




前言
说起Spark,大家就会自然而然地想到Flink,而且会不自觉地将这两种主流的大数据实时处理技术进行比较。然后最终得出结论:Flink实时性大于Spark。
的确,Flink中的数据计算是以事件为驱动的,所以来一条数据就会触发一次计算,而Spark基于数据集RDD计算,RDD最小生成间隔就是50毫秒,所以Spark就被定义为亚实时计算。
窗口Window
这里的RDD就是“天然的窗口”,我们将RDD生成的时间间隔设置成1min,那么这个RDD就可以理解为“1min窗口”。所以如果想要窗口计算,我还是首选Spark。
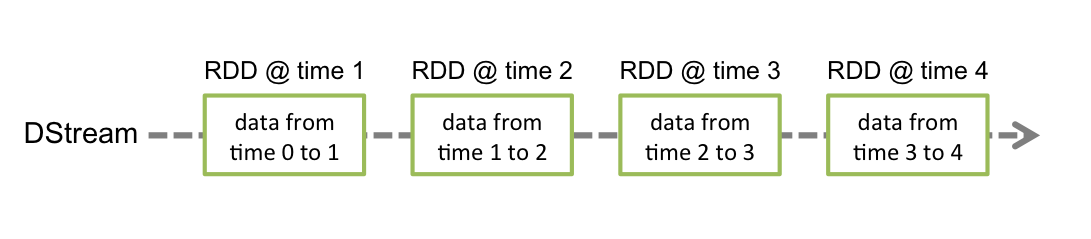
但当我们需要对即临近时间窗口进行计算时,就必须要借助滑动窗口的算子来实现。什么是临近时间?
例如“3分钟内”这种时间范围描述。这种时间范围的计算,需要计算历史的数据。例如1 ~ 3是3min,2 ~ 4也是3min,这里就重复使用了2和3的数据,依次类推,3 ~ 5也是3min,同样也重复使用了3和4。
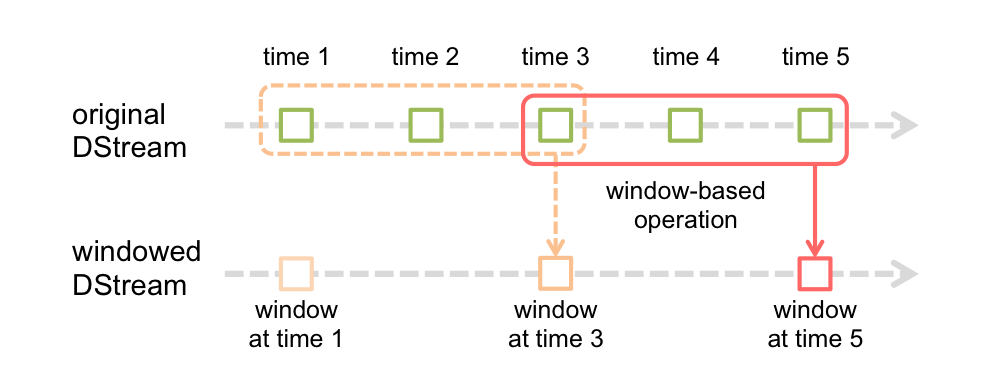
如果使用普通窗口,就无法满足“最近3分钟内”这种时间概念。
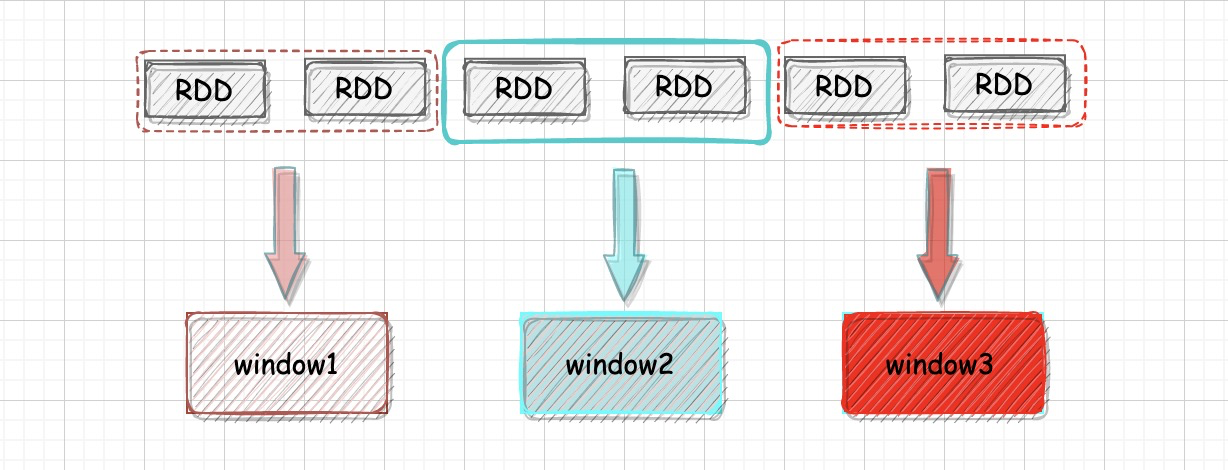
如下图所示,很多窗口都丢失了临近时间,例如第3个RDD的临近时间其实是第二个RDD,但是他们就没法在一起计算,这就是为什么不用普通窗口的原因。
滑动窗口
