例如,如果某个 JSON 路径 a 的值是两个整数和一个浮点数,我们不希望将它们都存储为磁盘上的浮点数,如下图所示:

这种方法无法保留混合类型数据的原始特性,也无法支持更复杂的场景。例如,如果下次在相同路径 a 下存储的值是一个数组:

挑战 3:防止磁盘上列数据文件的过多增长
以真正的列存储方式保存 JSON 路径,在数据压缩和向量化处理方面确实有优势。然而,如果每当遇到新的唯一 JSON 路径时都创建一个新的列文件,可能会在含有大量唯一 JSON 键的场景中导致磁盘上产生过多的列文件:
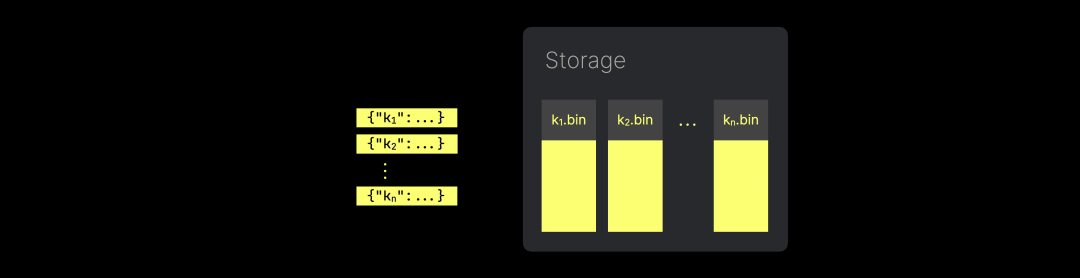
这会带来性能问题,因为需要使用大量的文件描述符来管理这些文件(每个文件描述符都占用一定的内存资源),并且由于需要处理的大量文件,合并操作的性能也会受到影响。因此,我们引入了列创建的限制,确保 JSON 存储可以有效扩展,支持 PB 级别数据集上的高性能分析。
挑战 4:密集存储
在包含大量唯一但稀疏 JSON 键的场景中,我们希望避免为那些在特定 JSON 路径上没有实际值的行,冗余存储或处理 NULL 或默认值,如下图所示:
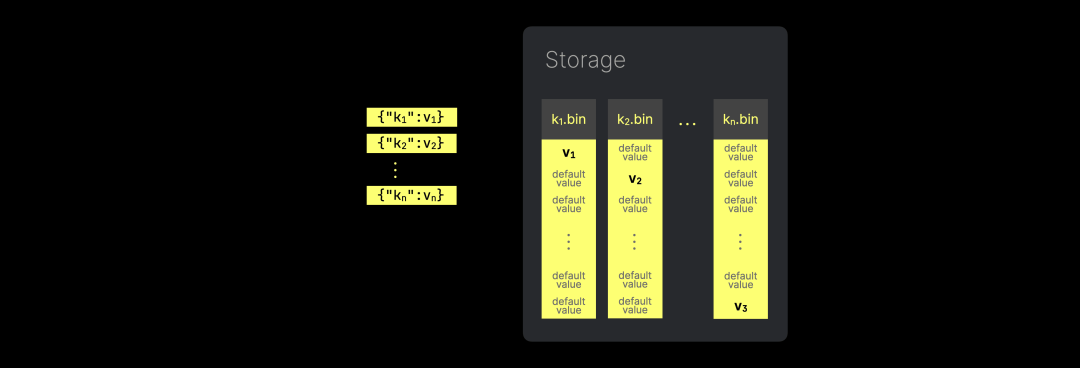
相反,我们希望以密集存储的方式保存每个唯一 JSON 路径的值,避免冗余。这同样能够让 JSON 存储扩展到 PB 级别数据集,并实现高性能的分析。
我们全新且极大增强的 JSON 数据类型
我们非常高兴推出全新升级的 JSON 数据类型,专为高性能处理 JSON 数据而设计,克服了传统实现中的性能瓶颈。
在这篇文章中,我们将详细介绍该功能的构建过程,解决了之前提到的所有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









