



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Minghui Hou等
编辑 | 自动驾驶之心
“只看图说话”的自动驾驶视觉模型,在真实路况中够用吗?遮挡、恶劣天气、复杂空间关系……这些挑战让传统模型捉襟见肘。今天要介绍的这项研究,正是要为自动驾驶系统打造一个更懂“场景”、更会“思考”的视觉语言模型——MMDrive。
论文标题:MMDrive: Interactive Scene Understanding Beyond Vision with Multi-representational Fusion
论文链接:https://arxiv.org/abs/2512.13177
作者单位:吉林大学,香港科技大学(广州),佐治亚理工学院,密歇根大学安娜堡分校
一、为什么传统方法不够用了?
目前主流的自动驾驶视觉语言模型(VLM),大多沿用“图像+文本”的双分支架构:视觉编码器提取图像特征,文本编码器理解问题,两者拼接后输入大语言模型生成答案。这种模式在简单场景中表现尚可,但面临三大瓶颈:
缺乏三维感知能力:二维图像难以表达深度、空间布局等关键信息;
语义融合能力有限:不同模态之间往往是“硬拼接”,未能实现语义对齐;
关键信息提取效率低:在复杂动态环境中,模型难以快速聚焦于重要区域。
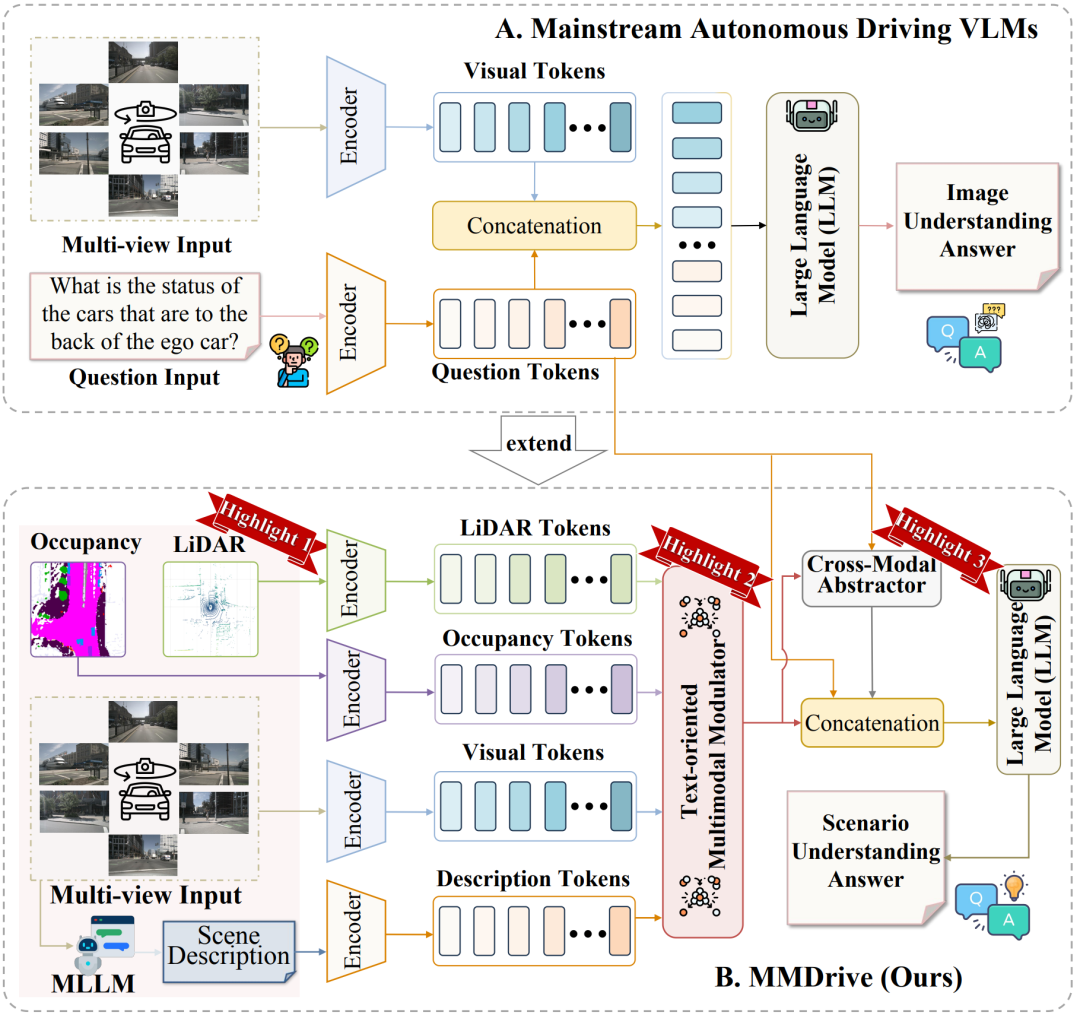
(A)主流的图像理解范式:通过编码器提取图像和文本特征,并通过投影进行组合,限制了跨模态交互。
(B) MMDrive:该框架包含占用、激光雷达和场景描述模态,将传统的图像理解范式扩展到整体场景理解。它还融合了TMM和CMA,以实现多模态信息融合,从而增强在复杂驾驶场景中的表征能力和适应性。
