



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Peizheng Li等
编辑 | 自动驾驶之心
VLA凭借其强大的泛化能力和语义理解能力逐渐成为端到端自动驾驶新范式。然而,现有的基于2D VLM的驾驶系统在处理精细的3D空间关系时存在显著缺陷,而这却是空间推理和轨迹规划的核心要求。
为此,奔驰与图宾根大学联合提出了一种名为SpaceDrive的具备空间意识的VLM自动驾驶框架。其核心在于摒弃了传统VLM将坐标数值视为文本token的处理方式,转而引入3D位置编码(Positional Encoding, PE)作为通用的空间表征。具体来说,SpaceDrive首先将视觉token与3D PE在特征空间进行显式融合,同时沿用上述通用的3D PE来取代prompt中对应坐标的文本token作为foundation model输入输出的接口。此外,SpaceDrive还采用回归解码器替代分类头预测规划的轨迹坐标,避免了语言模型在数字处理上的天然缺陷。实验表明,与现有VLM/VLA类方法相比,SpaceDrive在nuScenes开环评估中取得了SOTA性能,并在Bench2Drive闭环评估中以78.02的驾驶得分位列第二,显著提升了规划的几何精度与安全性 。
论文标题: SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous Driving
论文链接: https://arxiv.org/abs/2512.10719
项目主页: https://zhenghao2519.github.io/SpaceDrive_Page/
作者机构: Mercedes-Benz AG,University of Tübingen,Tübingen AI Center,TU Munich,Karlsruhe Institute of Technology,University of Stuttgart,UCLA
核心要点
当前VLM在自动驾驶应用中面临两个根本性的系统缺陷,这限制了其作为通用驾驶Agent的上限 :
