





本文字数:13159;估计阅读时间:33 分钟
作者:Tom Schreiber
本文在公众号【ClickHouselnc】首发

简要摘要:ClickHouse 天然适配 Parquet 格式。Parquet 是 Apache Iceberg 和 Delta Lake 等开放表格式背后的核心存储形式,ClickHouse 多年来持续针对其进行了深入优化。
本文将深入解析 ClickHouse 查询引擎的内部机制,展示其如何无需数据导入即可直接查询 Parquet 文件,并且查询性能往往超过很多系统在自有格式下的表现。我们还将介绍未来的一些优化方向。
这是我们新系列的开篇文章,聚焦 ClickHouse 如何从底层能力出发,构建起高性能的 Lakehouse 分析能力。
值得提前指出的是:ClickHouse 并不是“正在为 Lakehouse 做准备”,它早已准备就绪。
从偶然到有意:为 Lakehouse 而生的引擎
有时候,技术的发展方向恰好与既有路径不谋而合。
尽管 ClickHouse 的设计初衷并非为 Lakehouse 架构服务(当 Iceberg 和 Delta Lake 出现时,ClickHouse 已是一个成熟的数据库系统),但它恰好拥有高度契合的能力。ClickHouse 对 Parquet 提供一等支持,并支持直接查询文件格式,早已原生支持了许多 Lakehouse 模式。
ClickHouse 查询引擎始终将“支持多种格式、支持远程位置的数据访问”视为核心功能。无论是先导入再查询,还是直接查询外部数据,这种灵活性是 ClickHouse 一贯的优势。
如今所谓的 Lakehouse 架构,其核心理念——任意部署、任意查询、灵活访问数据——正是 ClickHouse 多年来不断强化的能力体现:
