



作者 | Feynman 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1979144898872627828
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
简单版
GAIA-3是一个强有力的测试工具。
GAIA-3可以:
修改自车轨迹
修改天气/白夜
针对一段已有车载多视图视频
适配不同传感器配置(比如摄像头安装位置不一样);
根据少量案例(比如突然刹车),生成相同问题的新场景
GAIA-3 是一个15B的基于Latent Diffusion的模型,其video tokenizer是比GAIA-2的两倍
思考:
GAIA-3的实现方法到底是什么?
从功能上分析,现在学术界(应该也包括工业界)大部分采用基于3DGS重建的方法,比如ReconDreamer系列
但文章还是明说使用Latent Diffusion的方法,这个需要继续思考一下。
完整版:https://wayve.ai/thinking/gaia-3/
GAIA-3:规模化世界模型,驱动自动驾驶的安全与评测
将世界建模从一个视觉合成工具,转变为自动驾驶评估的基石。
大规模评估自动驾驶系统仍然是推进现实世界自动驾驶技术面临的核心挑战之一。现实世界测试对于验证安全性至关重要,但其成本高昂、受物流限制,并且数据效率日益低下。随着驾驶模型的改进和可观测错误的减少,得出具有统计学意义的结论所需的测试里程数急剧增加。而这些里程中的大部分都是平淡无奇的,几乎无法提供关于罕见但至关重要的安全行为的有效信息。
仿真模拟提供了一条前进的道路。虚拟环境能够实现安全、可靠、可重复且可扩展的驾驶模型测试。然而,尽管前景广阔,现有的仿真方法仍不足以对现代端到端驾驶系统进行有意义的评估。长期以来作为自动驾驶测试标准的程序化仿真器,允许精确控制但缺乏真实性。基于3D重建的仿真器实现了更高的真实感,但在处理遮挡和动态交通参与者方面存在困难。我们在世界模型方面的最新进展,结合了两者的优点:既捕捉了真实环境的静态和动态特性,又能生成逼真的反事实场景,从而扩展了现实世界测试的覆盖范围。



GAIA-3:将世界建模用于安全与评估
Wayve 一直率先使用世界模型,以开启自动驾驶汽车训练和评估的新范式。基于我们在未来预测、驾驶“梦境”生成、鸟瞰图预测以及学习世界模型方面的研究,我们推出了 GAIA-1(用于自动驾驶的生成式人工智能),这是我们迈向这一愿景的第一步。GAIA-1 证明了生成模型可以从视频、文本和动作中学习,以产生逼真的驾驶体验。GAIA-2 则通过引入更丰富的可控性、更广泛的地理覆盖范围以及通过多摄像头、时空连贯的场景生成实现多样化的车辆“化身”,进一步扩展了视野。
凭借 GAIA-3,我们迈出了大胆的一步:将世界建模从一个视觉合成工具,转变为自动驾驶评估的基石。GAIA-3 生成的驾驶场景不仅逼真,而且结构化和有目的性——旨在测量、比较并加速实现安全、可扩展的自动驾驶。
GAIA-3 结合了真实世界数据的真实感与仿真的可控性。它允许我们获取真实的驾驶序列,并通过精确、参数化的变体重现这些序列——例如,在场景中所有其他元素保持完全一致的同时,改变自车的轨迹。其他交通参与者保持其运动状态,光照和天气不变,整个世界保持连贯。这种以“世界在轨”方式运行的能力,是生成式世界建模向前迈出的重要一步,它将评估从反应式测量转变为主动探索决定安全性的边缘案例。