2D语义与3D几何的割裂:VLM主要在大规模2D图像-文本对上进行预训练,极度缺乏3D空间先验,导致场景描述模糊和空间推理能力存在缺陷。
数字 token 化的缺陷:语言模型中坐标通常被逐位拆解为字符或数字(例如将坐标"3.82"拆解为"3", ".", "8", "2"),其本质是token联合分布的拟合而非数值计算。它既忽略了数值的连续邻近结构(例如"3.72"比"3.12"接近"3.82"),也会把不同位的 token 重要性平均化(例如"3.82"中"3"和"2"的Loss权重相同),从机制上拉低了连续数值预测精度与稳定性。
而现有VLM-based planner常常忽略了上述问题,或直接采用特定的 embedding/queries 针对某个任务进行训练来预测坐标,难以被迁移到上游推理或者其他任务中。
但是,Transformer架构本身的位置编码已经具备了处理token间位置关系的能力,这可以被视为语义特征之间的空间关系。受此启发,SpaceDrive通过显式的、统一的3D位置编码替换文本数字token,将坐标的语言描述转换成可计算、可对齐、可被注意力直接使用的统一表示,从而提升了系统的空间推理和轨迹规划能力。
方法
SpaceDrive框架的核心在于统一的空间接口:
视觉侧:用冻结深度估计器得到每个 patch 的绝对深度,投影为 3D 坐标,再经 PE 编码后加到对应视觉 token 上,得到 spatial-aware visual tokens。
文本侧:在 tokenizer 后扫描文本中的坐标表达,将其数值解析出来,经同一个 PE 编码器得到空间 token,替换原来的数字 token 序列,并用特殊前缀指示符 ⟨IND⟩ 标记。
输出侧:语言头正常生成文本;当生成 ⟨IND⟩ 时,后续 hidden state 送入 PE decoder直接回归 3D/BEV 坐标,取代生成数字的逐位生成。
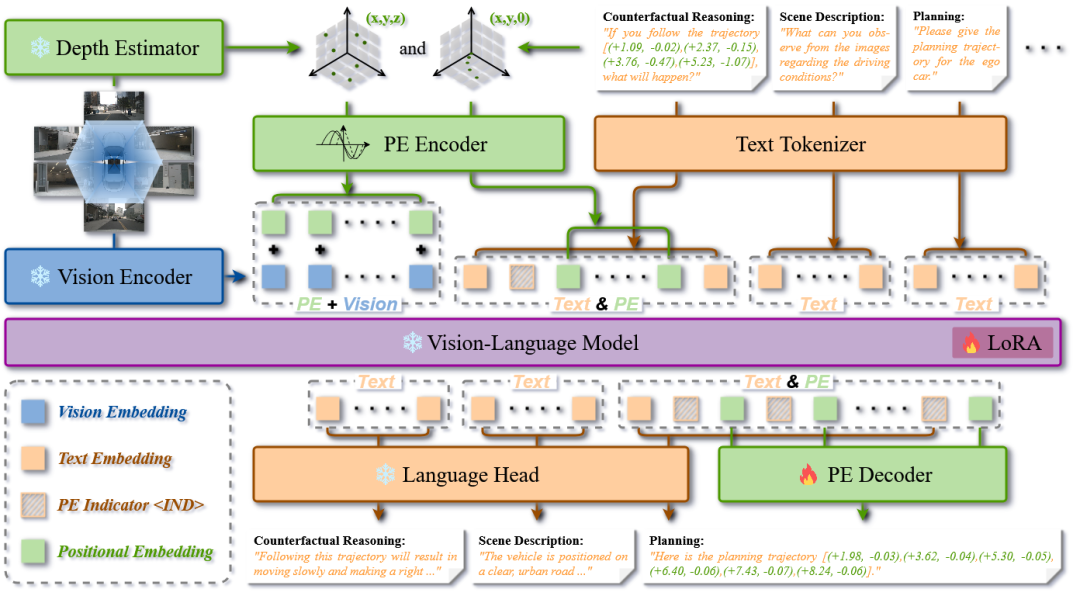
感知阶段:视觉与深度的显式融合