任意部署:ClickHouse 引擎可灵活部署于本地服务器、云平台、独立模式,甚至嵌入式运行环境中。
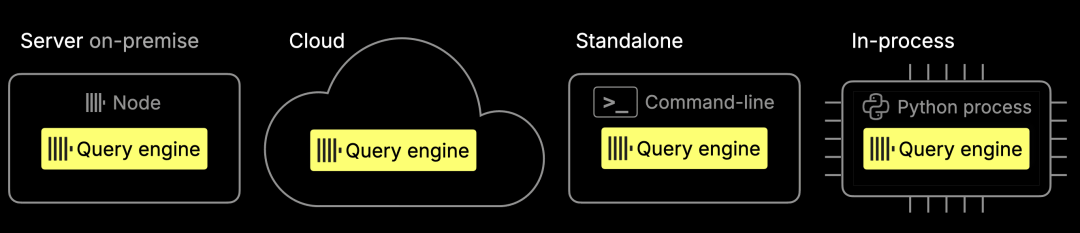
任意查询:除了为 MergeTree 原生表格式进行了极致优化,ClickHouse 还能直接查询外部格式,无需预先导入。大多数数据库在运行查询前都必须将 Parquet 等文件加载转换为内部格式,而 ClickHouse 可以跳过这个步骤。查询引擎原生支持超过 70 种文件格式,并提供完整 SQL 功能:包括 JOIN、窗口函数和 160 多种聚合函数,均可在原始文件上直接执行。支持的格式包括 Parquet、JSON、CSV、Arrow 等。

灵活访问数据:ClickHouse 提供 80 多种内置集成,可与各种外部系统和对象存储平台无缝连接,例如 S3、GCP、Azure 等。
这些能力使 ClickHouse 成为 Lakehouse 场景的理想技术基础。ClickHouse 能够直接查询存储在对象存储上的 Apache Iceberg 表,这些表大多采用 Parquet 格式保存数据。
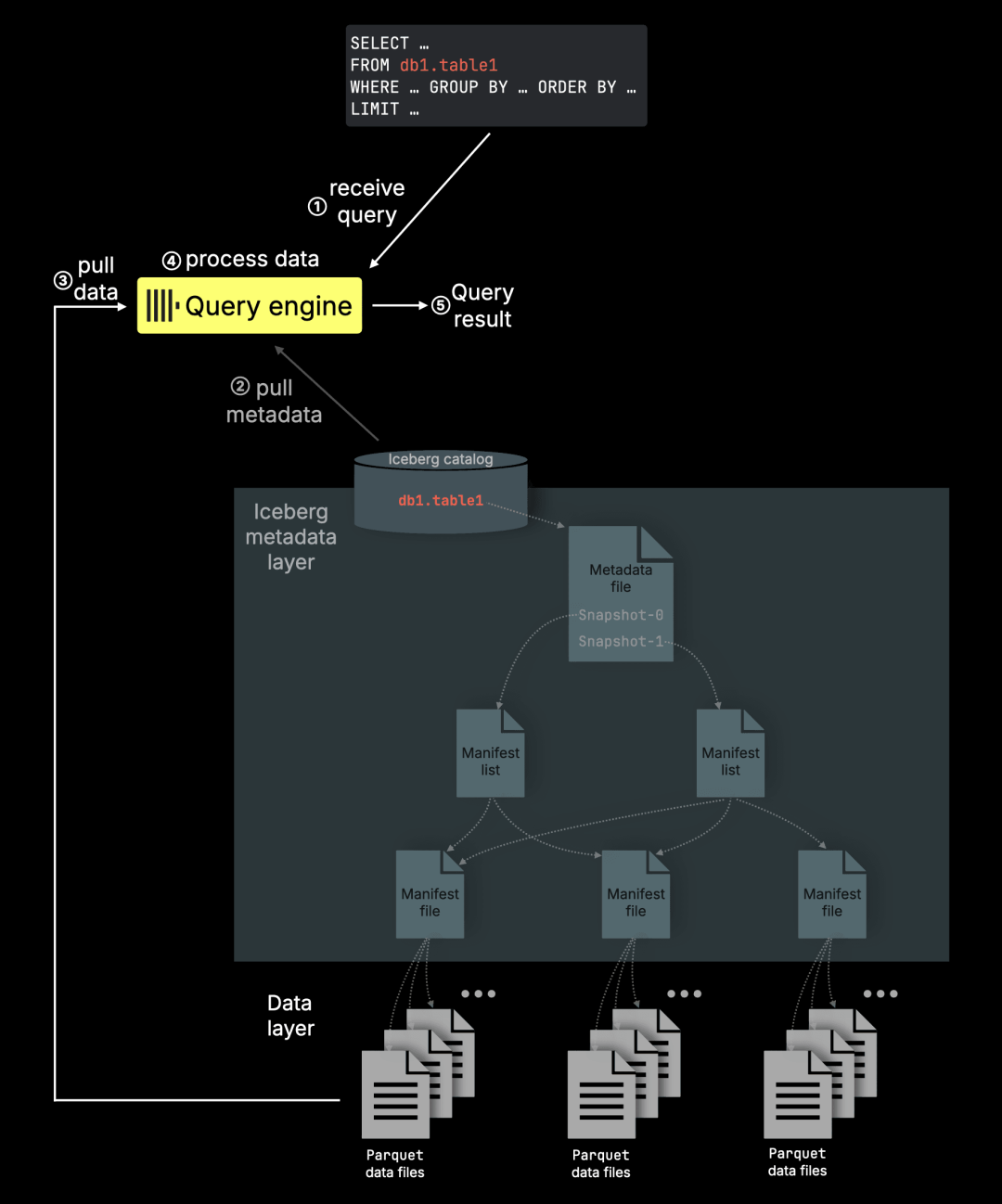
同时,ClickHouse 查询引擎支持多种运行模式,可灵活部署在各种场景中:无论是靠近对象存储的计算节点、多租户 SaaS 系统内部、嵌入在使用 pandas 的 Jupyter Notebook 中,还是作为无状态函数运行于 AWS Lambda 环境中,都可以胜任。
引擎剖析:ClickHouse 如何高效查询 Parquet 文件
本文将深入介绍 ClickHouse 如何处理 Lakehouse 架构中关键的数据存储格式之一:Parquet。
-
ClickHouse 目前查询 Parquet 文件的性能究竟如何?
