






本文字数:15291;估计阅读时间:39 分钟
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

Meetup活动
ClickHouse 上海首届 Meetup 讲师招募中,欢迎讲师在文末扫码报名!
引言
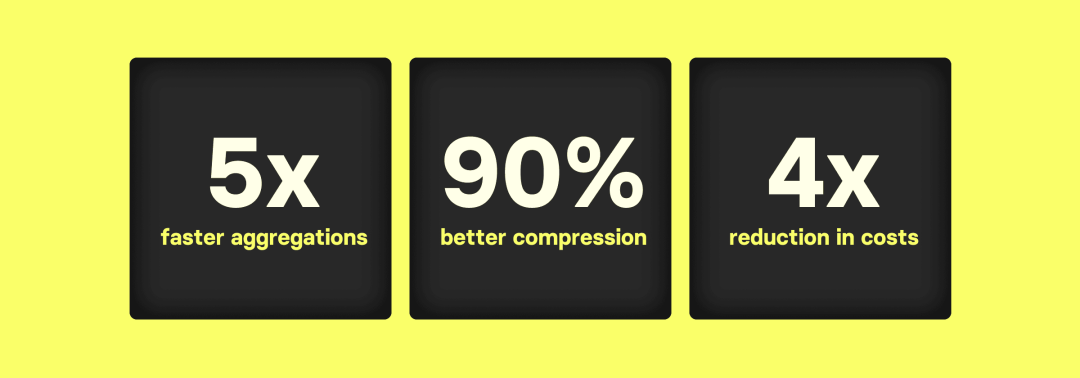
这篇博客探讨了在大规模数据分析和可观测性用例中,ClickHouse 与 Elasticsearch 在处理常见工作负载时的性能对比,特别是对数十亿行表的 count(*) 聚合。结果显示,ClickHouse 在处理大数据时的聚合查询性能显著优于 Elasticsearch。具体来说:
-
ClickHouse 的数据压缩效果远胜于 Elasticsearch,处理大数据集时,ClickHouse 需要的存储空间比 Elasticsearch 少 12 到 19 倍,因此可以使用更小、更便宜的硬件。

-
ClickHouse 中的 count(*) 聚合查询能够高效利用硬件资源,与 Elasticsearch 相比,ClickHouse 在大数据集聚合方面的延迟至少低 5 倍。
这意味着,在获得与 Elasticsearch 相同延迟的情况下,ClickHouse 需要的硬件规模更小,成本更低,具体来说便宜 4 倍。

-
ClickHouse 通过物化视图 (materialized views) 技术提供了更高效的存储和计算持续数据汇总,与 Elasticsearch 的转换 (transforms) 功能相比,进一步降低了计算和存储成本。