SpaceDrive在采用VLM预训练的视觉编码器提取视觉token的同时,利用冻结的深度估计器(如UniDepthV2)获取绝对深度,结合相机内外参将图像Patch中心投影至3D度量空间 。这些3D坐标会被一个通用的PE编码器被映射为与token维度相同的PE向量 。为了避免和原始VLM中的RoPE混淆,SpaceDrive采用了正余弦(Sine-cosine)编码作为PE编码器:
上述3D PE按 维分配通道。该3D PE随后被直接叠加到经过模态对齐的视觉Token 上,从而为VLM的视觉输入注入了绝对空间坐标信息:
考虑到Q-Former一类稀疏queries难以与具体 3D 位置密集对齐且需要额外对齐预训练,在SpaceDrive中视觉token通过MLP projector 与语言空间对齐。公式中的 是一个可学习的归一化因子,以避免 token norm 分布偏离预训练分布造成的训练不稳定。
空间信息检索:由于注意力是基于点积相似度的检索, 3D PE与视觉 token的叠加,相当于把空间位置变成可被注意力直接检索的键值结构。因此,后续文本中的坐标 PE 就能用相似度去索引对应空间位置上的语义特征,而非通过语言模型进行猜测。
推理阶段:统一坐标接口
当 3D 坐标出现在输入提示中时,对文本Prompt中的坐标子串 ,其数值 被提取并使用与上述相同的统一 PE 编码器 进行编码。这些编码后的3D PE会替换原本的数字 token 序列,并在前面插入特殊 token ⟨IND⟩ 避免语义混淆(对于 BEV 坐标这种特殊情况,例如轨迹航点,PE中的 轴分量会被置0,避免影响注意力计算)。
除了基本的prompt输入外,车辆的Ego Status也被证明对于轨迹规划非常有效。现有方法通常将所有状态变量(例如姿态、速度、加速度)简单地编码成一个单一的向量嵌入 。得益于统一空间表示,SpaceDrive同样可以通过之前使用的相同 编码历史Ego waypoints,并将其与 一起作为显式的时空条件输入到语言模型中,以实现精确的轨迹规划。
逻辑一致性:通过在视觉、文本Prompt、Ego waypoints中使用同一套PE,模型被要求学习统一的空间语义索引,而非针对不同模态学习割裂的映射。
输出阶段:回归优于分类