正如下图所示:前向摄像头被遮挡,仅凭图像无法准确判断后方车辆状态。这提醒我们:驾驶场景的理解,必须超越“平面视觉”,走向“立体感知”。

二、MMDrive 的三大核心突破
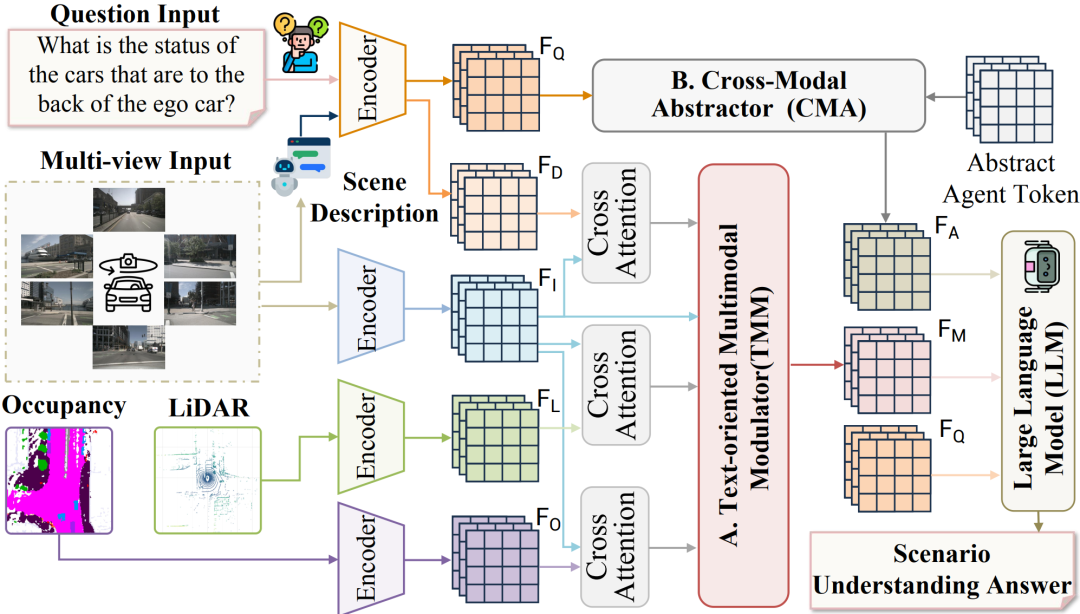
(1)该模型将多视角图像、文本问题、占用情况、激光雷达和场景描述作为输入。
(2)首先利用冻结编码器提取特定模态的特征。
(3)面向文本的多模态调制器(text -oriented Multimodal Modulator, TMM)根据文本问题的语义内容动态调整多模态信息的贡献,实现自适应的多模态融合。
(4)跨模态抽象器(Cross-Modal abstrator, CMA)通过提取关键信息进一步细化融合后的多模态表示。
(5)最后,将融合后的表示输入LLM以生成最终答案。
1. 多模态信息融合:从“图像理解”到“场景理解”
MMDrive 引入了三类互补信息源:
占据栅格地图(Occupancy):提供稠密的三维空间结构信息;
激光雷达点云(LiDAR):提供精确的几何与深度信息;
文本场景描述(Scene Description):通过两阶段生成策略,提炼出高层语义信息。
这三种模态分别对应 空间结构、几何细节、语义关系,共同构建出一个立体的场景表征。
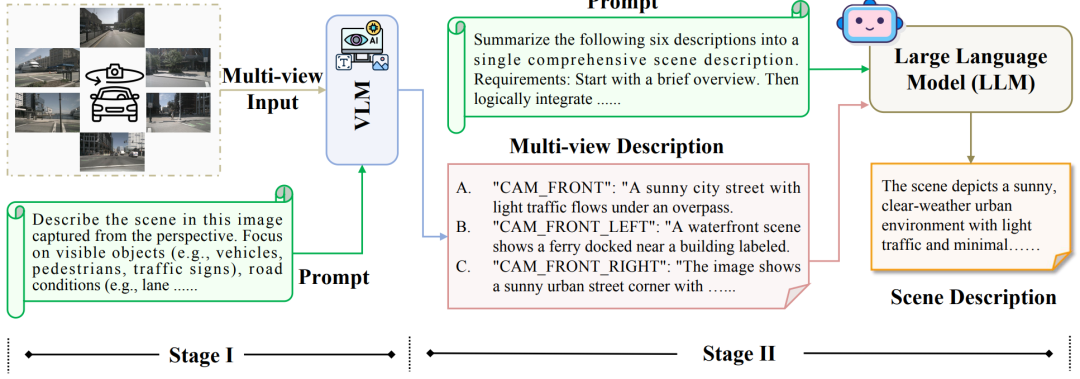
在第一阶段,将多视角图像和文本提示输入视觉-语言模型(Vision-Language Model, VLM)以生成相应的多视角描述;在第二阶段,将这些多视图描述与摘要提示一起输入到大型语言模型(LLM),以产生最终的场景描述。
