



文章信息
Published in: The Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI-23)
作者:Kartik Sharma,Samidha Verma,Sourav Medya,Arnab Bhattacharya,Sayan Ranu
核心思想
当前存在不足
虽然黑盒攻击不需要任何模型参数的信息,但它们在三方面做出了关键假设:
- 任务特定策略:大多数GNN模型是为特定任务(如节点分类)训练的,使用适当选择的损失函数。现有的对抗攻击技术根据已知的特定预测任务调整其策略,因此不能推广到未见的任务。因此本文提出一个问题:是否可以设计任务无关的对抗攻击?
- GNN模型的知识:尽管黑盒攻击不需要知道模型参数,但它们通常假定模型类型。例如,攻击可能针对GCN定制,如果受害模型切换到Locality-aware GNNs【You, Ying, and Leskovec 2019; Nishad et al. 2021】,则攻击可能无效。
- 依赖标签:一些BBA算法需要知道真实数据。例如,一个算法可能需要知道节点标签来对节点分类进行对抗攻击。这些真实数据通常在公共领域不可用。例如,Facebook可能根据用户的主要兴趣领域标记用户,但这些信息是专有的。
改进思路
本文针对的攻击为黑盒攻击,主要使用深度强化学习算法,对目标节点的领域进行扭曲(本文任务为Target Attack)
本思路基于一项观察结果:无论任务或模型类型如何,如果可以扭曲节点的邻域,下游预测任务就会受到影响。我们的分析表明,预算约束的邻域扭曲是NP难的。通过使用图同构网络(GIN)来嵌入邻域,并使用深度Q学习(DQN)来有效地探索这一组合空间,克服了这一计算瓶颈。
问题重述
给定一个 GNN 模型 ,其在图
上针对特定预测任务的性能用一个性能指标量化;其中
使用嵌入
和真实标签或分数 v 计算节点 v 的性能。总体性能
是对所有节点的性能进行某种聚合
。
一个对抗性攻击者希望通过执行 B 次边删除和添加来更改 G ,以最小化目标节点 t 的性能。我们假设攻击者可以访问节点子集 ,并且只能在
集合中的节点之间修改边。
TANDIS:Targeted Attack via Neighborhood DIStortion
攻击者无法访问和模型M的类型,因此本文引入一个代理模型
,如果修改后图使得
远远大于0,则认为两个图显著不同。本文
定义如下
,其中N(v)代表节点v的k阶邻居。
则问题可以被重述为:![]()
TANDIS的框架如图所示:
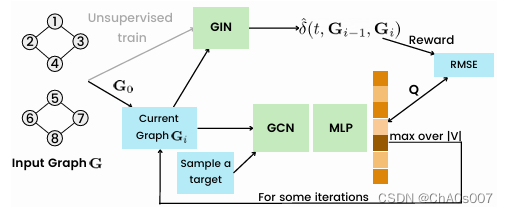
其核心就在于使用强化学习及GIN的嵌入使得两个图的表示尽可能不同。

















 664
664




 到【灌水乐园】发言
到【灌水乐园】发言