在输出生成时,当模型语言头预测 得到特殊指示符token ⟨IND⟩ 时,下一步的嵌入输出 将会被一个专用的 PE 解码器 解码为 3D 坐标:
考虑到 Sine-cosine PE 不可解析逆(相位/频率混叠),因此PE解码器被设为可学习的。该解码器既可以采用MLP以获得确定的坐标回归输出,也可以选择VAE等生成式模块从而获得多模式的输出。SpaceDrive默认采用一个轻量化的MLP作为PE解码器。
损失函数
对于坐标预测,SpaceDrive采用Huber Loss进行监督,相比L2或L1更能平衡异常值与收敛精度;文本部分SpaceDrive则保留了原有的交叉熵损失 :
实验及可视化
论文分别在nuScenes数据集和Bench2Drive 基准测试上对SpaceDrive以及带有Ego Status输入的SpaceDrive+进行了开环和闭环规划验证。实验中,框架以Qwen2.5-VL-7B为基础VLM,使用rank为16的LoRA对齐进行微调。冻结的预训练Unidepthv2-ViT-L被用作深度估计模块。开环规划中,模型预测未来3秒内的6个点作为输出,而闭环规划则是参照了SimLingo,同时输出path和speed waypoints,用于车辆PID控制。
开环规划 (nuScenes)
为了直接验证轨迹规划的准确性,论文首先进行了一次开环评估。在nuScenes数据集上,SpaceDrive+ 在所有指标上均超越了现有的OmniDrive/ORION 等 VLM-based 方法(Avg. L2 = 0.32m、Avg. Collision = 0.23%、Avg. Intersection = 1.27%)。
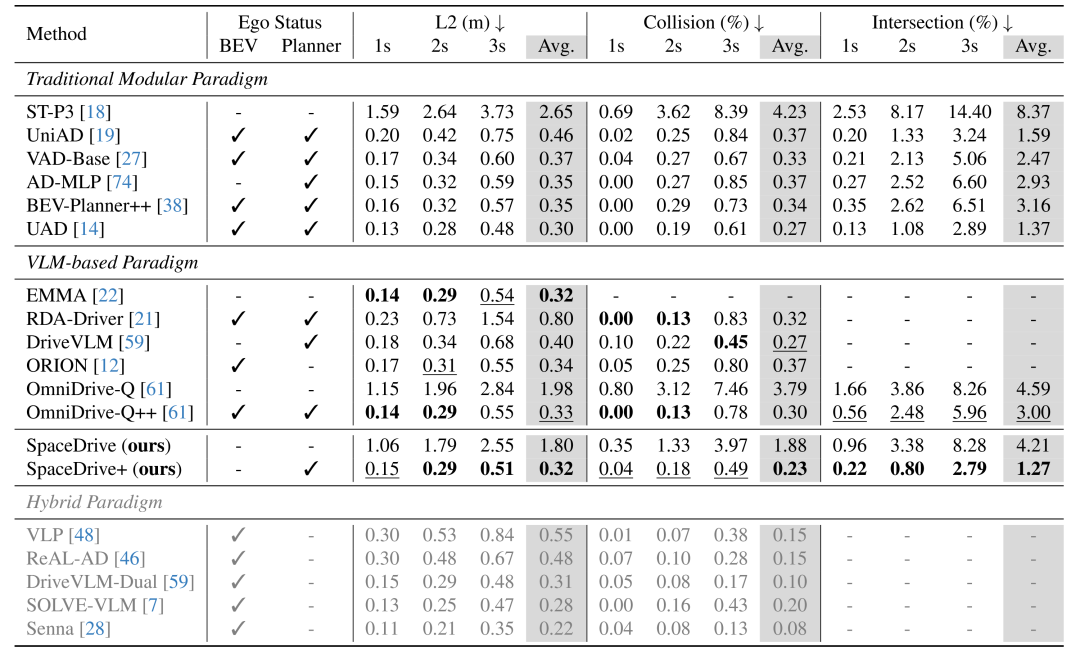
值得注意的是:SpaceDrive框架完全不依赖 BEV 特征。结果仍表明,统一位置编码接口足以支撑 VLM 内部的 3D 空间建模,从架构上减少对密集 BEV 表征的依赖。
闭环规划 (Bench2Drive)
考虑到基于相似度的开环规划评估极易受到数据集过拟合的影响,难以全面反映模型实际驾驶能力。论文进一步在闭环Bench2Drive基准测试中进一步验证了其方法的有效性。