2. 文本导向的多模态调制器(TMM)
不同问题关注的模态不同:
“后方车辆距离多远?” → 需要 LiDAR
“左侧是否有障碍物?” → 需要 Occupancy
“前方施工区域在做什么?” → 需要场景描述
TMM 能根据问题的语义,动态调整各模态的权重,实现问题感知的特征融合,避免信息稀释。
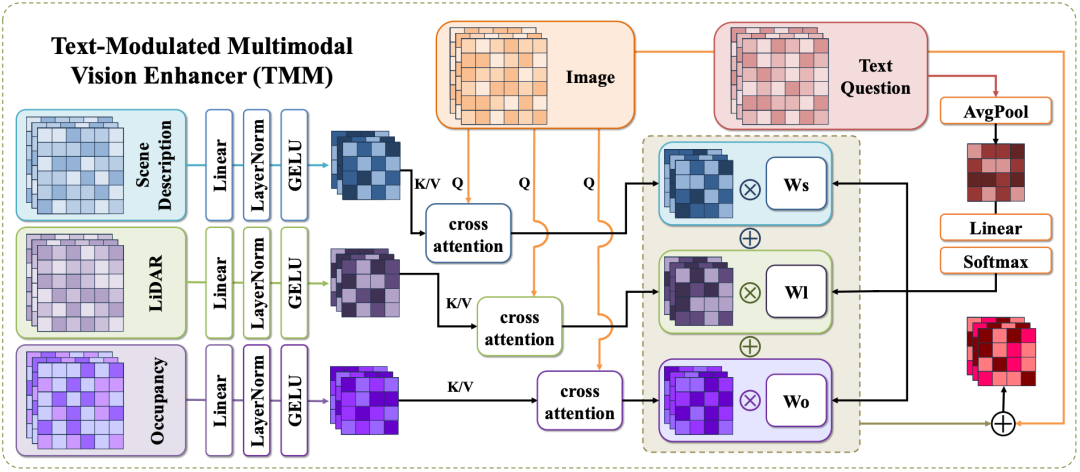
TMM通过将多模态特征投影到潜在空间,生成文本问题驱动的自适应融合权值,通过加权求和进行跨模态交叉注意,增强多模态场景表示能力,实现多模态融合。
3. 跨模态抽象器(CMA)
在复杂场景中,信息量巨大。CMA 通过学习一组“抽象令牌”,提取跨模态的关键信息,形成一个紧凑的语义摘要,让大语言模型能更高效地聚焦于核心内容。实验表明,16个抽象令牌是性能最佳配置,太少表达能力不足,太多则引入冗余。
三、实验结果:性能领先,鲁棒性强
在 DriveLM 和 NuScenes-QA 两个权威基准测试中,MMDrive 均表现优异:
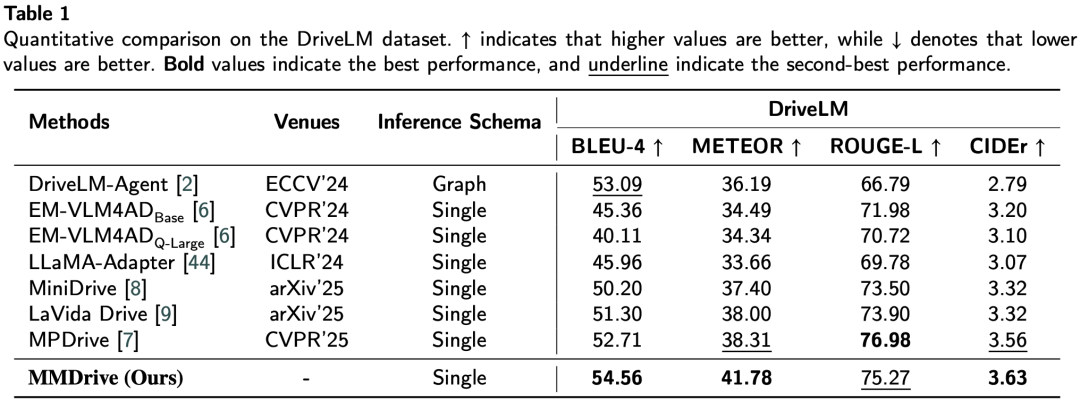
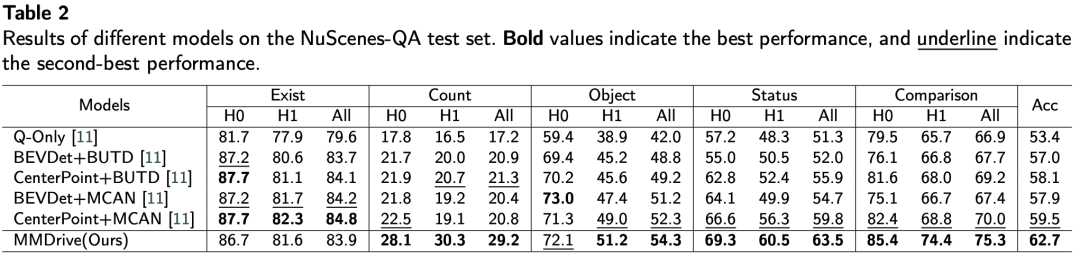
尤其在 计数、状态查询、比较类问题 上,MMDrive 优势明显,说明其在空间推理与语义理解方面更具优势。
定性实验 也显示:
在夜间、雨天等低能见度场景中,MMDrive 仍能保持较高判断准确率;
能识别出传统方法易忽略的细节(如与背景颜色相近的标志牌、远处的小型物体)。

