 深入理解算法复杂度
深入理解算法复杂度




谈谈你对数据结构的理解? 能够举例说明吗?它是用来干啥的?
数据本身是杂乱无章的,需要结构进行增删查改等操作更好的管理数据;
比如:在程序中需要将大量的代码(数据)通过结构进行管理;
再比如:定义1000个整型变量的数组,我们可以对数组进行删除某一个数据,在某一个数据后面插入新的数据等等操作。这些都是结构管理数据的体现。
数据结构是用来在计算机中存储和管理数据的,这种存储和管理的方式有很多种,我们后面会一一学到比如:数组、线性表、树、图、哈希表等
数组是最基础的数据结构;
算法是什么?请使用打比方的形式描述下它与数据结构的关系?
算法是一个良好计算的过程,我们可以将数据结构作为放着数据的容器,而算法就是用来如何才能让我们良好的从容器中获取和管理数据的这么一个过程就叫做算法
因此:有数据结构的地方就有算法,数据结构和算法不分家
算法重要性
在笔试和面试中是必考的,是以编程题的形式进行考察,我们要好好磨砺算法,做到手撕代码 <:
学好算法秘籍:
1.死磕代码
2.遇到算法题莫慌,带着思考进行画图。
3.看关于算法和数据结构的书藉
4.使用各大OJ平台进行刷题(用OJ平台刷题的魅力:只需要写入内部的逻辑代码即可,其他的平台都已经定义好了)
用什么来衡量算法的好坏呢?
用复杂度进行衡量
复杂度包含哪两种,它们各自衡量算法的什么?
而复杂度又包含时间复杂度和空间复杂度
时间复杂度主要衡量一个算法的运行快慢;
空间复杂度主要衡量一个算法运行所需要的额外空间
随着时代的发展,我们对空间的关注已经不是大头了,时间才是,注意不是不关注!(也就是摩尔定律)
谈谈你对这两种复杂度理解?
时间复杂度理解
时间复杂度是一个函数表达式T(N),这个与数学中的定义的一次函数和二次函数是一样的,它是用来衡量程序的运行效率。它是一个粗估的值,不是精确的值。
为什么不去计算程序的运行时间呢?
1.因为程序的运行时间和编译环境和运行机器的配置都有关系,
比如:同一个算法程序,用一个老的编译器进行编译和新的编译器编译,在同样的运行机器下程序运行时间不同
2.同一个算法程序,在不同的运行机器下(在一个老低配置机器和新高配置机器的情况下)使用同一个编译器进行编译,程序运行时间也会不一样
3. 并且计算程序的运行时间只能在程序运行之后才能知道,不能在程序运行之前就知道大概的运行时间是多少。
总结:程序的运行时间是不确定的
既然程序的运行时间不确定,那时间复杂度T(N)到底怎么去计算呢?
T(N) = 每条语句的运行时间 * 运行次数
前面我们知道运行时间是不确定的,所以将运行时间去掉,所以
T(N) = 程序的运行次数
请计算下面的时间复杂度,并用你自己的话讲出来它的计算过程?

内层循环控制外层循环,所以是N^2,后面的计算正常算就行
这个程序的时间复杂度T(N) = N^2 + 2N + 10
因为2N + 10 对时间复杂度的影响很小,所以忽略不计,最终:T(N) = N^2
因此,对于时间复杂度来说,是一个粗估的值,争对这种情况,我们有了大O的渐进表示法的计算法则进行计算
说说什么是大O的渐进表示法,它对时间和空间都适用吗?
大O的计算规则:
- 时间复杂度T(N) 中,只保留最高项,去掉最低项,包括常数项
- 如果最高项的常数系数存在且不是1,则去除这个项目的常数系数
- 如果T(N) 中只有常数项,用常数1代表所有的加法常数。 O(1)来表示
如何判断它是高阶项呢?
对结果影响最大就是高阶项
大O的渐进表示法在空间和时间上都可以用
以下是常见时间复杂度的计算,用自己的话来讲它们是如何计算的,计算的过程中用到了那些大O渐进表示法?