由于这些原因,我们越来越多地看到用户从 Elasticsearch 迁移到 ClickHouse,客户们强调:
-
在拍字节级别的可观测性用例中大幅降低成本:
“从 Elasticsearch 迁移到 ClickHouse 使我们的可观测性硬件成本降低了 30% 以上。”
——Didi Tech
-
克服数据分析应用的技术限制:
“这种迁移释放了新功能、增长和更容易扩展的潜力。”
——Contentsquare
-
监控平台的可扩展性和查询延迟显著改善:
“ClickHouse 帮助我们每月的数据量从数百万行扩展到数十亿行。”
“切换后,我们的平均读取延迟降低了 100 倍。”
——The Guild
在这篇文章中,我们将比较典型数据分析场景下的存储大小和 count() 聚合查询性能。为了适应博客的篇幅,我们将比较在单节点环境中独立运行 count() 聚合查询的大数据集性能。
博客的其余部分将首先解释我们为什么专注于基准测试 count() 聚合。然后我们会描述基准测试环境,解释我们的 count() 聚合性能测试查询和基准测试方法。最后,我们将展示基准测试结果。
在阅读基准测试结果时,您可能会想,“为什么 ClickHouse 这么快且高效?”简短的回答是对如何优化和并行化大规模数据存储和聚合执行的无数细节的关注。我们建议阅读《ClickHouse vs. Elasticsearch:Count 聚合的工作原理》一文,以获取该问题的深入技术答案。
ClickHouse 和 Elasticsearch 中的计数聚合
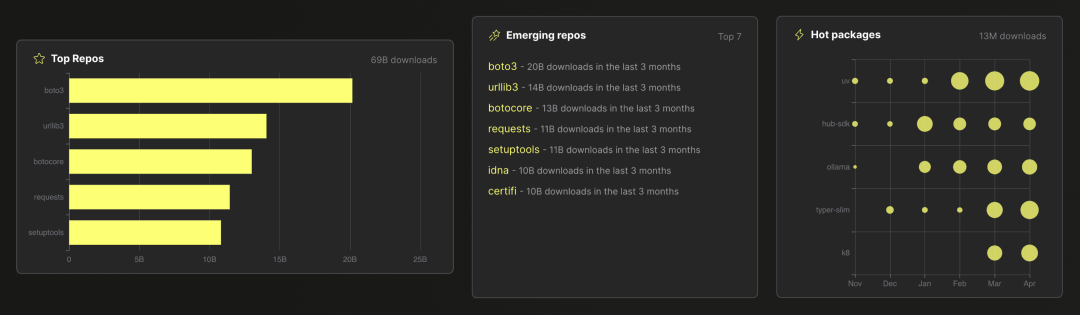
在数据分析场景中,聚合的一个常见用例是计算和排名数据集中值的频率。比如,ClickPy 应用程序的这个截图展示了所有数据可视化(分析了近 9000 亿行 Python 包下载事件),后台都使用了结合 count(*) 聚合的 SQL GROUP BY 子句:
同样地,在日志应用场景(或更广泛的可观测性应用场景)中,聚合最常见的应用之一是计算特定日志消息或事件发生的频率(并在频率异常时发出警报)。
在 Elasticsearch 中,等效于 ClickHouse 的 SELECT count(*) FROM ... GROUP BY ... SQL 查询的是 terms 聚合,这是一种 Elasticsearch 桶聚合 (bucket aggregation)。
我们在另一篇博客文章中描述了 Elasticsearch 和 ClickHouse 如何在后台处理这种计数聚合。在这篇文章中,我们将比较这些 count(*) 聚合的性能。
基准测试设置
数据
我们将使用公共的 PyPI 下载统计数据集。这个数据集不断增加,每一行都代表用户下载一个 Python 包(使用 pip 或类似技术)。去年,我的同事 Dale 构建了基于该数据集的分析应用程序,实时分析了近 9000 亿行数据(截至 2024 年 5 月),由 ClickHouse 聚合驱动。
我们使用了一个在公共 GCS 存储桶中托管为 Parquet 文件的版本。
从这个存储桶中,我们将加载 1、10 和 100* 亿行数据到 Elasticsearch 和 ClickHouse 中,以基准测试典型数据分析查询的性能。
*我们无法将 1000 亿行数据加载到 Elasticsearch 中。
硬件
这篇博客主要关注单节点数据分析性能。我们将多节点设置的基准测试留待未来的博客讨论。
我们为 Elasticsearch 和 ClickHouse 都使用了一个专用的 AWS c6a.8xlarge 实例。该实例具有 32 个 CPU 核心,64 GB RAM,本地附加 SSD(具有 16k IOPS),操作系统为 Ubuntu Linux。
