




 事务是数据库操作的基本单位,确保原子性、一致性、隔离性和持久性。ACID原则定义了事务的特性。文章讨论了不同隔离级别及其可能的问题,并提到了如何查看和设置事务隔离。索引用于提高查询效率,有多种类型如单一索引、复合索引等。视图提供了一种简化数据查询的方式,是数据库中的虚拟表。
事务是数据库操作的基本单位,确保原子性、一致性、隔离性和持久性。ACID原则定义了事务的特性。文章讨论了不同隔离级别及其可能的问题,并提到了如何查看和设置事务隔离。索引用于提高查询效率,有多种类型如单一索引、复合索引等。视图提供了一种简化数据查询的方式,是数据库中的虚拟表。
事务
事务是一个完整的业务单元
转账:A账户减去10000,B账户加上10000;这个过程只能一次执行,结果只能是成功,或是失败(如果是后者,应该回到原先的情况)。以上操作为完整的操作单元
-
只有DML语句才有事务的说法
只有
insertdeleteupdate与事务有关 -
正是由于做某件事时,需要多条DML语句共同联合起来才能完成,所以需要事务的存在
本质上,一个事务就是多条DML语句同时成功,或者同时失败
-
在事务的执行过程中,每一条DML的操作都会记录到“事务性活动的日志文件“中
我们可以提交事务,也可以回滚事务
-
提交事务将清空“事务性活动的日志文件“,将数据全部彻底持久化到数据库表中
-
提交事务标志着事务的结束,并且是全部成功的结束
-
回滚事务标志着事务的结束,并且是全部失败的结束
事务的使用
提交事务 commit
回滚事务 rollback
回滚只能回滚到上一次的提交点,MySQL执行一次则自动提交一次
-
如何关闭MySQL的自动提交机制?
start transaction; // 先使用这条语句 # DML语句,一个完整的事务 commit; // 提交事务,设置“存档点1” # 另一条DML语句 rollback; // 回到存档点1,只能回到上一次commit的提交点 -
事务的四个特性:ACID原则
Atomicity | Consistency | Isolation | Durability
A:原子性,事务是最小的工作单元,不可再分
C:一致性,同一个事务中,所有操作必须同时成功或者同时失败
I:隔离性,不同事务之间具有一定的隔离性
D:持久性,事务提交相当于将未保存的数据持久化到硬盘上
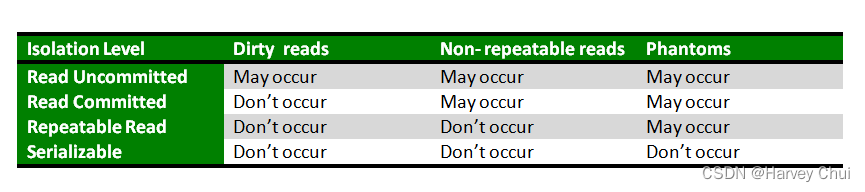
事务的隔离级别
从低到高共4个级别
-
读未提交,
read uncommitted事务A可以读取到事务B未提交的事务
可能存在脏读现象,一般不应用于实际编程中
-
读已提交,
read committed事务A只能读取事务B提交之后的事务
解决了脏读,但是不可重复读取数据:一个事务范围内两个相同的查询却返回了不同数据;Oracle默认
这种隔离级别每一次读到的数据绝对真实,提交之后才能读到
-
可重复读,
repeatable read事务A开启之后,只要A事务不结束,每一次在事务A中读取到的数据都是一致的,即使事务B将数据已经修改
这种隔离级别可能出现:永远读取的都是刚开启事务时的数据
-
序列化/串行化,
serializable最高隔离级别,解决了所有问题
表示事务排队,不能并发
每一次读取到的数据都是最真实的,并且效率是最低的
查看事务隔离级别
select @@transaction_isolation;
设置事务的隔离级别,以第三级为例
set global transaction isolation level repeatable read;
索引
索引在表的字段上添加,是为了提高查询效率
相当于一本书的目录,为了缩小扫描范围而存在的机制,索引类似,也是需要排序的
- 在任何数据库中,主键上都会自动添加索引对象;在MySQL中,一个字段如果有unique约束的话,也会自动创建索引对象
- 在任何数据库当中,任何一张表的任何一条记录在硬盘存储上都有一个硬盘的物理存储编号
- 在mysql当中,索引是一个单独的对象,不同的存储引擎以不同的形式:
- 在MyISAM存储引擎中,索引存储在一个.MYI文件中
- 在InnoDB存储引擎中索引存储在一个逻辑名称tablespace中
- 在MEMORY存储引擎当中索引被存储在内存当中
- 不管索引存储在哪里,索引在mysql当中都是一个树的形式存在。(自平衡二叉树:B-Tree)
- 什么条件下手动添加索引?
- 数据量庞大
- 该字段经常出现在where后面被查询
- 该字段很少出现DML操作(该操作后索引需要重新排序)
创建索引
# 给emp表的ename字段添加索引,起名为emp_ename
create index emp_ename index on emp(ename);
添加复合索引
create index emp_ename index on emp(ename, sal);
select 筛选左侧时为索引,筛选右侧时顺序查询
删除索引
drop index emp_ename index on emp;
如何查看索引情况
explain select * from emp where ename = 'Jason';
结果的rows字段显示了扫描行数,如果没有添加索引,则会按照顺序扫描所有记录;结果的type字段中,ref 为使用了索引,ALL 为按次序遍历
出现索引失效的几种情况:
- 在模糊查询的时候,“%”开始
- 使用
or时,任意一边没有索引的时候 - 复合索引没有使用左侧的索引
where语句后使用了函数或数学运算
索引是各类数据库优化的重要手段,也是优先考虑的因素
索引分为以下类:
- 单一索引:一个字段上添加索引
- 复合索引:两个字段或者更多字段上添加索引
- 主键索引:主键上添加索引
- 唯一性索引:具有unique约束的字段上添加索引
注意:唯一性较弱的字段上添加索引的用处不大
视图
视图(view)是站在不同的角度去看待同一份数据
只有DQL语句才能以 view 的形式创建
创建一个视图对象
create view
emp_dept_view
as
select
e.ename,e.sal,d.dname
from
emp e
join
dept d
on
e.deptno = d.deptno;
删除一个视图对象
drop view dept2_view;
可以面向视图对象进行增删改查,对视图对象的增删改查会导致原表被操作
面向视图插入,原表将发生改变
insert into dept2_view(deptno,dname,loc) values(60,'SALES', 'BEIJING');
面向视图更新
update
emp_dept_view
set
sal = 1000
where
dname = 'ACCOUNTING';
视图可以用来简化SQL语句,可以把视图作为引用指向多条SQL语句,方便开发,易于维护;视图是持久化存储在硬盘上的,不会消失
Tip:CRUD 增删改查
C:Create 增 | R:Retrive 查 | U:Update 改 | D:Delete 删
DBA常用命令
数据库的导入
create database bjpowernode;
use bjpowernode;
source D:\bjpowernode.sql;
数据库的导出
mysqldump bjpowernode>D:\bjpowernode.sql -uroot -p123456
也可以导出数据库的指定表
mysqldump bjpowernode emp>D:\bjpowernode.sql -uroot -p123456

















 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