T(N) = 2N + 10 根据法则2:O(N)

T(N) 中存在两个变量,不确定这两个变量的大小,如何计算它的时间复杂度呢?(需要分类讨论)
O(M + N), M 和 N 都是变量,具体看题目中是如何定义M和N 的大小,比如:M >> N, 则为O(M),反之则为O(N);再有一种情况就是M == N, 则为O(M+N)。

T(N) = 100, 根据法则3:O(1)
说说查找字符长度的时间复杂度是如何计算的?(需要分类讨论)

这里T(N) 的大小取决于你所要查找的位置,
比如:
查找的字符的位置在最后一个位置,则为O(N)
查找的字符的位置在第一个位置,则为O(1)
查找的字符的位置在中间位置,则为O(1/2 * N) = O(N)
最好情况: O(1)
最坏情况: O(N)
平均情况: O(N)
通过这个案例,算法的时间复杂度存在哪几种情况并简单说明下它的定义?我们常常关注的情况是哪一种叫什么?
总结 通过上面我们会发现,有些算法的时间复杂度存在最好、平均和最坏情况。 最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
大O的渐进表示法在实际中一般情况关注的是算法的上界,也就是最坏运行情况。
再看看冒泡排序的时间复杂度:
这里的内层和外层分别是啥?我们计算时计算的是什么层?
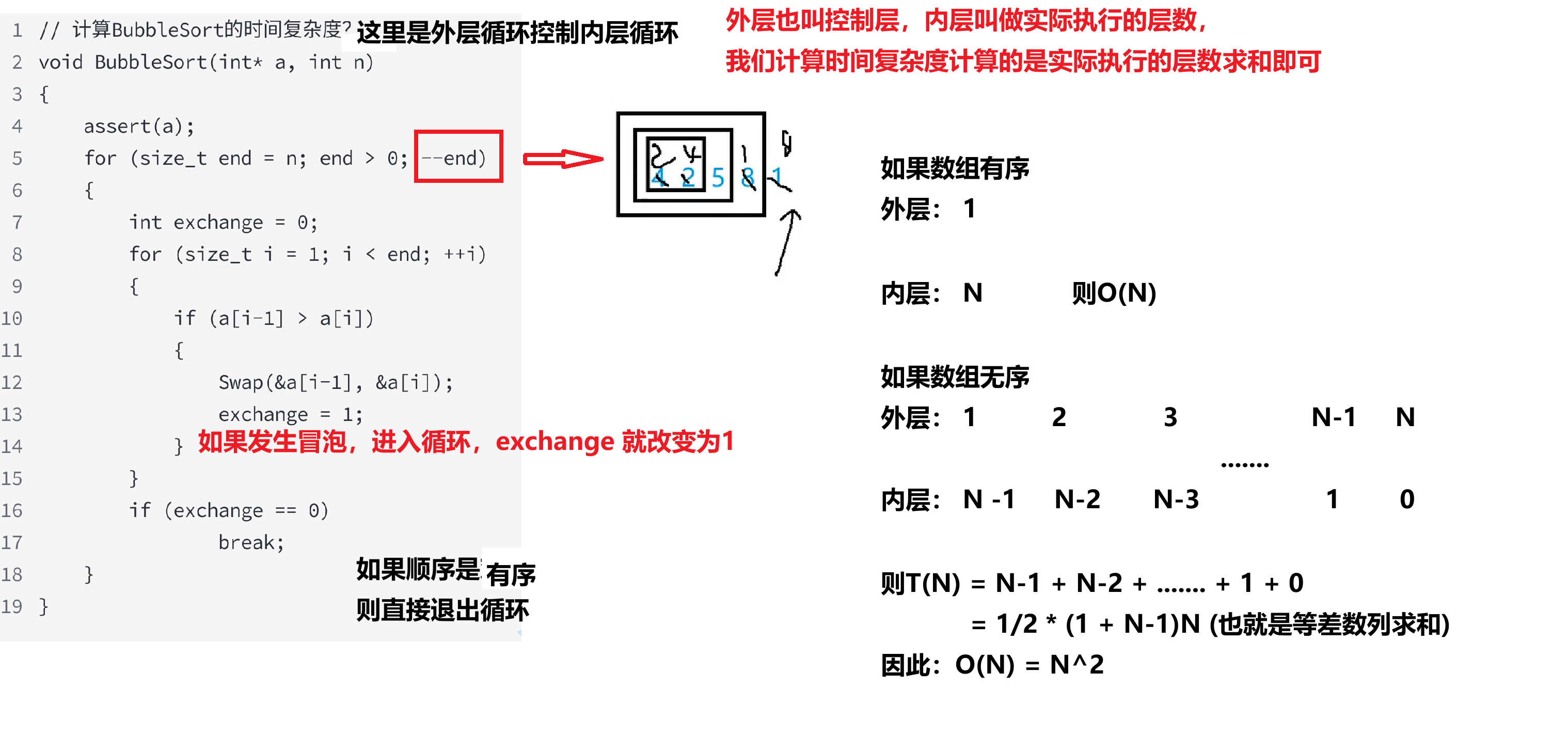
因此,我们取得是上界的情况:O(N^2)
再看看这道题,并说明他是如何计算时间复杂度的?