另外,我们还比较了 ClickHouse Cloud 服务的性能,该服务节点在 CPU 核心数和 RAM 方面具有类似规格。
数据加载设置
我们从 GCS 存储桶中托管的 Parquet 文件中加载数据:
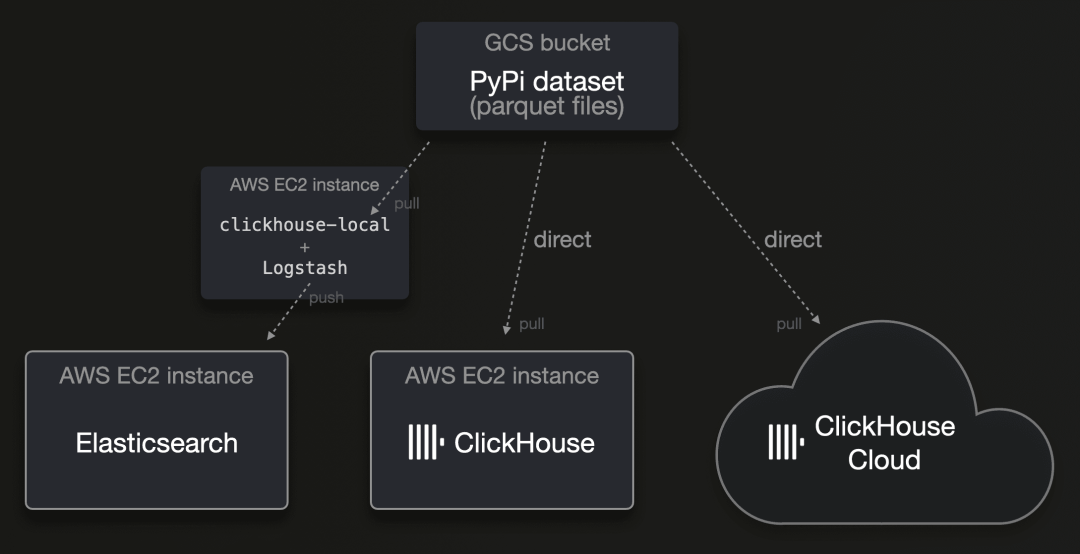
到 2024 年,Parquet 正日益成为分发分析数据的普遍标准。虽然 ClickHouse 开箱即支持这种格式,但 Elasticsearch 没有对这种文件格式的原生支持。其推荐的 ETL 工具 Logstash 也在撰写本文时不支持这种文件格式。
Elasticsearch
为了将数据加载到 Elasticsearch 中,我们使用了 clickhouse-local 和 Logstash。clickhouse-local 是将 ClickHouse 数据库引擎转换成的(极快的)命令行工具。ClickHouse 数据库引擎原生支持 90 多种文件格式,并提供 50 多种集成表函数和引擎,用于与外部系统和存储位置连接,这意味着它可以开箱即用并高度并行地读取或拉取几乎任何数据源中的几乎任何格式的数据。因为 ClickHouse 是关系型数据库引擎,我们可以利用 SQL 提供的所有功能,在将数据发送到 Logstash 之前,使用 clickhouse-local 动态过滤、丰富和转换这些数据。下图是用于 Logstash 的配置文件和将数据加载到 Elasticsearch 的命令行调用。
我们本可以使用 ClickHouse 的 url 表函数通过 clickhouse-local 将数据直接发送到 Elasticsearch 的 REST API。然而,Logstash 允许更容易地调整批处理和并行性设置,支持将数据发送到多个输出(例如,具有不同设置的多个 Elasticsearch 数据流),并且具有内置的弹性,包括反压和对失败批次的重试,具有中间缓冲和死信队列。
ClickHouse
如上所述,因为 ClickHouse 能够原生读取大多数云提供商的对象存储桶中的 Parquet 文件,我们只需使用这个 SQL 插入语句将数据加载到 ClickHouse 和 ClickHouse Cloud 中。对于 ClickHouse Cloud,我们通过利用所有服务节点来进一步提高并行度来加载数据。
我们没有尝试优化摄取吞吐量,因为这篇博客并不是为了比较 ClickHouse 和 Elasticsearch 的摄取吞吐量。我们将这留待未来的博客讨论。话虽如此,通过我们的测试,我们发现即使对 Logstash 的批处理和并行性设置进行了一些调整,Elasticsearch 加载数据的时间仍显著更长。当我们尝试加载 1000 亿行数据集时,它花费了 4 天时间加载了大约 300 亿行数据,我们计划为 Elasticsearch 包含基准测试结果,但未能成功加载如此大量的数据。而我们的 ClickHouse 实例则用显著更少的时间(不到一天)加载了完整的 1000 亿行数据集。
Elasticsearch 设置
Elasticsearch 配置
我们在一台机器上安装了 Elasticsearch 版本 8.12.2(GE
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2246
2246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









