







 本文介绍了CRL(Cascade Residual Learning)方法,它改进了DispNetC,通过反卷积模块产生全分辨率的视差图。级联的两个阶段, DispFulNet和DispResNet,分别产生初始视差和残差信号,以逐步提高精度。第二阶段的网络专注于学习高度非线性的残差,以优化第一阶段的预测。整个网络结构允许端到端的训练,提高立体匹配的准确性。
本文介绍了CRL(Cascade Residual Learning)方法,它改进了DispNetC,通过反卷积模块产生全分辨率的视差图。级联的两个阶段, DispFulNet和DispResNet,分别产生初始视差和残差信号,以逐步提高精度。第二阶段的网络专注于学习高度非线性的残差,以优化第一阶段的预测。整个网络结构允许端到端的训练,提高立体匹配的准确性。
Cascade Residual Learning级联残差学习
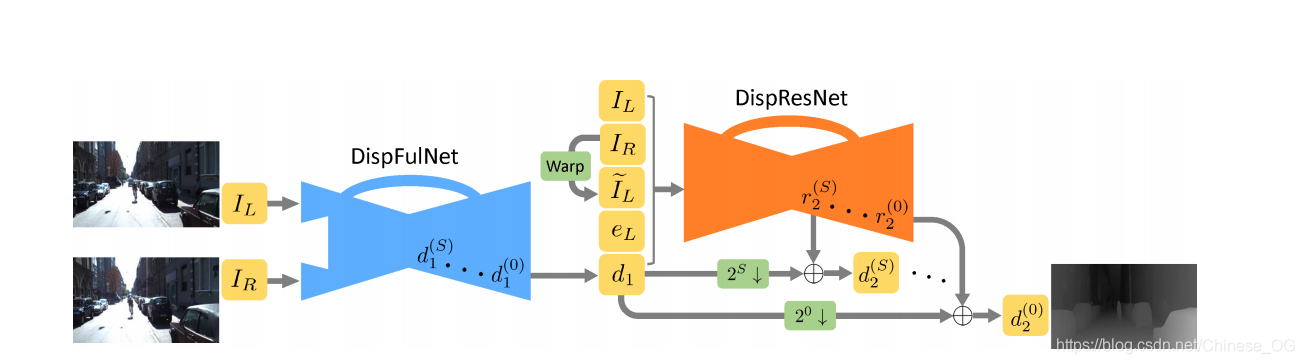
与DispNetC类似,本论文提出的CNN的第一阶段有一个带跳跃连接的沙漏结构。然而,DispNetC输出输入立体图像的半分辨率视差图像。而本论文的网络利用了额外的反卷积模块来放大视差,因此获得与输入图像具有相同尺寸的视差图。第一阶段的网络叫做DispFulNet(Ful表示全分辨率)。DispFulNet在目标的边界提供额外的细节和尖锐的转变,为第二阶段的精细化提供了一个理想的起点。
在本来论文的网络中,第一阶段和第二阶段的堆叠方式同FlowNet2.0。第一个网络输入立体图像对IL和IRIL和IR,产生左图的初始视差d1d1。然后根据视差d1d1扭曲右图像IRIR,获得一个合成的左图像,即
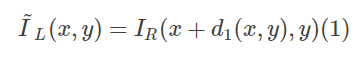
然后第二个网络的输入的是concat
IL,IR,d1,I˜L(x,y)和eL=|IL−I˜L(x,y)|IL,IR,d1,I~L(x,y)和eL=|IL−I~L(x,y)|.扭曲操作是可微的双线性插值,使得网络可以端到端训练。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









