




【时间】2018.11.25
【题目】使用python统计文件夹以及子文件夹中的文件数目
概述
使用python统计文件夹以及子文件夹中的文件数目,并将结果写入txt文件中。只统计有文件的文件夹,空文件夹直接跳过。
【代码】:
import os
from progressbar import ProgressBar
path ='F:\\test\\devel'
original_images =[]
#walk direction
for root, dirs, filenames in os.walk(path):
for filename in filenames:
original_images.append(os.path.join(root, filename))
original_images = sorted(original_images)
print('num:',len(original_images))
f = open('tongji_files.txt','w+')
error_images =[]
progress = ProgressBar()
current_dirname =os.path.dirname(original_images[0])
file_num =0
for filename in progress(original_images):
dirname = os.path.dirname(filename)
if dirname != current_dirname or filename == original_images[-1]:
if filename == original_images[-1]:
file_num += 1
f.write('%s:\t%d\n'%(current_dirname,file_num))
current_dirname = dirname
file_num = 1
else:
file_num +=1
f.seek(0)
for s in f:
print(s)
f.close()
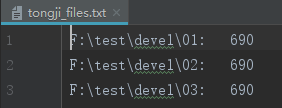
【运行结果】:

txt文件:


















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