安全性关键场景
现实世界中的安全性关键事件——碰撞、险情或失控情况——是罕见的、不可预测的,并且过于危险而无法有意重现。目前,行业仍然依赖受控的测试场实验,例如使用预设角色和假人车辆的 NCAP(新车评估规程)测试。这些设置提供了精度,但牺牲了真实感和可扩展性。它们无法捕捉现实世界驾驶的视觉丰富性、行为多样性和环境复杂性。因此,测试场实验只能构成解决方案的一部分,并且可能导致对现实世界安全性能的认知不完整。
GAIA-3 通过对真实世界驾驶序列进行受控且逼真的变体生成,克服了这些限制。给定一个现有场景,GAIA-3 可以在保持环境其他部分一致的同时改变自车的轨迹;其他交通参与者继续其原有运动,静态元素保持不变。这使得生成碰撞和接近碰撞场景的系统化生成成为可能,这些场景可以使用与现实世界数据相同的占用率和轨迹指标进行评估,为可扩展、可复现的安全验证铺平道路。
这种方法也可以用于虚拟地、大规模地生成 NCAP 风格的测试,既可以在模拟的测试场环境中,也可以在不同的现实世界条件下进行。虽然车辆轨迹和时间保持一致,但背景、光照和场景动态会发生变化。
安全关键场景生成的一个关键基准是一致性——确保当仅自车行为改变时,场景的其余部分在物理上和视觉上保持连贯。为了验证这一点,我们使用激光雷达捕捉的真实世界序列,并修改自车轨迹以产生与场景物体的碰撞。然后,我们将原始记录的激光雷达点云与生成的帧进行对齐,并检查错位和不一致之处。
离线评估套件
现实世界驾驶很少遵循脚本。诸如突然停车、延迟并线或行人走上道路等意外事件,揭示了模型对其环境的真正理解程度。离线重现和测试这些“假设”时刻的能力对于建立对自动驾驶系统的信心至关重要。通过 GAIA-3,这可以系统地完成。
通过动作条件控制自车行为,并可选地结合“世界在轨”扰动,GAIA-3 可以生成真实世界场景的受控变体。从单个记录序列开始,通过调整不同参数,可以创建一整套“假设”情景。这些扰动允许对模型从边缘案例中恢复的能力或在变化条件下保持稳定性的能力进行定量测试。
其结果就是结构化、可扩展、可重复且可测量的离线评估测试套件。它们比静态回放提供更丰富的诊断信号,揭示了当条件改变时驾驶策略行为如何变化。GAIA-3 的合成干预与道路实验之间的相关性研究表明,该模型能够可靠地预测相关策略性能,从而提升了离线评估在模型比较和决策中的实用价值。
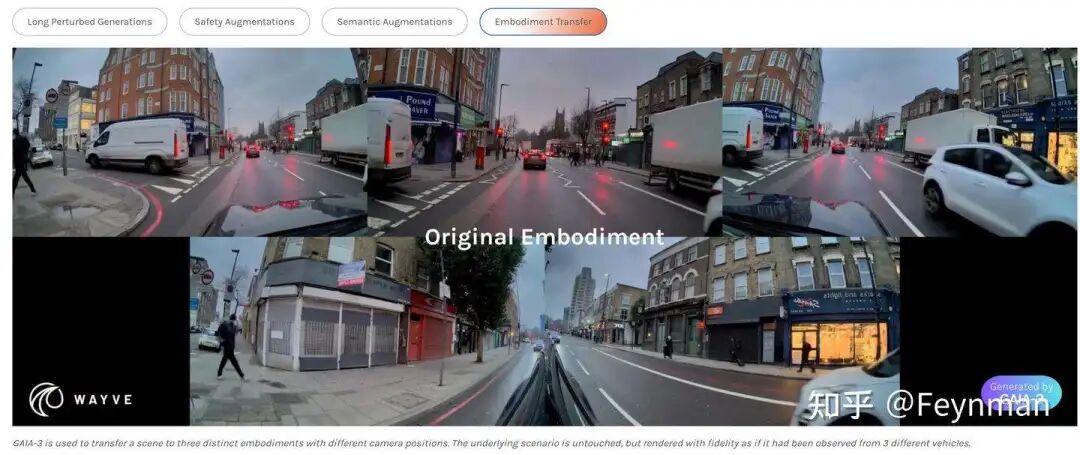
化身迁移
不同的摄像头配置和视场使得跨车辆重用数据具有挑战性。通过化身迁移,GAIA-3 可以从新的传感器配置重新渲染同一场景,只需使用目标摄像头配置的一个小型、非配对样本即可。
这意味着评估套件可以轻松地在不同的“化身”或不同汽车制造商(OEM)的车辆项目之间迁移,而无需进行配对采集。以下示例展示了 GAIA-3 如何将场景从一个摄像头配置迁移到另一个。
原始化身:原始视频由一辆配备 5 个 RGB 摄像头的车辆采集,其中一个直视前方,两个看向侧面,另外两个看向后方。
化身 A:这辆车是与原始化身不同品牌和型号的车辆,但具有类似的 5 摄像头配置。主要区别包括:遮挡前向摄像头视野的仪表板、在左右前向摄像头中显得更扁平更短的引擎盖,以及更明显的挡风玻璃。GAIA-3 令人信服地再现了来自场景的反射,包括来自对向车辆的反射。
鲁棒性与可解释控制
驾驶模型在面对外观、光照或语义变化时必须保持可靠。然而,这些变化必须是可测量的,以确保有意义的评估。