在计算机中,这里log的底数不写有错吗?说说其原因?
课件中和书籍中 log2 n 、 log n 、 lg n 的表示
当n接近无穷⼤时,底数的大小对结果影响不大。因此,⼀般情况下不管底数是多少都可以省略不 写,即可以表示为 log n
不同书籍的表示方式不同,以上写法差别不大,我们建议使用 log n
还有一个原因是:键盘中敲不出底数
说说递归函数的时间复杂度是如何进行计算的
到这里时间复杂度的计算就够够用了
空间复杂度的理解
空间复杂度是如何计算的?在代码中哪些是符合它的计算要求的
空间复杂度计算规则基本跟时间复杂度类似,也使用大O渐进表示法。
我们计算空间复杂度时只计算函数运行时所需要的栈空间。
在函数中创建变量时存储的参数、定义的局部变量、⼀些寄存器信息(函数开始执行时,需要知道“自己是被谁调用的”,以及执行完后要回到哪里继续执行。)和非递归函数调用的栈帧等都是在函数运行时的内容。
因此,空间复杂度主要通过函数在运行时候显式申请的额外空间来确定,也就是函数定义的下面那一部分
以下是常见的空间复杂度的计算,说说他们是如何计算的?


通过动态内存申请内容也会涉及到空间复杂度的计算
例如:

常见复杂度对比:
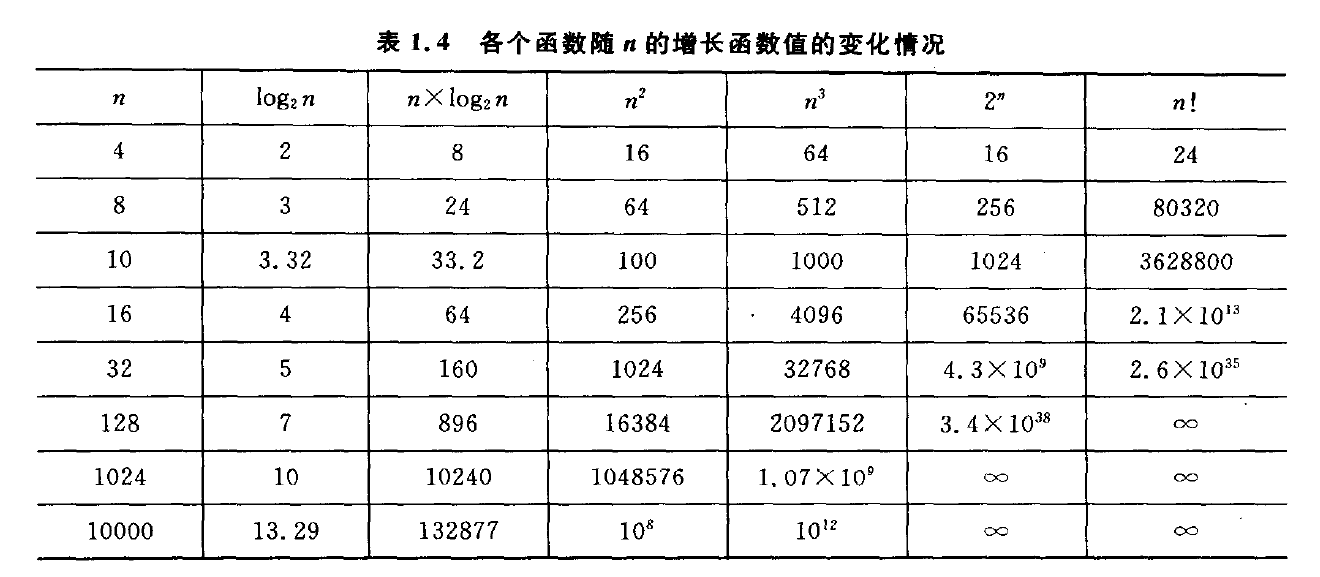
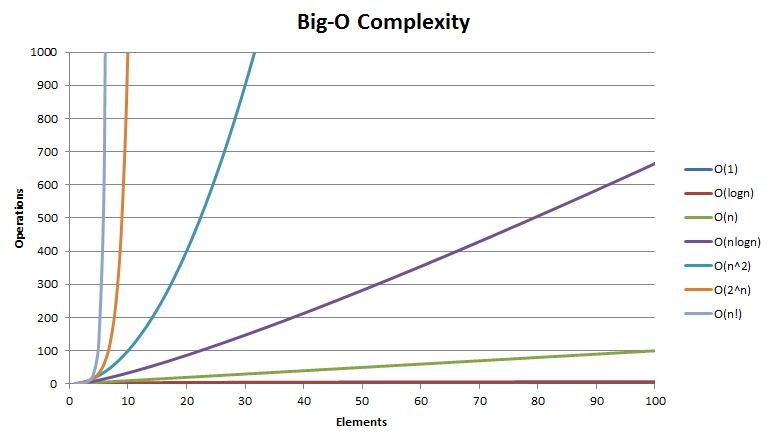
在上图中,说说各种复杂的的变化趋势,什么样的算法效率高,什么样的算法效率低?
随着n的增加,各种的复杂度的变化趋势也大不相同;随着n的增加,变化越缓的复杂度代表着在程序运行时的效率高;越陡的效率低
关于复杂度的相关算法题:
思路1:
时间复杂度 O(n^2)
循环K次将数组所有元素向后移动⼀位(代码不通过)