滑动窗口三要素:RDD的生成时间、窗口的长度、滑动的步长。
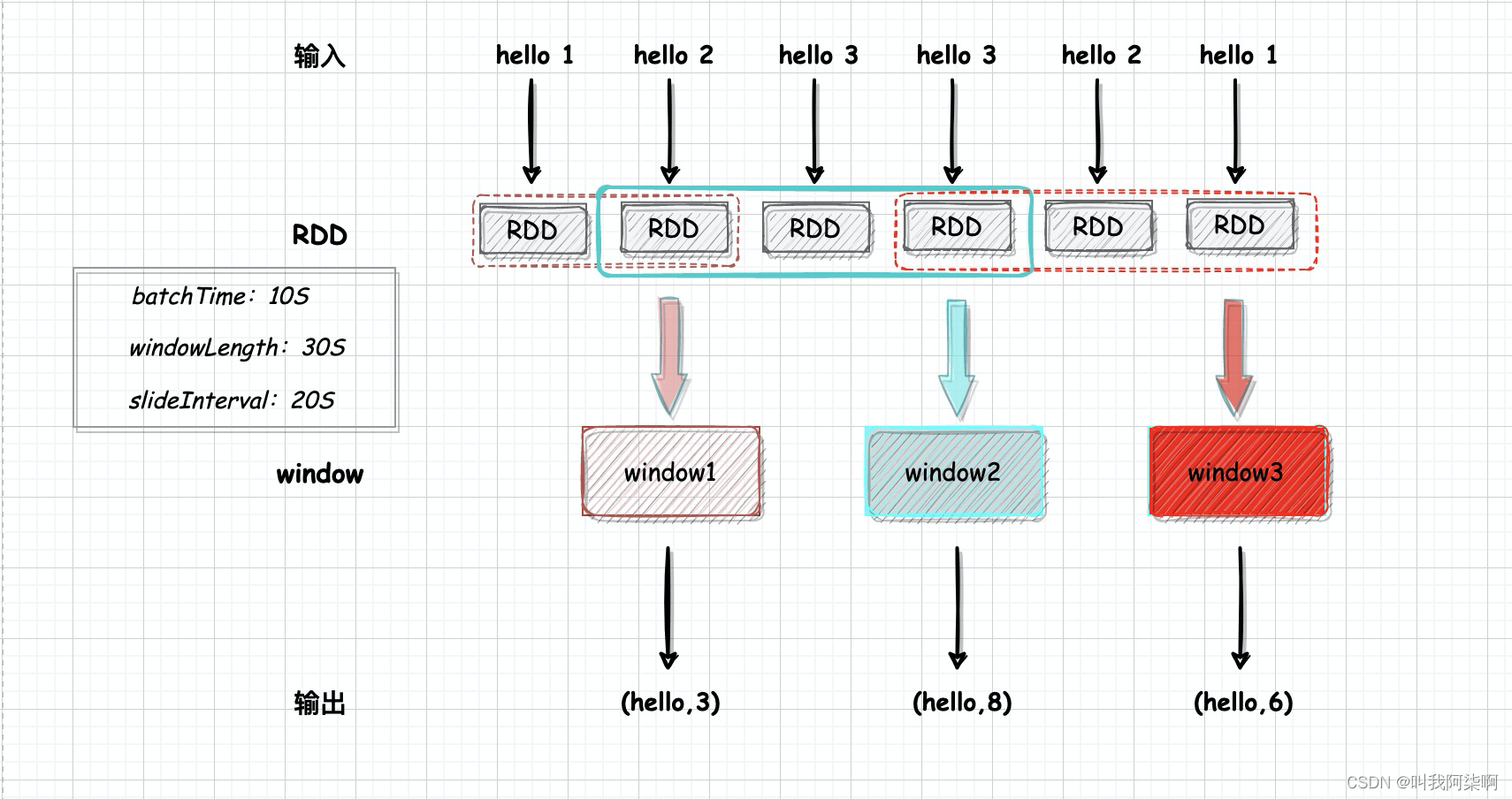
我在本次实践中,将RDD的时间间隔设置为10s,窗口长度为30s、滑动步长为10s。也就是说每10s就会生成一个窗口,计算最近30s内的数据,每个窗口由3个RDD组成。
数据源构建
1. 数据规范
假设我们采集了设备的指标信息,这里我们只关注吞吐量和响应时间,在采集之前定义数据字段和规范[throughput, response_time],这里都定义成int类型,响应时间单位这里定义成毫秒ms。
实际情况中,我们不可能只采集一台设备,如果我们想要得出每台或者每个种类设备的指标监控,就要在采集数据的时候对每个设备加上唯一ID或者TypeID。
我这里的想法是对每台设备的指标进行分析,所以我给每个设备都增加了一个唯一ID,最终字段[id, throughput, response_time],所以我们就按照这个数据格式,在SparkStreaming中构建数据源读取部分。
2. 读取kafka
val conf = new SparkConf().setAppName("aqi").setMaster("local[1]")
val ssc = new StreamingContext(conf, Seconds 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