我们引入了受控的视觉多样性,允许场景的外观发生变化,而其底层结构保持不变。这意味着光照、纹理和天气等元素可以变化,但场景的几何结构和运动保持一致。因此,我们可以直接比较模型在不同视觉条件下的性能,大规模评估鲁棒性,并更好地理解特定的视觉变化如何影响模型行为。
数据丰富化与调试
罕见的故障模式在现实世界驾驶中难以捕获,这限制了数据覆盖范围并减缓了模型迭代速度。GAIA-3 可以从少量示例中学习,并围绕它们生成结构化变体,从而将诸如刹车或并线等场景家族扩展为丰富且物理一致的测试集。
这些罕见事件可以被放大成更大的、带有标签的测试套件,用于针对性测试或再训练,从而缩短发现问题与验证修复方案之间的时间。
以下示例展示了一种特定行为——急刹车,作为受控的分布外变体生成,有助于评估模型在难以通过现实世界测试重现的情况下的行为。相同的行为可以跨不同的环境和国家进行转换。例如,在美国的高速公路上刹车、在日本的市区环境中刹车,甚至是在给定交通灯处意外停车。
GAIA-3 可以帮助利用罕见的分布外示例来扩展数据集。在这里,GAIA-3 可以将一个特定的故障模式——在街道中央急刹车——转换到新的场景和地理环境中。
GAIA-3 的技术能力
世界模型的进步是由规模驱动的:不仅体现在参数数量上,还体现在数据多样性、表征能力和生成体验的质量上。
GAIA-3 是一个拥有 150 亿参数的基于潜在扩散的世界模型,专为自动驾驶的可扩展、逼真和可控的离线评估而设计。为了支持这种能力,GAIA-3 的训练计算量是 GAIA-2 的五倍,数据量大约是 GAIA-2 的两倍,覆盖了 3 大洲的 8 个国家。
数据集强调行人、骑行者、标志和交通控制基础设施等安全关键场景元素,确保模型不仅学习模仿驾驶场景,而且理解和再现与自动驾驶系统最相关的元素。
GAIA-3 带来了明显的改进,静态和动态场景元素的视觉效果更清晰。重要的是,它还展示了增强的世界建模能力,能够在长轨迹和临时遮挡时刻保持场景连贯性。
GAIA-2 与 GAIA-3 的对比
GAIA-3 在规模和能力上实现了显著飞跃,其模型大小相比前代 GAIA-2 增加了一倍,大大扩展了表征能力和生成精度。这个更广泛的基础使 GAIA-3 能够跨地域、“化身”和驾驶情境进行泛化,使其成为真正用于自动驾驶评估的全球性模型。
此次规模升级的核心是一个新的视频分词器,其大小是 GAIA-2 的两倍。它捕捉安全关键的空间和时间结构,从细微的行人运动到快速移动的车辆、道路标志和交通信号灯。通过编码细粒度的时空上下文,GAIA-3 比以往更忠实地表征了现实世界驾驶的物理和因果关系结构。该模型生成具有更高保真度的视频,视觉效果更清晰,光照更一致,纹理细节更丰富。
前方的道路
GAIA-3 通过在一个系统中实现可控性、增强的真实感和实用性,将世界建模精炼为一个用于评估和验证的实用框架。
其结果是一个支持结构化、可重复测试的模型,这是朝着可扩展地评估端到端驾驶系统迈出的重要一步。这些功能提供了一种可靠的方法,使用反映现实世界性能的指标来离线评估进展和比较模型。
我们继续专注于效率和实时生成,以及通过我们获得英国政府资助的 DriveSafeSim 项目对该工具进行验证。我们的目标是确立生成式仿真作为衡量进展和证明整个具身人工智能领域安全性的主要工具。
自动驾驶之心
世界模型与自动驾驶小班课!


















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









