 从0学大模型:理解prompt工程
从0学大模型:理解prompt工程




提示词工程原理
N-gram:通过统计,计算N个词共同出现的概率,从而预测下一个词是什么。
深度学习模型:有多层神经网络组成,可以自动从数据中学习特征,让模型通过不断地自我学习不断成长,直到模型的反馈内容符合我们的预期。
如何编写提示词
提示词(prompt)
是指在使用大模型时,向型提供的一些指令或问题。这些指令作为模型的输入,引导模型产生所需要的输出。例如,在生成文本时,Prompt可能是一个问题或者一个句子开始的部分,模型需要根据这个提示来生成接下来的内容。简单来说,在使用大模型时,我们输入的内容,不管是问题,还是直接输入一个文件,都属于提示词。
使用提示词时出现偏差(准确性,相关性,偏见性)的原因
1、模型自身的问题:由于模型是根据训练数据来学习的,如果训练数据存在偏见或质量问题,那么模型生成的内容也可能会受到这些问题的影响。此外,模型有时也会产生与提示不相关的内容,或者理解不准确,从而导致输出结果的质量下降。
2、使用者问题:提问没有明显的逻辑结构,缺乏系统性,依赖个人经验,没有方法,只有语法;分享给别人时,在没有沟通过或者一起了解过相关项目内容时无法理解,也无法对其进行有效的修改;没有学习过如何编写有效的提示词。
prompt工程
旨在获取这些提示并帮助模型在其输出中实现高准确度和相关性,掌握提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。特别地,矢量数据库(以数字的方式将知识存储起来,比如把“苹果”变成[0,1,4,5,...],能帮助大模型在搜索知识时可以快速找到类似的内容,因为其保存的数字结构是类似的)、agent和promptpipeline (把简单提问加工成模型能看懂的“超级提示词”,类似于在输出反馈内容之前“打了个小抄”,让模型能够更好理解词语,比如提问“讲个笑话”,系统会自动加工为“你是个喜剧大师,用中文讲个关于程序员的冷笑话,不超过3句话”)已经被用作在对话中,作为向 LLM 提供相关上下文数据的途径。
编写prompt工程的注意点
Prompt格式:确定prompt的结构和格式,例如,问题形式、述形式、关键词形式等。
Prompt内容:选择合适的词语、短语或问题,以确保模型理解用户的意图。
Prompt上下文:考虑前文或上下文信息,以确保模型的回应与先前的对话或情境相关。
Prompt编写技巧:使用清晰、简洁和明了的语言编写prompt,以准确传达用户的需求。
Prompt优化:在尝试不同prompt后,根据结果对prompt进行调整和优化,以获得更满意的回应。
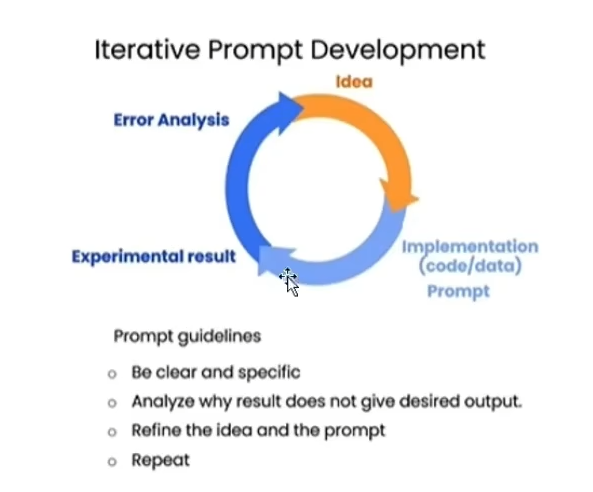
prompt工程的编写过程
Prompt 工程 的过程和机器学习的过程类似,都需要经过选代的过程。“从一个想法出发,通过一个基础的实现,在接近真实数据的测试集合上完成验证,分析失败的case;不断重复这个过程,直到100%满足的你的场景。
构建prompt的原则
1、清晰和明确的指令:模型的提示词需要清晰明确,避免模糊性和歧义。清晰性意味着提示词要直接表达出想要模型执行的任务,比如“生成一篇关于气候变化影响的文章”,而不是仅仅说“写一篇文章”。明确性则是指要具体说明任务的细节比如文章的风格、长度、包含的关键点等。这样,模型就可以更精确地理解任务要求,并产生与之相匹配的输出。
2、给模型思考的时间:这里的“时间”是比喻性的,意味着应该给模型足够的信息,让它能够基于充足的上下文来产生回应。这可能涉及到提供额外的描述,或者在复杂任务中分步骤给信息去引导模型。
在实践中,我们可以通过提供背景信息、上下文环境、以及相关细节来实现。例如,如果我们要模型续写一篇故事,可以先提供故事的背景信息人物关系和已发生的事件等,让模型有足够的“思考时间”,从而能够在现有信息的基础上进行合理的创作。而另一类实践场景,则是我们要充分引导大模型的思考路径,让模型沿着正确的道路得出正确的答案,即分步骤引导大模型思考。
prompt结构
一般来说,我们写的prompt要有背景(比如我的角色或身份是什么,我掌握了什么知识,我要完成什么任务),思考过程(一共要分为哪几个步骤去做,在这个过程中应该对每个步骤进行评估或者需要往哪个方向思考答案,并给出一个示例)和数据(可以是句子,简单的提问或者是文件或文章),输出的方式在没有硬性要求下一般都是以文本的形式进行输出,你也可以要求以json的格式(有时候存在输出的内容是要被拿取给后端使用的,以json的格式可以让后端接口直接使用)输出内容。
学习来源于B站教程:【基础篇】02.提示词深度讲解_哔哩哔哩_bilibili


















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