核心代码如下:
void rotate(int* nums, int numsSize, int k) {
while(k--)//直到轮转结束后就停止
{
int end = nums[numsSize-1];
for(int i = numsSize - 1; i > 0; i--)//这里是整体向后移的操作,起始位置在最后一位,直到将第一个数据移到第二位后就结束
{
nums[i] = nums[i - 1];//将一位的数据移到后一位
}
nums[0] = end;//将最后的移到第一位
}
}
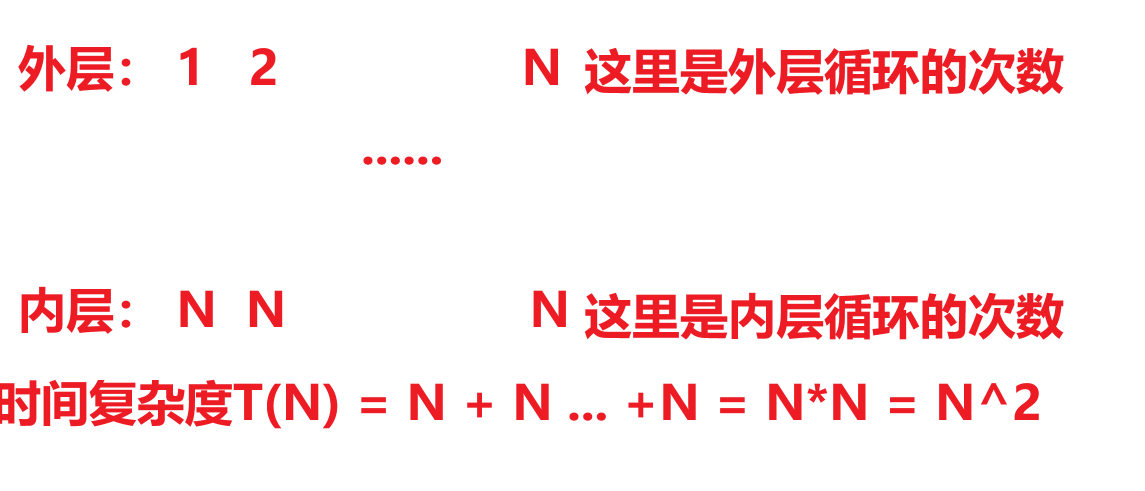
思路2:
空间复杂度 O(n)
申请新数组空间,先将后k个数据放到新数组中,再将剩下的数据挪到新数组中
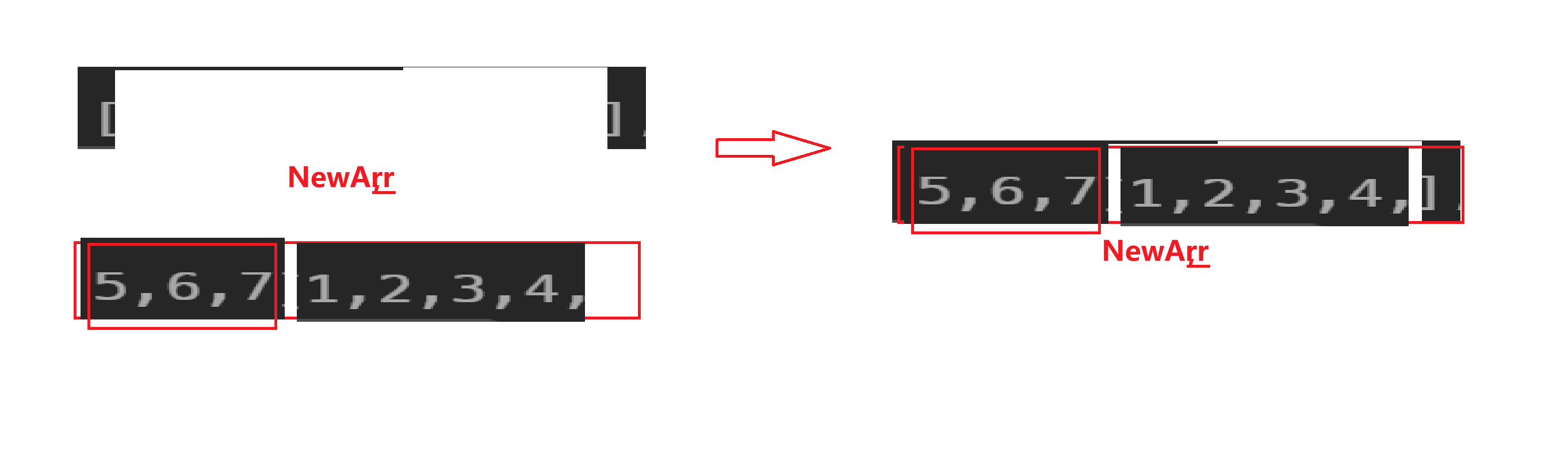
核心代码:
void rotate(int* nums, int numsSize, int k) {
int NewArr[numsSize];
for(int i = 0; i < numsSize; i++)
{
NewArr[(k + i) % numsSize] = nums[i];//这里是将原数组中的数据放入到新数组下标为(k + i) % numsSize中
}
for(int i = 0; i < numsSize; i++)
{
nums[i] = NewArr[i]; //再放到原数组中去
}
}
思路3:
逆置:是指将开始的位置(begin) 和末尾的位置(last)相互置换,多次置换时需要begin++,last- -。
空间复杂度 O(1)
先将前n-k个逆置:4 3 2 1 5 6 7
再将后k个逆置 :4 3 2 1 7 6 5
最后将整体逆置 :5 6 7 1 2 3 4
核心代码:
//逆置的过程可以分装成一个函数
void reverse(int* nums, int begin, int end)
{
while(begin < end)
{
int tmp = nums[begin];
nums[begin] = nums[end];
nums[end] = tmp;
begin++;
end--;
}
}
void rotate(int* nums, int numsSize, int k) {
k = k % numsSize;
//先将前n-k个进行逆置
reverse(nums, 0, numsSize - 1 - k);//这里传的是数组的下标
//再将后k个进行逆置
reverse(nums, numsSize - k, numsSize - 1);
//最后整体进行逆置
reverse(nums, 0, numsSize - 1);
}
假设数组的个数非常大,有n个,我们从头 和 尾 两两逆置,总共逆置了1/2 * n次,所以时间复杂度为O(N), 我们也没有额外申请空间,所以空间复杂度为O(1)

















 1252
1252




 到【灌水乐园】发言
到【灌水乐园】发言