左边的面板显示问题和相应的预测,而右边的面板显示六张环绕视图图像。MMDrive可以准确地检测物体,推荐安全行为,并预测不同视点的物体细节。

四、MMDrive 能用在哪些地方?
1. 自动驾驶系统的高阶感知模块
复杂路口理解、施工区识别、异常事件判断;
为预测与规划模块提供丰富的语义场景表示。
2. 驾驶仿真与测试平台
生成高质量的场景描述,用于测试系统的语义理解能力;
支持多模态问答,用于驾驶员行为分析与系统评估。
3. 智能交通与车路协同
通过车辆与路侧设备的多模态信息融合,提升全域交通态势感知;
支持自然语言交互的交通指挥与调度系统。
4. 驾驶教育与辅助系统
为驾考模拟、危险场景教学提供可解释的问答支持;
增强ADAS系统的交互能力,实现“语音问答+场景理解”的双重辅助。
五、未来展望:更轻、更强、更可解释
作者在文末也指出,后续研究将围绕:
长时序预测与协同规划:在时间维度上拓展多模态推理;
轻量化部署:让模型更适合车载嵌入式平台;
可解释决策生成:不仅给出答案,还能提供推理链条。
写在最后
MMDrive 不仅仅是一个技术框架的改进,更是一种范式转换:从“图像理解”迈向“场景理解”。它告诉我们,真正的自动驾驶系统,需要的不仅是“眼睛”,还要有“空间感”和“语义脑”。
或许在不远的将来,你的车子不仅能“看见”路,还能“理解”路上发生的一切,并像老司机一样,用自然语言告诉你:“前面施工,咱们慢慢走,右边那台车可能要变道。”
自动驾驶之心
端到端与VLA自动驾驶小班课!


















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