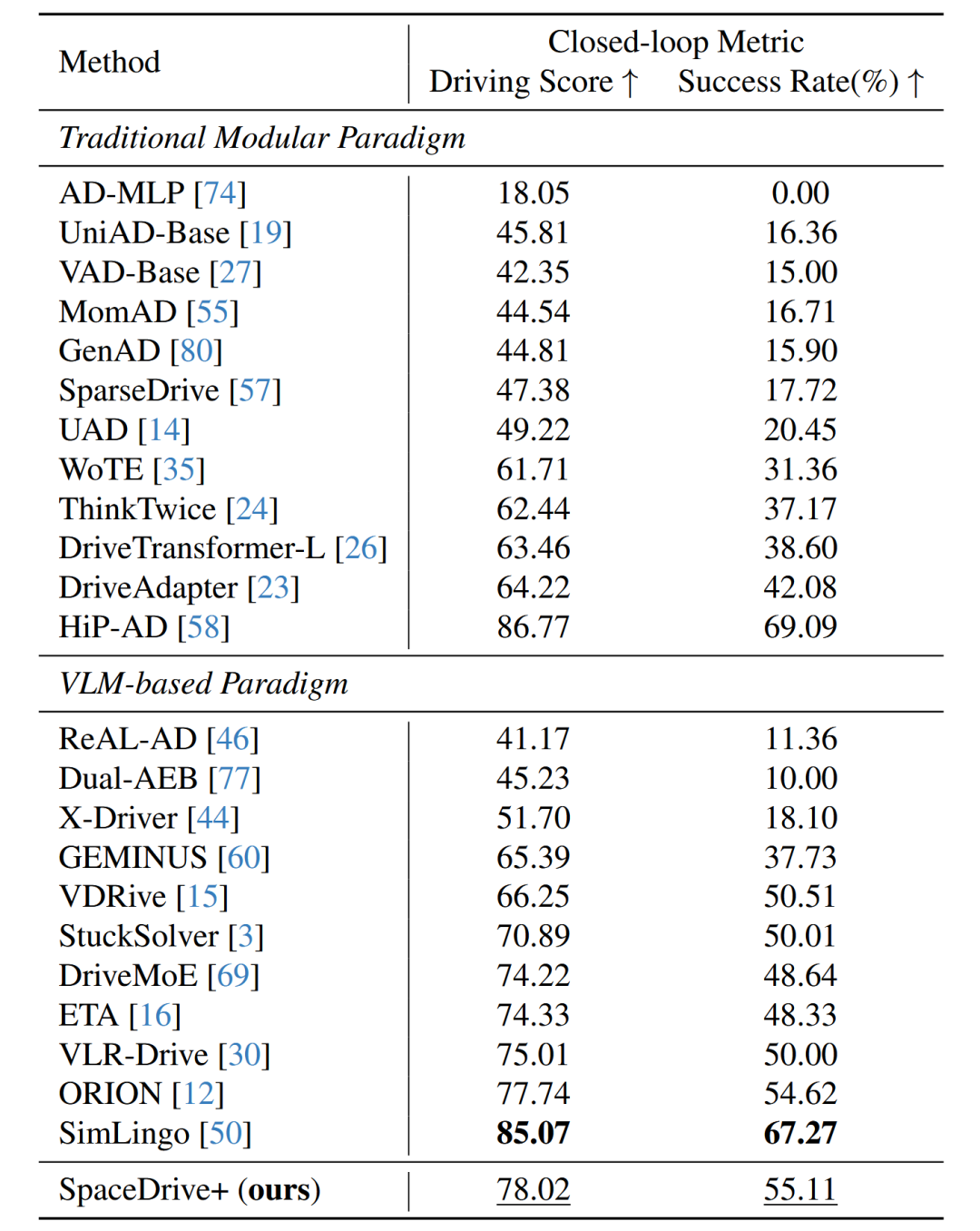
论文首先尝试了仅使用文本生成轨迹的方法,实验证明该方法在闭环里容易退化为近线性轨迹,且航向出现振荡,极不稳定。这是由于文本生成本质是在拟合数据先验而非学习可控策略。相比之下引入显式的通用空间 token 后,SpaceDrive+ 达到 78.02 Driving Score 与 55.11% Success Rate,在 VLM-based 方法中排名第二。
可视化
论文对比了同一场景下(变道避让骑行者)纯文本和引入空间token方法的实际表现:
纯文本方法输出的轨迹规划退化为一条直线,且行进方向不断震荡,最终导致车辆向左大幅偏转直至撞上护栏;

引入空间token的SpaceDrive+在观测到前方由缓慢的骑行者时,先试探加速寻找超车机会,发现邻车并未让行后减速创造安全插入间隙,再果断变道,并在变道完成前及时回正避免驶出道路。

消融实验
为了进一步验证通用的3D PE如何在规划中发挥作用,论文进行了诸多消融实验并得出了以下结论:
PE 注入位置很关键:仅把 PE 用在文本坐标替换而不注入视觉 token提升有限(因为此时PE无法对于对应位置视觉特征进行索引);而把 3D PE 注入视觉 token 带来显著增益;当统一的位置编码应用于视觉和文本坐标流时,无论是否使用自我状态,规划性能都会提高,这强调了共享空间表示的价值。
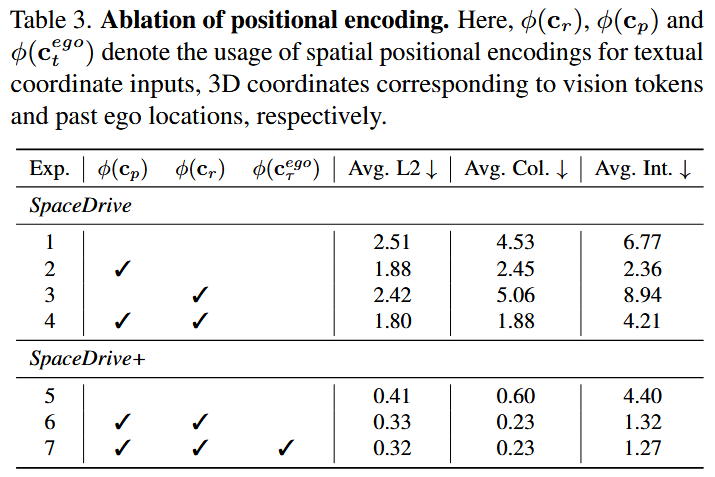
PE编码器/解码器选择十分重要:Sine-cosine 编码天然具备更好的平移等变性,有助于注意力机制理解 token 间空间关系,优于可学习的MLP encoder;RoPE 会与基座 VLM 的 RoPE 冲突导致输出出现语义不稳定;输出端直接反解sine-cosine 不适定,且 VLM 输出空间与输入嵌入空间不完全对齐,因此用可学习、逐坐标 waypoint 的 MLP decoder 更优。
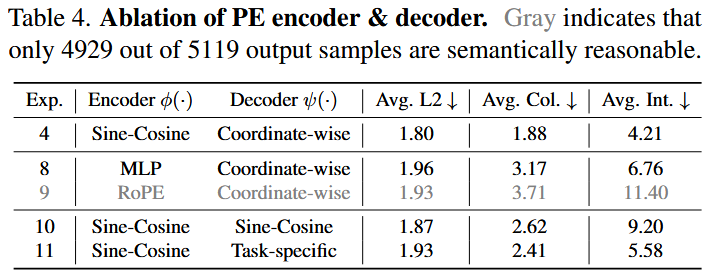