-
与其原生的 MergeTree 表相比表现如何?
-
在 ClickHouse 支持的 70 多种外部格式中,还有哪些更快的选择?
-
未来还有哪些优化方向?
这些问题将在本文中一一解答。文章也开启了一个全新系列,聚焦 ClickHouse 作为高性能 Lakehouse 引擎的技术演进。本篇将从基础的数据格式 Parquet 入手,该格式正是 Apache Iceberg 和 Delta Lake 等开放表格式的底层支撑。
我们将先解析当前版本中 Parquet 读取器的实现机制,并探讨其性能优势。随后,我们将在真实分析场景中对其进行基准测试,展示当前表现,并预告未来的改进方向。
正如前文所述,ClickHouse 查询引擎支持直接查询包括 Parquet 在内的 70 多种文件格式,完全无需预先导入数据。针对不同格式的读取器可以作为插件集成进引擎,工作流程如下:
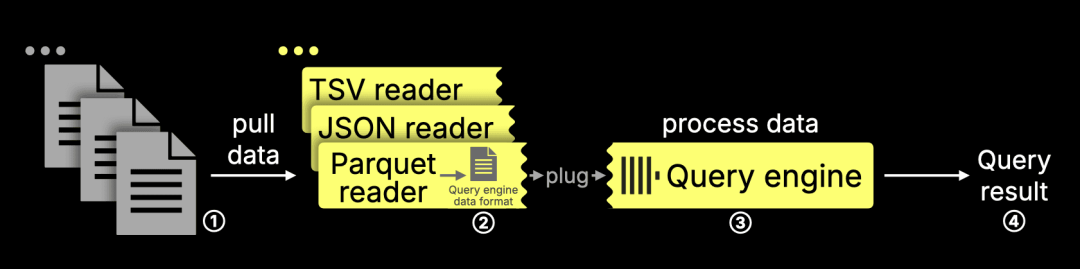
1. 读取器读取外部文件并解析内容;
2. 将解析后的数据转换为 ClickHouse 的内存格式;
3. 查询引擎对其执行查询逻辑;
4. 输出最终结果。
本节将重点聚焦 Parquet 读取器,它与 ClickHouse 查询引擎的协同,是实现高性能文件查询的核心组件。
当前 Parquet 读取器的机制与演进方向
值得一提的是,虽然 MergeTree 依然是 ClickHouse 的原生表引擎,但我们早在三年前就已着手优化对 Parquet 的支持。这一努力旨在将 ClickHouse 打造为全球最快的 Parquet 查询引擎。
目前的 Parquet 读取器使用 Arrow 库将文件解析为 Arrow 格式,再转换为 ClickHouse 的原生内存格式,以供执行查询。在下文中,我们将具体分析这一实现的能力边界。
一个全新的原生 Parquet 读取器正在开发中,目标是完全移除 Arrow 中间层,直接将文件加载进 ClickHouse 内存结构。同时,该实现将带来更强的并行性和更高的 I/O 效率。项目名称是 “Yet Another Parquet Reader”(YAPR)——顾名思义,这是 ClickHouse 的第三代 Parquet 读取器。第一代(input_format_parquet_use_native_reader)未完成;第二代(v2)虽有 Pull Request,但未正式上线;而第三代 v3 正在积极推进中。
我们本可以等新版本完成后再发布本篇文章,但当前版本的基准测试为后续性能对比提供了可靠的参考基线。在后续的文章中,我们将重点展示新读取器带来的提升。
当
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