可学习的 十分重要:固定尺度的PE容易造成语义不稳定或收敛困难,而可学习 显著改善 L2误差、碰撞率和越界率。
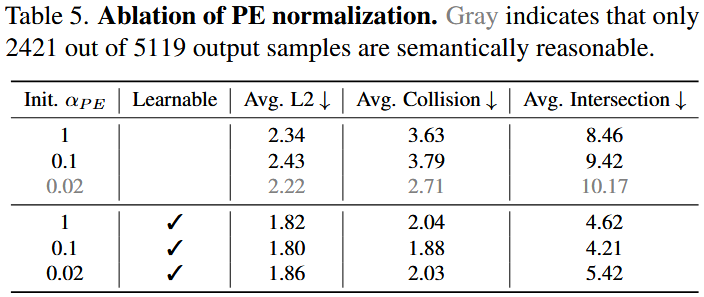
PE表征作为接口具备可迁移性:同一套PE空间接口在 Qwen-VL 与 LLaVA 上都能保持相近收益,说明增益主要来自统一空间推理接口而非特定基座模型的特殊适配。
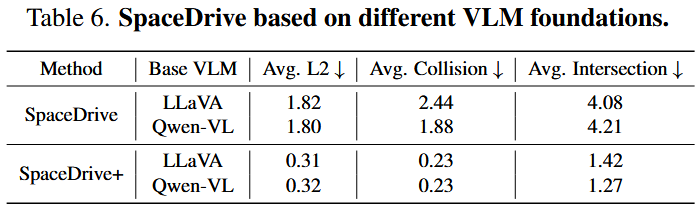
此外,论文补充材料还展示了更多有关于VQA任务,不同深度估计模型,不同超参数的相关实验,进一步证实了所提出方法的有效性。
结论
SpaceDrive 对当下自动驾驶和 VLM 研究做出了几项重要贡献:
通用空间表示:引入统一的 3D 位置编码,在感知、推理和规划模块中始终如一地工作,代表了一项重要的架构创新。这种方法超越了特定任务的嵌入,迈向了更具通用性的空间智能。
显式 3D 理解:将空间编码与视觉token进行加性整合,在语义内容和 3D 位置之间创建了显式关联,从而实现了更准确的场景理解和推理。
回归坐标数值本质:通过用基于回归的专用解码取代逐位坐标生成,SpaceDrive 解决了语言模型在处理连续数值量方面的根本限制。
框架通用性:该方法展示了与不同 VLM 架构(Qwen-VL、LLaVA)的兼容性,并证明适用于推理时增强功能,如思维链推理,表明其广泛适用性。
综上,SpaceDrive 提供了一个严谨的范式转换:从“语言建模几何”转向“显式几何编码”。其核心贡献在于证实了在VLM中,通过统一的、模态/任务无关的3D位置编码,可以有效连接感知的视觉空间与规划的物理空间。这种方法不仅解决了VLM在大规模空间推理任务中的幻觉和精度问题,还保留了VLM在长尾场景理解上的通用优势。SpaceDrive 代表了使 VLM 能够通过精确的空间理解有效与物理世界交互的重要一步,为更可靠、更有能力的 AI 智能体提供了发展方向。
更多可视化
自动驾驶之心
端到端与VLA自动驾驶小班课!


















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









